Ataques Adversarios: ¿una debilidad de las Redes Neuronales?
En este post hablaremos en detalle de los ataques adversarios, una técnica que permitiría engañar a una Red Neuronal haciendo que funcione incorrectamente. Veremos en qué consisten estos ataques adversarios, cómo generarlos y cuáles son las estrategias existentes para combatir este problema.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
Observa detalladamente esta imagen:

¿Notas algo extraño? ¿se está moviendo la figura central? O ¿son las figuras externas las que se mueven? Pues no, ¡ninguna de las dos! Ambos objetos son estáticos, esto es simplemente una ilusión óptica, una imagen capaz de engañar a nuestros ojos y a nuestro cerebro, haciéndonos creer que los objetos se están moviendo.
Ahora prepara tus audífonos y escucha el siguiente audio:
¿No es extraño? Pareciera que el sonido proviniese de diferentes lugares del espacio. Pero realmente no, el sonido ha sido modificado para que llegue a nuestro oído izquierdo y derecho en diferentes instantes de tiempo, creando la ilusión de espacialidad.
Así que no sólo las imágenes, sino también los sonidos, pueden engañar a nuestro cerebro.
Pues bien, para el caso del Machine Learning también es posible crear “ilusiones” similares, capaces de engañar a cualquiera de estos modelos haciendolos “ver” cosas que realmente no existen.
En este post hablaremos en detalle de estas “ilusiones”, que se conocen como Ataques Adversarios.
Ataques Adversarios: una idea general
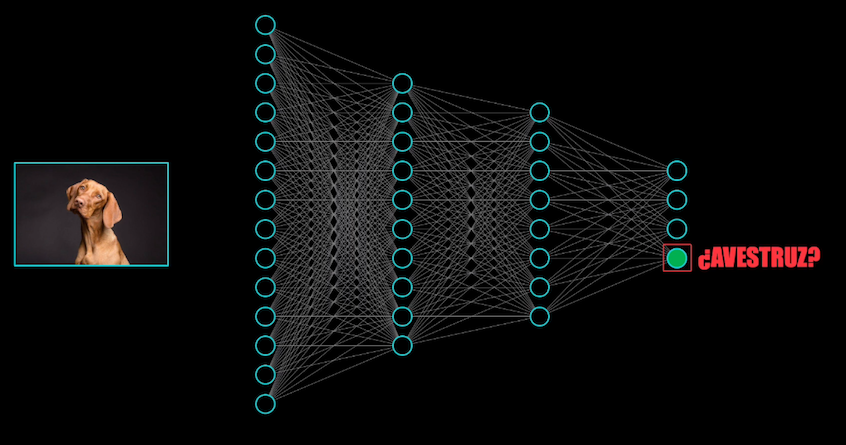
Por ejemplo, esta imagen de un perro es presentada a una Red Convolucional y la red la clasifica correctamente como un perro:

Pero si se modifica ligeramente, para nosotros los humanos sigue pareciendo un perro, ¡pero para la red resulta ser una avestruz!
Pero no solo eso, también es posible engañar a un clasificador de texto con sólo cambiar una letra. En este ejemplo en el texto original el clasificador clasifica la temática del texto como perteneciente a “Mundo”. Sin embargo, si se modifica tan sólo una letra de una palabra, el clasificador la etiqueta con el tema “Ciencia y Tecnología”:

Los anteriores son ejemplos reales de Ataques Adversarios, y los resultados que acabamos de ver son un poco contradictorios, pues en los últimos años hemos visto cómo diferentes modelos de Deep Learning progresivamente han alcanzado un desempeño que en muchos casos iguala o supera la capacidad del ser humano.
¿Entonces qué sucede? ¿No resulta extraño que lo que para nosotros parece un perro sea clasificado como una avestruz? ¿O que por simplemente cambiar una letra una red recurrente le dé una interpretación totalmente diferente al texto? ¿Son realmente tan prometedores estos sistemas si fácilmente pueden ser engañados?
Comencemos viendo en detalle qué es un Ataque Adversario.
Los Ataques Adversarios: explicación detallada
Un Ataque Adversario corresponde a una entrada al modelo que, de manera intencional, ha sido ligeramente modificada y que es capaz hacer que este modelo genere una salida incorrecta. ¡En últimas, un ataque adversario es como una ilusión óptica para un modelo de Machine o Deep Learning!

Ningún modelo de Machine o Deep Learning está exento de este tipo de ataques, y esto resulta preocupante si tenemos en cuenta que cada vez muchas tareas llevadas a cabo por humanos están siendo ejecutadas por Inteligencias Artificiales.
Imaginen por ejemplo un ataque a un vehículo autónomo: ¿qué pasa si logramos diseñar un ejemplo adversario que en lugar de una señal de PARE haga creer al sistema que no hay límite de velocidad?
O por ejemplo, ¿qué pasa si en una operación militar no tripulada (un dron) en lugar de una zona urbana se usa un ejemplo adversario que engañe al sistema y lo haga creer que se trata de una fábrica de armas?
Realmente no son problemas triviales, y resulta preocupante que este tipo de ataques aprovechen las posibles falencias de los sistemas de Inteligencia Artificial desarrollados en la actualidad.
Para analizar posibles alternativas de solución a este problema, debemos primero entender cómo es que se pueden crear estos tipos de ataques.
¿Cómo se puede crear un Ataque Adversario?
Para entender más en detalle el problema veamos cómo se pueden crear este tipo de ataques. Esencialmente existen dos formas: la manipulación de imágenes digitales y la manipulación de imágenes en el mundo real.
Manipulación de imágenes digitales
Existen muchas formas de manipular las imágenes digitales, pero tal vez la más conocida consiste en tomar la imagen y añadir una ligera perturbación, que a la vista parece ruido aleatorio pero que en realidad está diseñada para modificar la imagen de manera imperceptible, logrando a la vez generar una clasificación totalmente incorrecta por parte de la red.
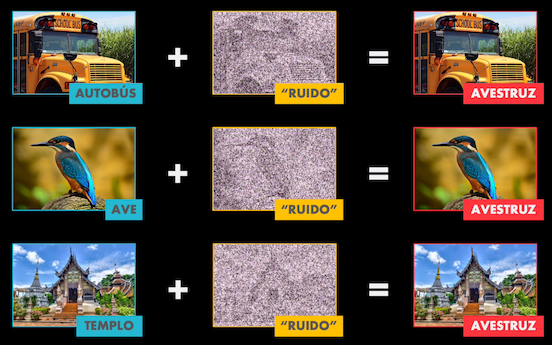
Así, lo que para nosotros parece ser un bus escolar, un ave o un templo, para la red termina siendo en todos los casos un avestruz.
Manipulación de imágenes en el mundo real
Sin embargo otros autores han encontrado que no es necesario ni siquiera manipular la imagen digital, pues desde el mismo momento de la captura es posible crear un ejemplo adversario.
Por ejemplo, es posible tomar la foto de un objeto, imprimirla y fotografiarla de nuevo, y presentar este resultado a una Red Convolucional, que resulta incapaz de clasificarla correctamente.

También es posible engañar por completo a un sistema de reconocimiento facial simplemente usando un par de gafas impresas en 3D!

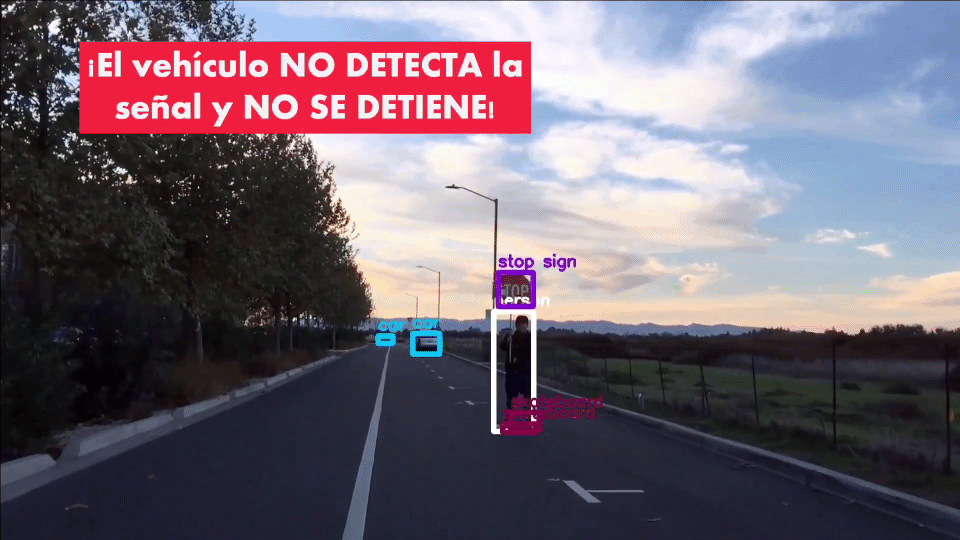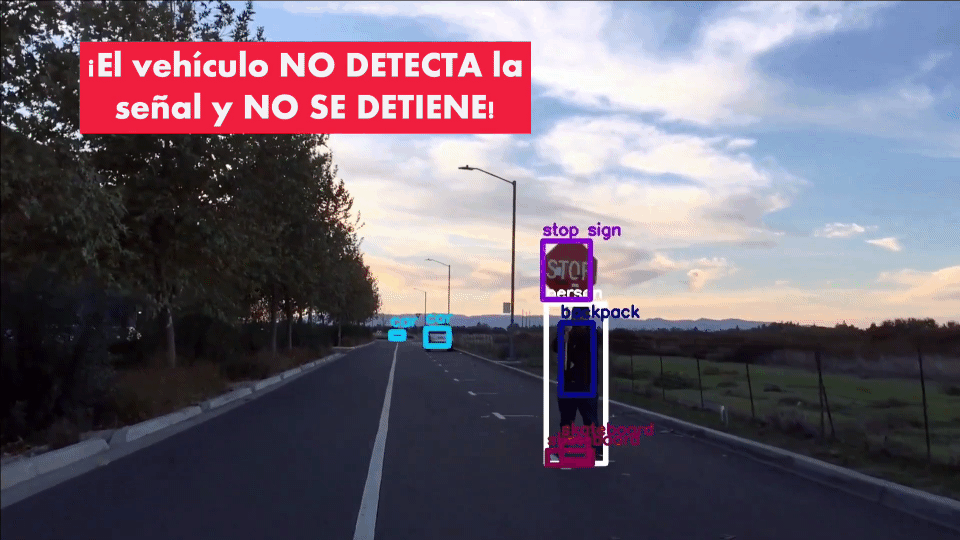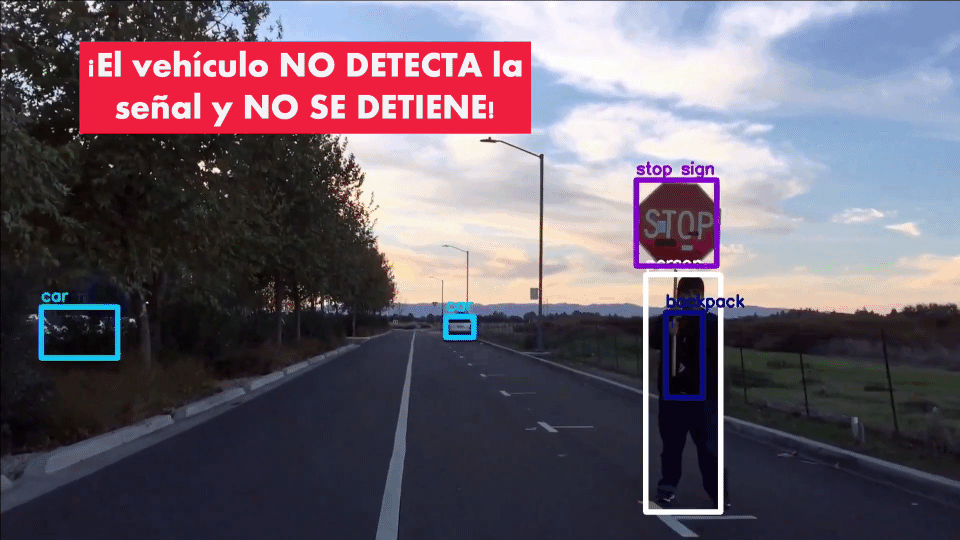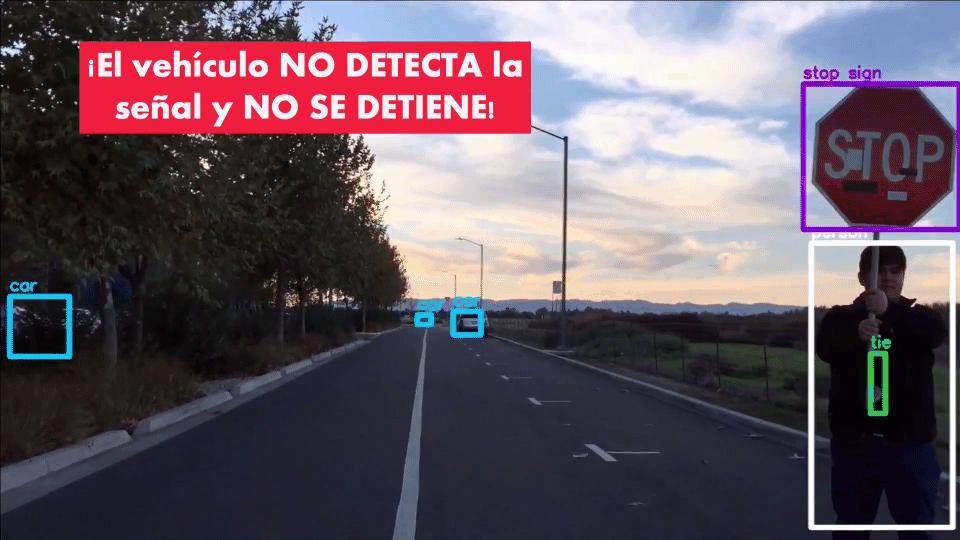
Incluso, si a una señal de pare se le hacen ligeras modificaciones (añadiendo cintas de diferentes colores) el vehículo autónomo es incapaz de reconocerla y de detenerse

De hecho existe una propiedad aún más intrigante en estos ejemplos adversarios: la transferibilidad.
Esto quiere decir que si se diseña un ejemplo adversario para atacar una arquitectura en particular, muy probablemente este ejemplo será capaz de engañar de engañar otras redes de mayor o menor complejidad:
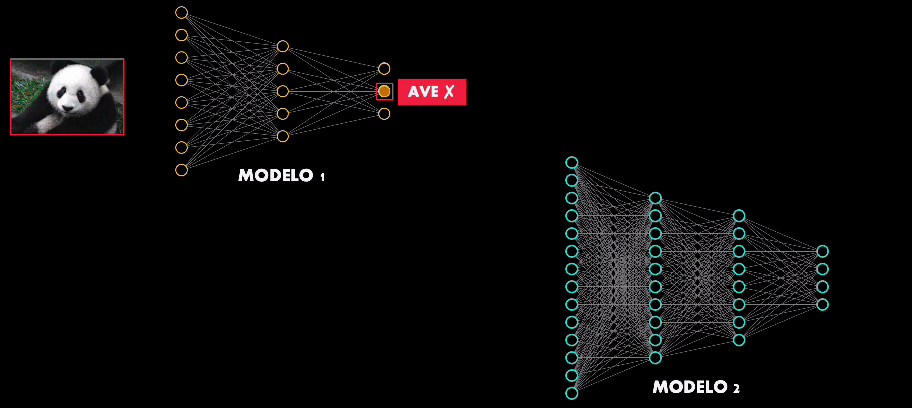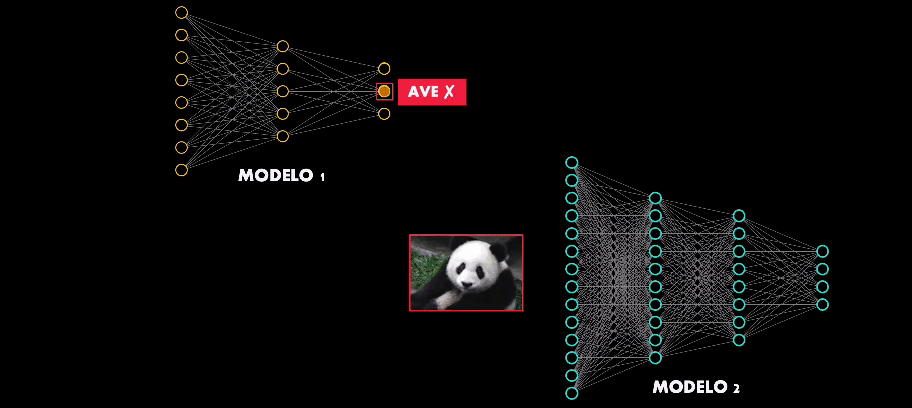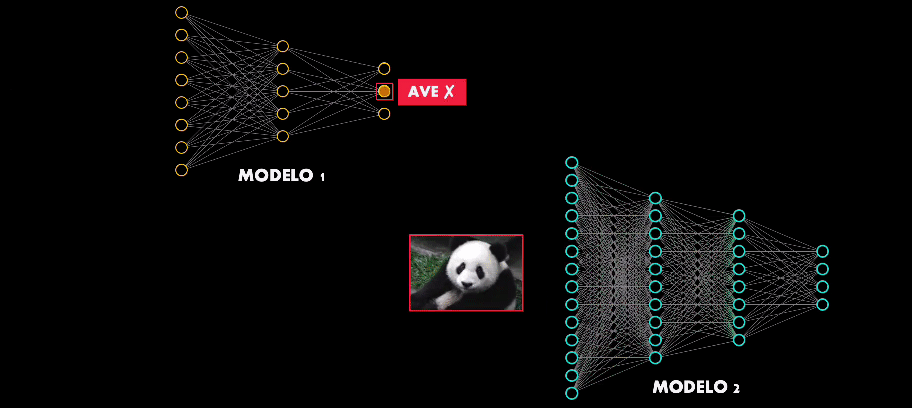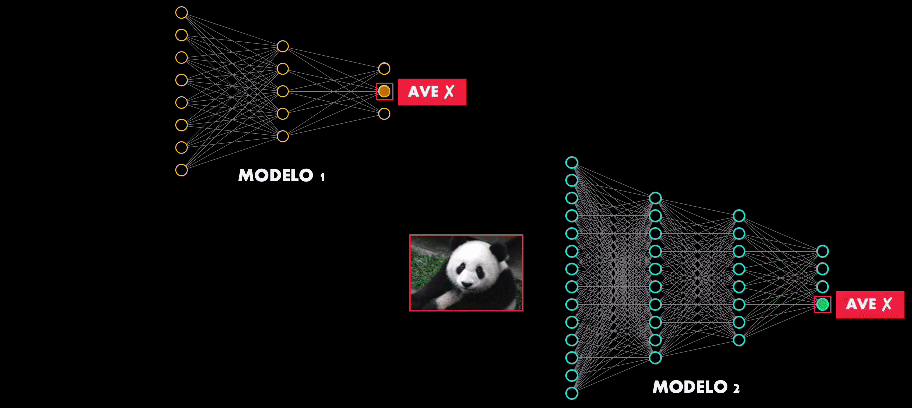
Así que hay algo en común en el proceso de entrenamiento y aprendizaje de las Redes Neuronales, independientemente del número de neuronas o capas que estas tengan.
¿Pero qué es lo que hace que las Redes Neuronales terminen confundidas ante cambios tan ligeros que para nosotros, los seres humanos, no resultan tan problemáticos?
Pues en los últimos 5 años se ha venido investigando este tema y hasta el momento no hay una respuesta concluyente… O tal vez sí, pero esto lo veremos al final del post.
Por ahora hablemos de algunas estrategias, no muy efectivas, que se han ideado para combatir estos ataques adversarios.
Posibles estrategias para combatir los ataques adversarios
Estas estrategias en principio se pueden dividir en dos grupos: las proactivas y las reactivas.
Estrategias proactivas
Las estrategias proactivas consisten en entrenar el modelo con ejemplos adversarios. Es decir, durante el entrenamiento se introducen imágenes “limpias” (sin modificación alguna) y de manera intencional se introducen imágenes “contaminadas” (es decir ejemplos adversarios), para de esta manera enseñar al modelo a identificarlas como imágenes falsas:
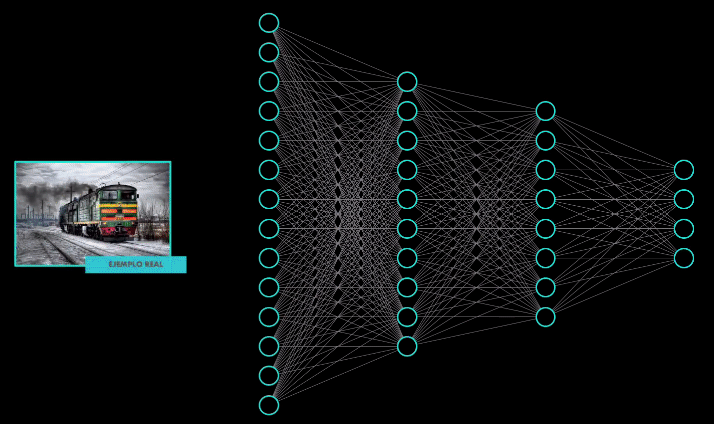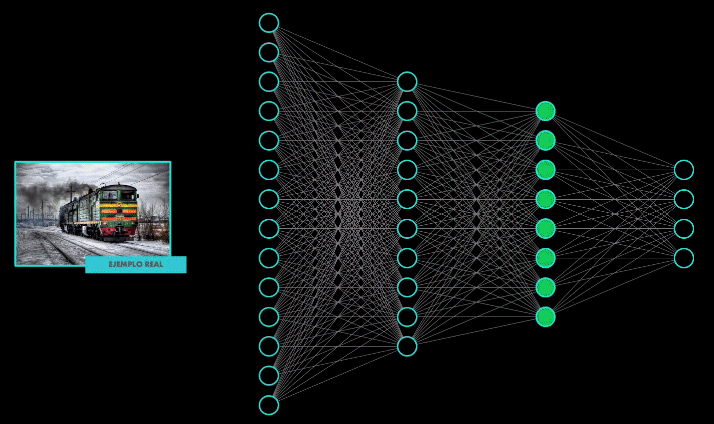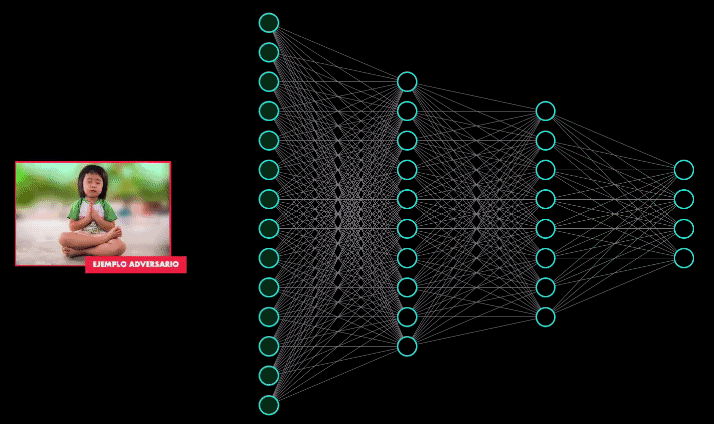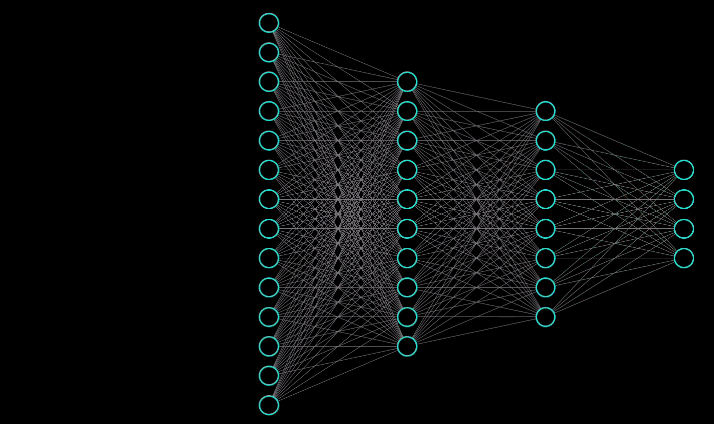
Sin embargo esta estrategia no resulta exitosa, pues ¿recuerdas que hace un momento hablé de la transferibilidad? Un atacante podría tener su propio modelo “local” y diseñar múltiples ejemplos adversarios. Luego podría usar estos ejemplos en el modelo “remoto”, el que desea atacar, y tarde o temprano, por ser ejemplos transferibles, estos terminarían engañándolo.
Estrategias reactivas
Las estrategias reactivas consisten en ocultar los detalles del modelo al posible atacante. Por ejemplo, en un sistema de clasificación de imágenes (como los usados por Google o Microsoft), en lugar de mostrar la distribución de probabilidades para cada categoría, bastaría con ocultar esta información y simplemente mostrar la categoría más probable. Con esto el atacante no tendría información de la distribución de probabilidades y resultaría difícil estimar si el ejemplo adversario introducido logra cambiar o no esta distribución:

El problema en este caso es que el atacante podría usar un esquema de fuerza bruta: crear múltiples ejemplos adversarios en su propio modelo local y luego ponerlos a prueba en el modelo remoto. Tarde o temprano algunos de estos ejemplos lograrían engañar al segundo modelo.
Así que con esta estrategia no tendremos un modelo más robusto, simplemente le haremos la tarea un poco más difícil al atacante.
¿Existe algún mecanismo de defensa exitoso frente a los ataques adversarios?
Pero entonces, ¿será que resulta posible crear un mecanismo de defensa frente a estos ataques adversarios? ¿O definitivamente se trata de una debilidad innata de cualquier modelo de machine o Deep learning?
Aunque hasta el momento no existe una estrategia definitiva, los autores del artículo Adversarial Examples Are Not Bugs, They Are Features plantean una idea muy interesante: atribuyen la existencia de ejemplos adversarios al hecho de que la red aprende durante el entrenamiento a identificar dos tipos de características: las robustas y las no-robustas:

Los autores plantean la siguiente hipótesis: las características no-robustas son aquellas que probablemente para el ser humano no tienen significado alguno, o aparentemente no contienen información relevante, pero para los modelos de Deep Learning contienen información altamente predictiva que es esencial al momento de realizar la clasificación.
Entendamos primero qué es esto de las características robustas y no robustas.
Las características robustas y no robustas en detalle
Supongamos que deseamos usar una Red Convolucional para clasificar imágenes en dos categorías: perros o gatos. Una característica robusta sería aquella que es compartida por ambos animales. Por ejemplo: ambos tienen orejas, ojos, cabeza, patas. Estas características permiten a la red determinar que se trata de un animal, pero no son suficientes para diferenciar un gato de un perro:

Una característica no robusta sería por ejemplo un detalle más susceptible, un detalle al que por ejemplo los seres humanos no le prestamos mucha atención o que incluso ni siquiera logramos percibir. Este detalle podría ser la orientación del pelo: en los gatos podría ir hacia los lados, en los perros hacia abajo, o los bigotes: en los gatos son más gruesos, más pronunciados, en los perros se podría confundir con con el pelaje de la cabeza. Incluso el mismo patrón de las manchas: en los perros usualmente tienen formas más circulares y ocupan mayores zonas del cuerpo, en los gatos muchas veces son simplemente franjas:

Y la idea central es esta precisamente: las características no robustas, los detalles más finos, muchas veces imperceptibles por nosotros los humanos, son las más relevantes para los modelos de Deep Learning y son las que en definitiva permitirían discriminar un ejemplo real de un ejemplo adversario.
Usando las características robustas y no robustas para combatir los ataques adversarios
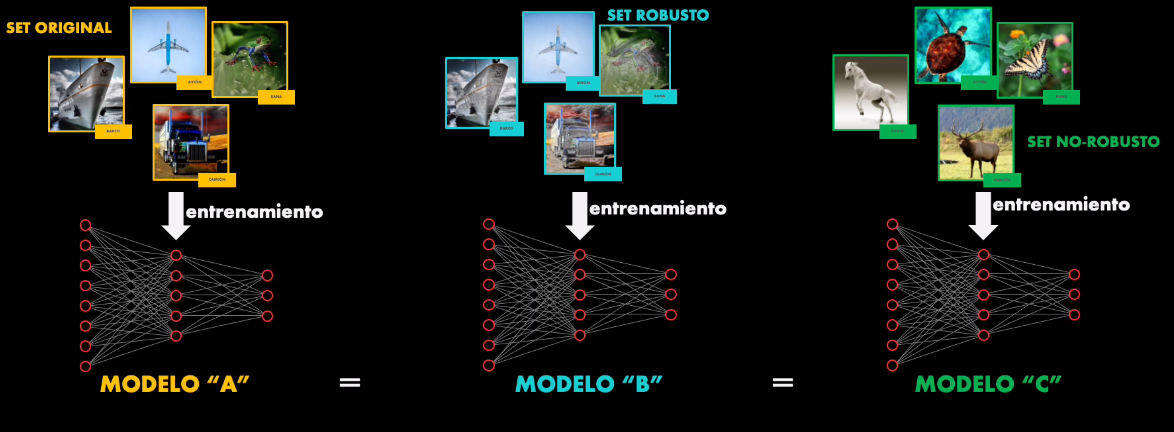
Para probar la hipótesis anterior los autores crean primero tres sets de datos:
- El set de entrenamiento original
- Un set de entrenamiento “robusto”
- Un set de entrenamiento “no robusto”

En último set las imágenes parecen corresponder a una categoría diferente. Sin embargo contienen características no robustas, imperceptibles para el ser humano, pero relevantes para la Red.
Después de esto entrenan tres modelos: el modelo A, con el set de entrenamiento original, el modelo B con el set de entrenamiento robusto y el modelo C con el set de entrenamiento no robusto. Es importante observar que los tres modelos son idénticos, lo único que cambia es el set de datos con el cual se entrenan:
Y finalmente validan estos modelos usando el set de prueba original y agregando ejemplos adversarios:
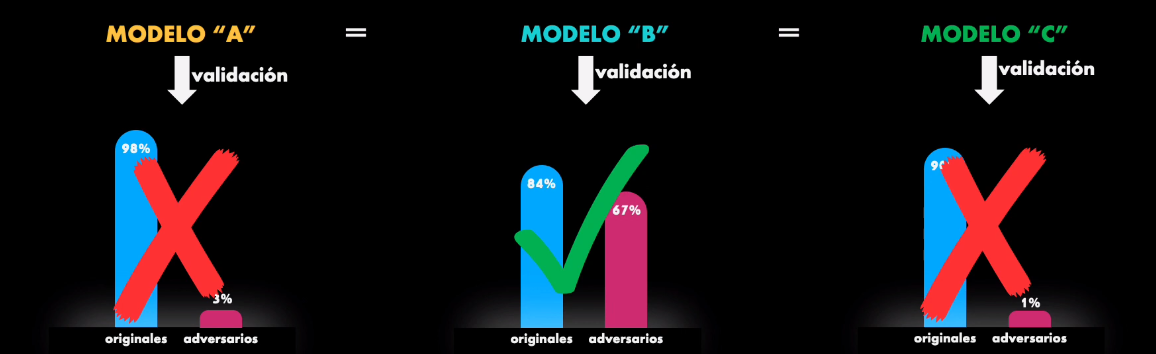
¿Qué se esperaría obtener? Lo ideal en cualquier modelo es que clasifique correctamente tanto el ejemplo original como el adversario, pues finalmente el ejemplo adversario ha sido diseñado para tratar de engañar al modelo, pero la idea es que el modelo aprenda a clasificarlo correctamente.
Así que, durante la validación lo ideal sería obtener una buena precisión con ambos sets de prueba: el original y el que contiene ejemplos adversarios.
Pues bien, al validar el modelo A se obtiene el resultado esperado: la precisión es alta con el set original y muy baja con los ejemplos adversarios. Esto quiere decir que el modelo no es inmune a estos ataques.
Pero con los otros dos modelos ocurre algo interesante: el modelo B (entrenado con el set robusto) tiene una precisión alta con el set original y también con los ejemplos adversarios. Sin embargo, el modelo C (entrenado con el set no robusto) tiene una precisión alta con el set original pero muy baja con los ejemplos adversarios.
¿Y todo esto qué significa? Pues significa que en últimas un ataque adversario tiende a afectar las características no robustas en la imagen y por tanto, un modelo que dependa de estas características no robustas (como el modelo A y el modelo C) no logrará responder adecuadamente a estos ataques. Sin embargo, si durante el entrenamiento se logra eliminar la dependencia del modelo de estas características no robustas (como en el caso del modelo B, entrenado únicamente con características robustas) entonces es posible lograr que el modelo responda mejor ante estos ataques adversarios.
Este es un resultado interesante, pues indica que probablemente el problema de los ataques adversarios no necesariamente se debe al modelo como tal, sino al set de datos que se use para entrenarlo.
Esto también explica la transferibilidad de los ataques adversarios entre un modelo y otro, pues si no cambiamos nada en el set de entrenamiento, cualquiera que sea la red entrenada esta dependencia de características no robustas seguirá estando presente, independientemente de la complejidad del modelo.
Conclusión
En últimas podemos decir que los ataques adversarios son un fenómeno asociado fundamentalmente a nuestra percepción humana.
El hecho de que una imagen de un panda, ligeramente modificada, sea clasificada como un avestruz, resulta para nosotros incoherente, pues a la vista sigue siendo un panda. Sin embargo, en el fondo, este fenómeno lo que nos muestra es que muy probablemente las Redes Neuronales interpretan la información de una forma muy diferente a como los humanos lo hacemos, pues durante el entrenamiento crean una dependencia de características sutiles del dato (imperceptibles a nuestros ojos) pero que en últimas pueden terminar siendo explotadas por un ataque adversario que en últimas logra confundir a la red.
Sin embargo, todo esto lo que muestra es que a pesar de los grandes avances que ha tenido la Inteligencia Artificial en los últimos años, aún desconocemos en detalle muchos de los elementos que permiten explicar la forma como estos modelos aprenden a extraer información. En este sentido aún falta mucho camino por recorrer.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: