BERT: el inicio de una nueva era en el Natural Language Processing
En este post veremos en detalle el funcionamiento de BERT, un modelo que ha sido pre-entrenado con un corpus gigantesco (¡más de 3.300 millones de palabras!), que funciona en más de 102 idiomas y que con tan sólo una ligera modificación es capaz de tener un desempeño igual o superior al del ser humano en múltiples tareas del Procesamiento del Lenguaje Natural.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube encontrarán el video de este post:
Introducción
El Procesamiento del Lenguaje Natural (o NLP por sus siglas en Inglés: Natural Language Processing) es una de las “joyas de la corona”, hasta el momento inalcanzable, para el Machine Learning.
En el NLP se busca lograr que los humanos se puedan comunicar con los computadores usando el lenguaje natural (la conversación, el texto) en lugar de un lenguaje de computador.
Y aunque durante los últimos años ha habido desarrollos impresionantes, solo hasta 2018 apareció BERT, una nueva arquitectura desarrollada por Google que marcó el inicio de una nueva era en el natural language processing.
Para comprender qué es y la importancia de BERT en el Machine Learning, necesitamos entender qué es el Procesamiento del Lenguaje Natural.
Procesamiento del Lenguaje Natural: algunas definiciones
El lenguaje natural se refiere simplemente a la forma como nosotros los humanos nos comunicamos unos con otros, bien sea por escrito (usando el texto) o de manera oral (con la voz).
Así que el NLP consiste en desarrollar algoritmos de computador que sean capaces de entender el lenguaje natural y que permitan una interacción hombre-computador en ambas direcciones.
Tareas en el NLP
Pero esta no es una tarea trivial. Si queremos que un computador entienda lo que decimos, o lo que escribimos, tendrá que ser capaz de ejecutar varias tareas propias del NLP:
- Inferencia: dadas dos frases, debería ser capaz de predecir si la segunda frase guarda relación con la primera, o es una contradicción o la relación es neutral

- Equivalencia semántica: determinar si dos preguntas son semánticamente equivalentes (es decir si significan lo mismo)

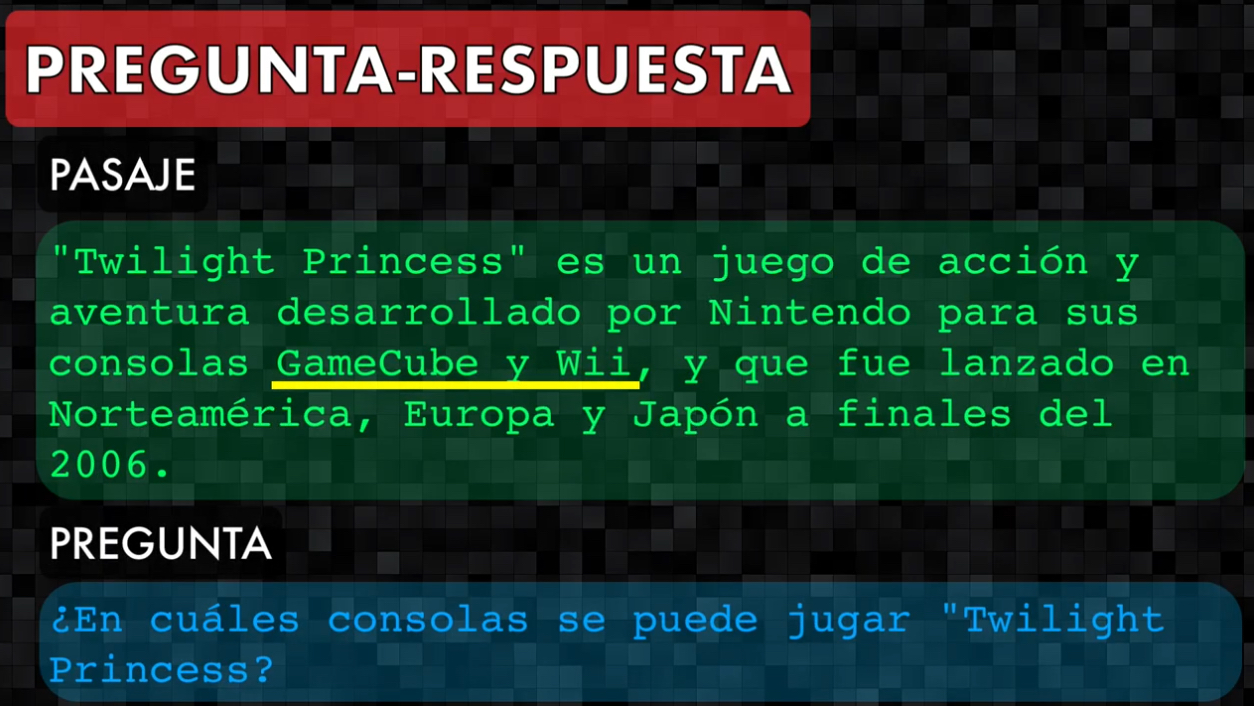
- Pregunta-respuesta: dado un pasaje y una pregunta, encontrar en el texto la respuesta correspondiente
- Análisis de sentimientos: dado un texto identificar si el sentimiento que se está expresando es positivo, negativo o neutral

- Aceptabilidad lingüística: dada una frase identificar si esta es gramaticalmente correcta

- Respuesta correcta: dada una frase, determinar su continuación entre 4 posibles opciones

El gran problema es que para ninguna de estas tareas se cuenta con un set de entrenamiento lo suficientemente grande, y esto dificulta el desarrollo de modelos robustos de Machine Learning que resuelvan precisamente estas tareas.
BERT: una solución a este inconveniente
Pues bien, acá es donde entra en escena BERT, el modelo propuesto por Google en 2018 y que resuelve el problema de una manera muy ingeniosa.
¡BERT no es Beto, el personaje de Plaza Sésamo!. Su nombre viene de las siglas en Inglés Bidirectional Enconder Representations from Transformers; es decir, es un codificador que obtiene representaciones bidireccionales a partir de Redes Transformer. Pero bueno, esto no nos dice mucho, así que desglosemos su significado.
Básicamente los autores de BERT proponen lo siguiente: ¿por qué no en lugar de crear un modelo que resuelva cada tarea individualmente, se entrena un modelo base que aprenda a interpretar el lenguaje en general:

y luego, a este modelo ya entrenado, le agregamos unas capas adicionales que permitan que el modelo se especialice en una tarea en particular:

El modelo base puede ser pre-entrenado con sets de datos inmensos, y luego de agregar la capa especializada se puede re-entrenar el modelo con sets más pequeños para que realice tareas más específicas.
Pues bien, ¡¡¡resulta que esta idea funciona!!! Así que BERT se ha convertido en el primer modelo de Machine Learning multipropósito capaz de interpretar el lenguaje humano en diferentes aplicaciones, y por eso se ha convertido en un hito en el NLP.
Bien, habiendo entendido esto veamos ahora sí en detalle en que consiste este modelo.
BERT: arquitectura explicada en detalle
BERT nace precisamente de las Redes Transformer, un nuevo tipo de arquitectura creado en 2017 y que, como vimos en un post anterior, ha sido el precursor de toda esta revolución en el NLP.
La Red Transformer procesa el texto en dos fases: una para la codificación encargada de procesar el texto de entrada y de codificarlo numéricamente extrayendo su información más relevante, y una fase de decodificación que se encarga de generar una nueva secuencia de texto (que es útil por ejemplo cuando se hace la traducción de un idioma a otro). En ambos casos cada bloque está conformado por múltiples codificadores y decodificadores:
Bien, pues con BERT lo que nos interesa es tener un modelo capaz de codificar el texto, obteniendo así una representación numérica que permita su correcta interpretación. Así que BERT es simplemente el resultado de tomar la red transformer y quedarnos únicamente con el bloque de codificación.
Y esta arquitectura viene en dos sabores: BERT básico con un total de 12 codificadores y 110 millones de parámetros, y BERT large, la versión más completa y más poderosa, con 24 codificadores y 340 millones de parámetros:

En ambos casos es necesario adecuar el texto de entrada para que la red pueda procesarlo.
En las tareas que vimos anteriormente el dato de entrada siempre estará conformado por dos elementos, bien sea dos frases, un párrafo y una pregunta, o dos preguntas. Así que el texto de entrada se codifica como dos frases:
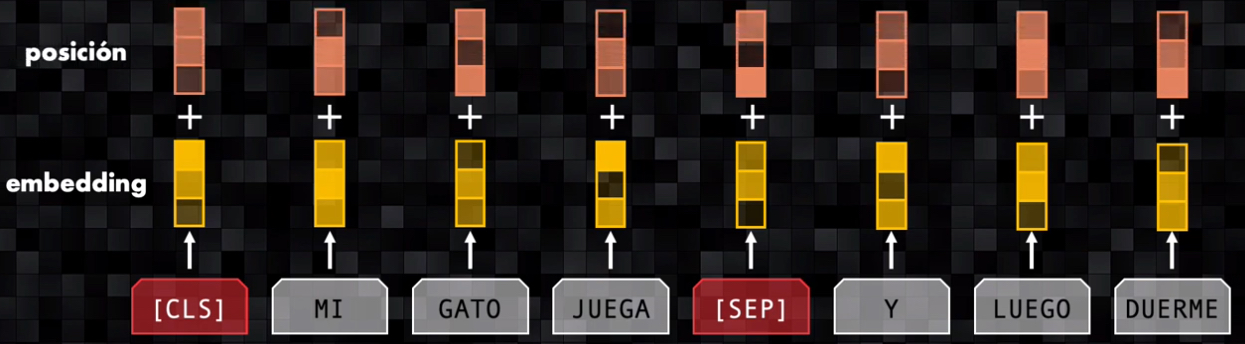
- Al inicio se incluye siempre un token de clasificación (CLS) y para separar una frase de otra se incluye el token de separación (SEP). En un momento veremos el papel de estos tokens

- Después, por cada token se obtienen tres representaciones:
- Un embedding, que representa el token como un vector y una codificación posicional, como las usadas en la red transformer original. Recordemos que la codificación posicional es necesaria para indicarle al bloque de codificación la posición relativa de cada palabra dentro de la frase, pues todas las palabras son procesadas de manera simultánea por la red
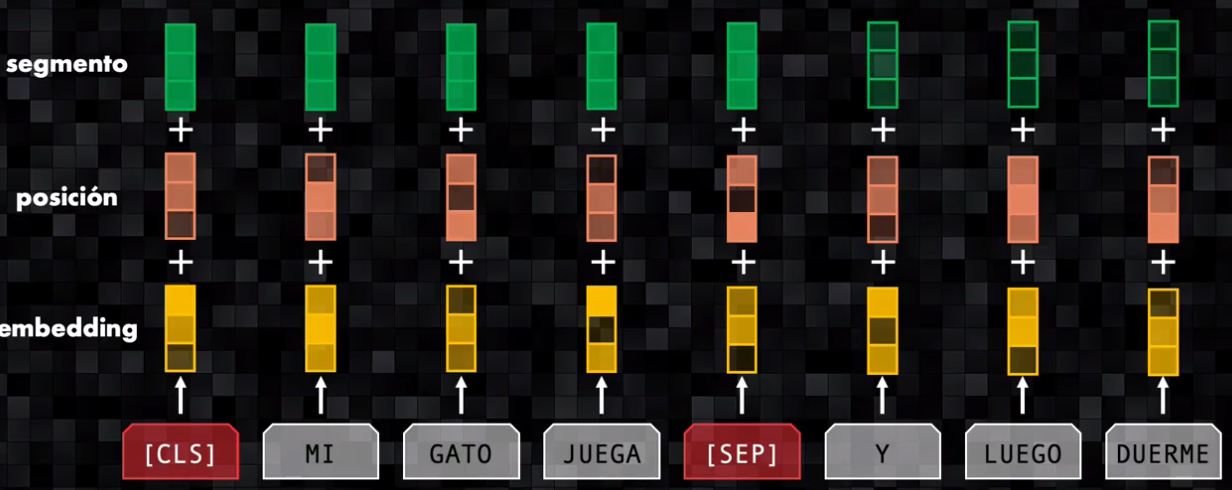
- Adicional a estas dos codificaciones se añade un embedding que indica a qué segmento pertenece la frase: la primera frase (antes del separador) se codifica con un embedding diferente al de la segunda frase.
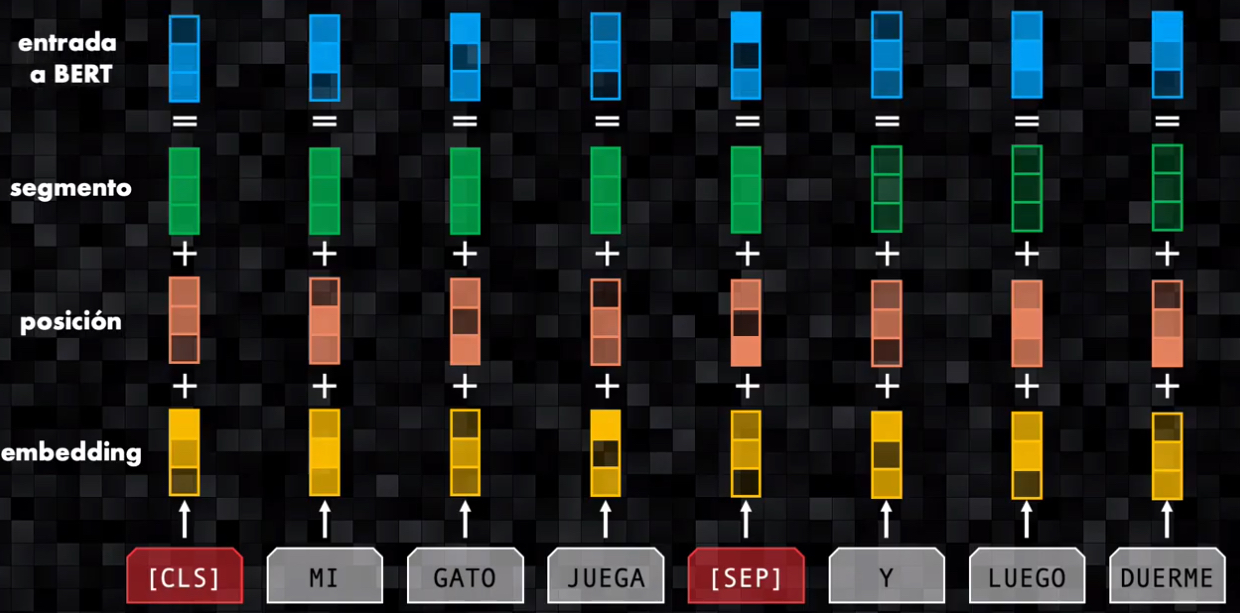
- Finalmente se suman estas tres representaciones y los vectores resultantes son procesados por BERT:
Siguiente paso: pre-entrenamiento y afinación
El entrenamiento de BERT se hace en dos fases.
Fase 1: pre-entrenamiento
En la primera fase BERT es pre-entrenado usando dos sets gigantescos: Wikipedia y google books, que en conjunto contienen más de 3.000 millones de palabras!
Con este entrenamiento BERT aprende a analizar el texto de manera bidireccional, es decir que aprende a codificar cada palabra teniendo en cuenta todo su contexto: tanto lo que está a su derecha como a su izquierda.
Por ejemplo, una misma palabra puede tener dos significados distintos dependiendo de su contexto. Con esta bidireccionalidad es posible codificar de manera precisa su significado.

Para lograr esto primero se enseña al modelo a completar una palabra faltante en una frase. Esta palabra faltante puede estar en cualquier ubicación, y con esto se está forzando al modelo a que aprenda a analizar el texto de manera bidireccional. Aprendiendo así a comprender el lenguaje tal como lo hacemos los seres humanos.
Ahora se continua con el pre-entrenamiento enseñando al modelo a predecir la continuación de una frase.
Esta tarea se sencilla: dadas dos frases (A y B) ¿es B realmente la frase que viene después de A o es simplemente una frase aleatoria?
Para que BERT aprenda a identificar estas diferencias, durante el pre-entrenamiento el 50% de las veces la frase B es efectivamente la que sigue a “A” y el 50% de las veces restantes no lo es.
Y listo, con estas dos tareas ya se tendrá un modelo bastante robusto que es capaz de representar de manera muy completa relaciones bidireccionales entre palabras y frases.
Fase 2: afinación
Culminado el pre-entrenamiento resulta muy sencillo afinar el modelo para tareas específicas.
Al modelo pre-entrenado se agregan dos pequeñas capas: una red neuronal y una capa softmax.
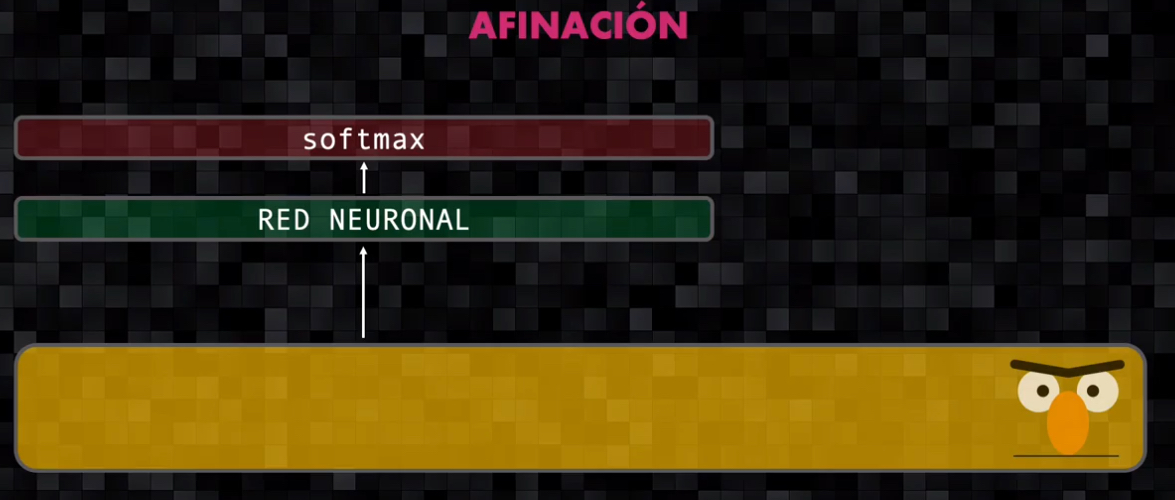
Luego se presentan las frases de la tarea específica y se re-entrena el modelo de extremo a extremo, con la única diferencia de que esta fase requiere menos tiempo pues el modelo ya ha sido pre-entrenado en la fase anterior.
Cuando se tienen tareas como inferencia, equivalencia semántica, análisis de sentimientos o aceptabilidad lingüística, se tiene simplemente un problema de clasificación. Así que a la salida de BERT se analizará únicamente la representación correspondiente al token de clasificación, pues al ser bidireccional BERT condensa toda la información necesaria para la clasificación en este único token.
Para las tareas tipo pregunta-respuesta se usa un esquema similar. La única diferencia es que al final la red neuronal y la capa softmax no entregarán una categoría, como en el caso anterior, sino que realizarán la predicción de los tokens de inicio y finalización de la respuesta encontrada dentro del texto.
Conclusión
Y bien, esto es BERT, un poderosísimo modelo que ha generado una revolución en el NLP.
Además de existir modelos pre-entrenados en más de 100 idiomas, se pueden encontrar muchas librerías de código abierto que implementan BERT para diferentes tipos de aplicaciones del NLP. En los próximos posts comenzaremos a explorar estas librerías y veremos tutoriales en Python en donde usaremos BERT para resolver diferentes tareas del procesamiento del lenguaje natural.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: