Detección de Rostros con Machine Learning
La detección de rostros es una etapa esencial del reconocimiento facial. En este post veremos cómo usar las Redes Convolucionales para la detección de rostros, y al final las usaremos para realizar la detección de rostros en tiempo real.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
En el post anterior hablamos del reconocimiento facial, que consiste en determinar la identidad de una persona a partir de una imagen de su rostro.
Pero en una aplicación real de esta tecnología nos encontramos frente a un problema: la imagen sobre la que se hará el reconocimiento no contiene únicamente el rostro, muy probablemente contendrá otros elementos adicionales, incluso otros rostros, que dificultarán el proceso.
Para lograr hacer el reconocimiento necesitamos aislar las porciones de la imagen que contienen únicamente rostros, lo que se conoce precisamente como la detección de rostros.
¿Qué es la detección de rostros?
Bien, la detección de rostros es un problema en donde se busca localizar uno o más rostros en una fotografía o en múltiples frames de un video:

Y esta localización consiste en encontrar las coordenadas del rostro (o de los rostros) dentro de esa imagen. Es decir que lo que se busca es encontrar el bounding box de cada rostro, la cajita que demarca su ubicación dentro de la escena:
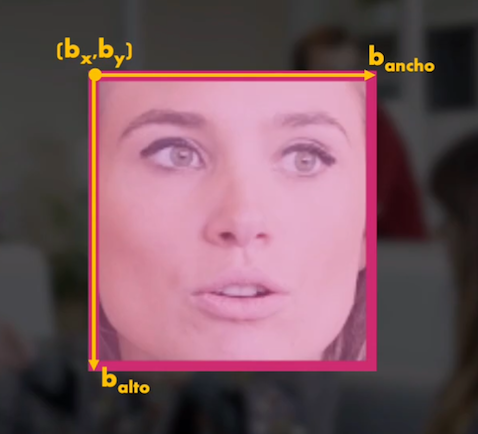
Para nosotros los humanos es una tarea bastante sencilla, pues al fin y al cabo nuestros cerebros llevan miles de años evolucionando y poseen Redes Neuronales especializadas en esa detección de rostros.
Pero lograr que un computador logre hacer esto es un reto gigantesco, dada la variabilidad que pueden tener los rostros humanos en una escena.
Por ejemplo, el sistema debe ser capaz de detectar rostros independientemente de su escala (pues en una misma escena puede haber rostros de diferentes tamaños):

o de su pose:

o de los gestos:

Incluso puede haber oclusiones, donde sólo se observa una parte del rostro, o pueden tener diferentes expresiones, o variaciones en la iluminación.
Y en todas estas situaciones el sistema de detección debería ser capaz de encontrar la ubicación de los rostros.
La detección de rostros usando procesamiento de imágenes
Para lograr esta detección automática se han ideado diferentes métodos, y los primeros fueron desarrollados a comienzos de este siglo, y hacían uso de técnicas básicas de visión por computador y procesamiento de imágenes.
En los algoritmos más usados se hace un barrido a través de la imagen, y en cada posición de la ventana de interés se intentan detectar patrones que permitan diferenciar el rostro de otros objetos, bien sea usando algunos filtros básicos, como en el caso del algoritmo de Viola and Jones (2001), o analizando las diferencias entre tonalidades claras y oscuras en la imagen, como en el caso del algoritmo de histograma de gradientes orientados (2005):

El problema de estos métodos es que se requieren condiciones ideales para que el rostro sea detectado correctamente. Cuando hay algún tipo de rotación o cambios en la iluminación, simplemente no logran hacer la detección.
Detección de rostros con Machine Learning: las Redes Convolucionales al rescate
Pues bien, usando Redes Convolucionales es posible lograr construir detectores de rostros mucho más robustos.
Para lograr esto es necesario entrenar las redes precisamente con imágenes de rostros humanos, y durante el proceso la red aprende a realizar dos tareas simultáneamente:
En primer lugar se entrena para clasificar el contenido de la escena, determinando si esta contiene o no un rostro humano:


En segundo lugar, y para el caso en el cual la imagen contenga un rostro, la red aprende a generar las coordenadas de inicio del bounding box que contiene dicho rostro, así como su ancho y alto:

Hablemos en detalle de dos de las Redes Convolucionales más usadas en la actualidad para la detección de rostros: la red multitarea en cascada y MobileNet. Ambas son capaces de detectar rostros en imágenes o secuencias de video con una altísima precisión independientemente de la escala, pose, de las oclusiones o expresiones o de las condiciones de iluminación del rostro.
Multi-Task cascaded convolutional networks (MTCNN)
La red MTCNN es capaz de detectar uno o múltiples rostros en imágenes o secuencias de video usando una conexión en cascada de tres Redes Convolucionales:
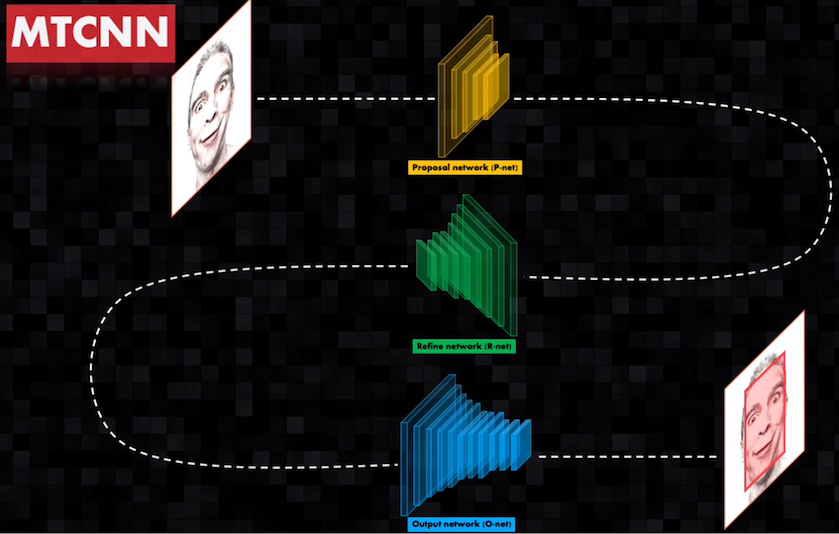
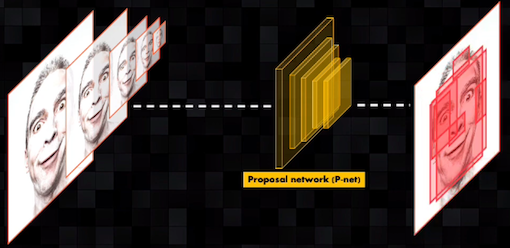
A la entrada de la primera red (proposal network o P-net) se introduce la escena original y la misma imagen a diferentes escalas. Con esto la red detectará, precisamente, rostros de diferentes tamaños presentes en la imagen original. Esta primera red es poco profunda y como contiene pocas capas permite detectar rápidamente regiones candidatas que contengan probablemente rostros:
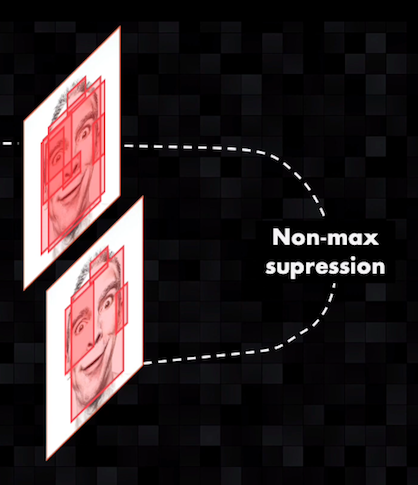
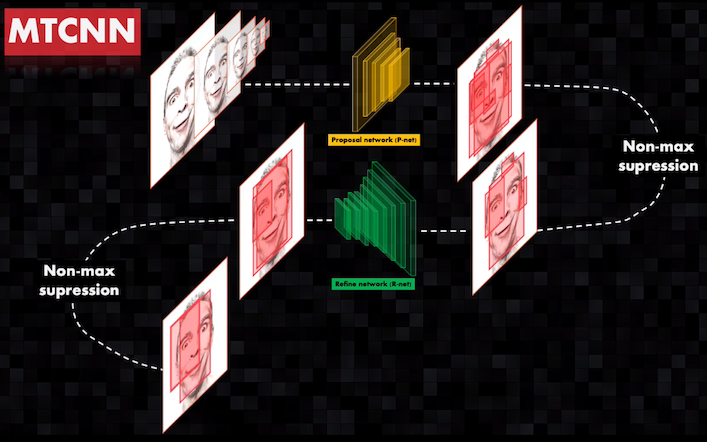
Cuando para un rostro se identifican varios bounding boxes de tamaño similar y que ocupen prácticamente la misma porción de la imagen, se usa un algoritmo conocido como non-max supression.
Para hacer esto se analiza la probabilidad de que cada bounding box contenga un rostro, un dato que es generado precisamente por el clasificador de la red. Luego se eliminan todos los bounding boxes exceptuando aquel que tenga la mayor probabilidad:
Estos bounding boxes candidatos, junto con la escena original, son introducidos a una segunda red (Refine network o R-net) más profunda que permite refinar los resultados anteriores, eliminando varios de los bounding boxes generados por la red anterior y mejorando la precisión en las coordenadas de los nuevos bounding boxes:
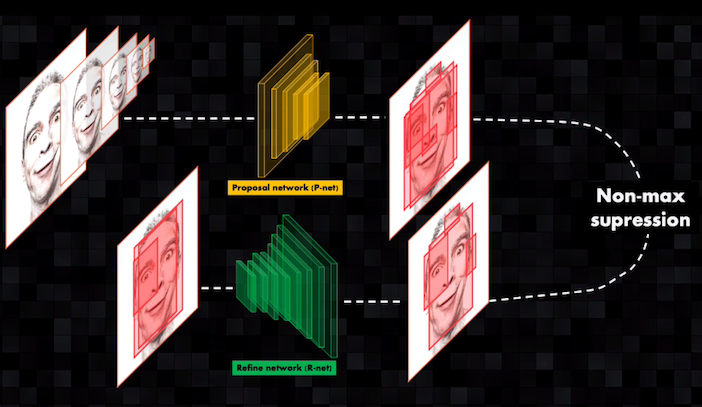
De nuevo se aplica el algoritmo de non-max supression:
y tanto la imagen original como los nuevos bounding boxes son enviados a la tercera etapa (Output network o O-net). Esta red es aún más profunda que las dos anteriores, y permite al final obtener con precisión un único bounding box por cada imagen de entrada:
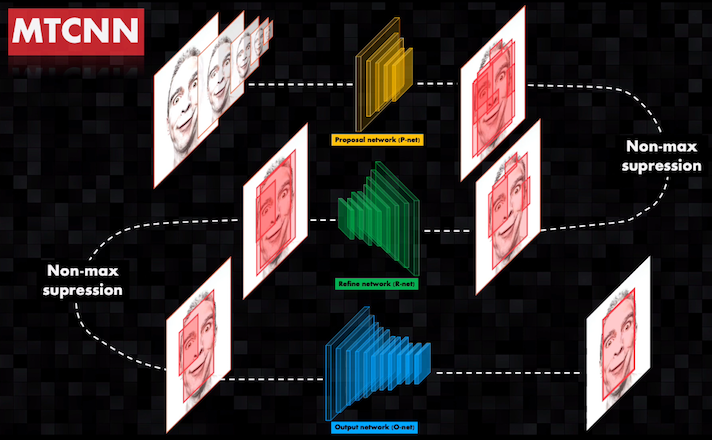
A pesar de la alta precisión lograda, la gran desventaja es que en este caso el uso de tres redes convolucionales requiere demasiado tiempo de procesamiento, y por eso esta arquitectura tiene limitaciones para aplicaciones en tiempo real.
MobileNet
Esta también una Red Convolucional capaz detectar objetos, pero que puede ser entrenada para la detección de rostros:

La gran ventaja de esta red es su rapidez para el procesamiento, que se logra haciendo las convoluciones de una manera más eficiente.
Así, si a manera de ejemplo suponemos que tenemos una pequeña imagen a color, de 6x6 pixeles, y que la procesaremos con 4 filtros, cada uno de tamaño 3x3x3, entonces con la convolución hecha de forma convencional requeriríamos 1728 multiplicaciones!!!:

Pero con MobileNet esta convolución se hace en dos etapas: primero se separan los tres planos de la imagen y se cada uno se convoluciona con un filtro de 3x3x1. Acá se requieren tan sólo 432 multiplicaciones.
Luego, el volumen resultante se convoluciona con cuatro filtros de 1x1x3. Y es aquí donde se obtiene otra reducción significativa, pues al final se necesitan tan solo 621 operaciones, es decir ¡casi la tercera parte de lo que se requiere con la convolución convencional!

En el caso práctico, con imágenes más grandes, con MobileNet se logra realizar la detección de rostros de forma precisa pero casi unas cuatro veces más rápido que con la red MTCNN, y por eso MobileNet es más adecuada para realizar la detección en tiempo real.
Detección de rostros: MTCNN vs MobileNet
Ahora sí comparemos el desempeño de estas dos redes.
Al hacer la detección en tiempo real vemos que los dos sistemas son bastante precisos y ubican correctamente el rostro independientemente de la escala, la rotación, los gestos o las condiciones de iluminación. Realmente son detectores muy, muy robustos.
Y todo esto a pesar de que en el fondo hay diferentes tipos de objetos.
Sin embargo hay una diferencia importante: como era de esperar MobileNet hace el procesamiento más rápido. Para el caso de esta red podemos ver que los movimientos en la captura de video son más naturales, y esto se debe al menor número de operaciones requeridas durante la detección.
Conclusión
Bien, ya sabemos cómo es que funciona un sistema de detección de rostros basado en Redes Convolucionales. Si combinamos esto con el sistema de reconocimiento facial que vimos en el post anterior, tenemos todos los elementos para implementar un sistema de reconocimiento facial en Python. Pues este será precisamente el tema del próximo artículo.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: