El Aprendizaje Reforzado: la guía definitiva
En este post les traigo una guía definitiva sobre el Aprendizaje Reforzado, en donde les mostraré el panorama completo, en qué consiste, cómo ha evolucionado, cuál es su potencial y su relación con el Machine Learning.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube encontrarán el video de este post:
Introducción: la evolución del Aprendizaje Reforzado
El aprendizaje reforzado es una de las áreas más excitantes y prometedoras del Machine Learning en la actualidad, pues tiene el potencial de crear máquinas o agentes inteligentes, capaces de realizar tareas de forma muy parecida a como lo hacemos nosotros los humanos.
En 1952 el matemático norteamericano Claude Shannon, fue uno de los primeros en desarrollar una de las primeras aplicaciones del aprendizaje reforzado: creó un ratón artificial, llamado Theseus, que a través de prueba y error logró aprender a atravesar un laberinto, recordando la ruta más exitosa con la guía de imanes ubicados en el piso.

Con el paso del tiempo se lograron otros avances pero más que todo en la teoría. Pero en el año 2013 se dió inicio a una verdadera revolución: los investigadores de Deep Mind crearon un sistema capaz de aprender a jugar prácticamente cualquier juego de Atari desde cero y de superar a los humanos, usando sólo como entrada los pixeles de cada escena, sin tener ningún conocimiento previo de las reglas mismas de estos juegos.
Esta fue la primera de una serie de logros cada vez más impresionantes, que continuaron en Mayo de 2017 AlphaGo, un agente inteligente que fue capaz de vencer al campeón mundial de Go, un juego de mesa extremadamente complejo inventado en China hace más de 2.000 años.

¿Pero cómo lograron desarrollar este sistema? La idea fue bastante simple: combinaron el poder de las redes neuronales, un área del Machine Learning, con las técnicas básicas de aprendizaje reforzado que se venían desarrollando desde los años 50.
Y con esto precisamente nació el aprendizaje reforzado profundo, una de las áreas del Machine Learning con aplicaciones potenciales que van más allá del desarrollo de videojuegos, como la robótica, la automatización industrial e incluso el desarrollo de nuevos medicamentos.
El Aprendizaje Reforzado: intuición
Pero un momento, vamos paso a paso. Para entender que es el aprendizaje reforzado profundo debemos entender lo básico. ¿Qué es esto del aprendizaje reforzado? ¿cómo es que esta tecnología permite que “las máquinas” logren aprender y ejecutar actividades similares a las humanas?
Para entender esto del aprendizaje reforzado usemos un ejemplo intuitivo, que para este caso es un videojuego. Aunque ojo, todo lo que vamos a ver de aquí en adelante se puede extender a otras áreas como la robótica, o el control o a cualquier posible aplicación del aprendizaje por refuerzo.
Bien, volviendo a nuestro ejemplo. Supongamos que vamos a enseñar a un humano a jugar Pong!, el clásico juego de atari:

Si le mostramos por primera vez el juego a una persona, le podríamos dar una instrucción como esta: “con el teclado puede controlar una paleta, que se mueve hacia arriba o hacia abajo. Su tarea es golpear la bola hasta lograr que su oponente no logre alcanzarla. Cada vez que haga esto obtendrá un punto. Gana el jugador que logre obtener más puntos al final de la partida”.
Lentamente el nuevo jugador humano aprenderá a controlar la paleta, a golpear la bola y a marcar puntos, a través de un proceso de prueba y error,. Y eventualmente logrará vencer al oponente.
¿Y cómo lograríamos esto con un computador? Pues bien, para eso deberíamos crear un programa, que en adelante llamaremos agente:
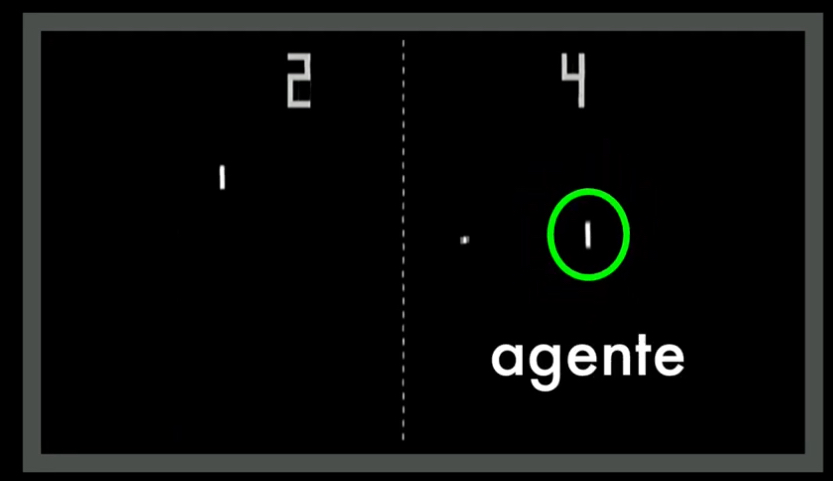
Este agente debe lograr hacer varias cosas: en primer lugar debe “entender” los elementos del juego: hay dos oponentes, un tablero, una bola, dos paletas. Es decir debe entender el entorno:
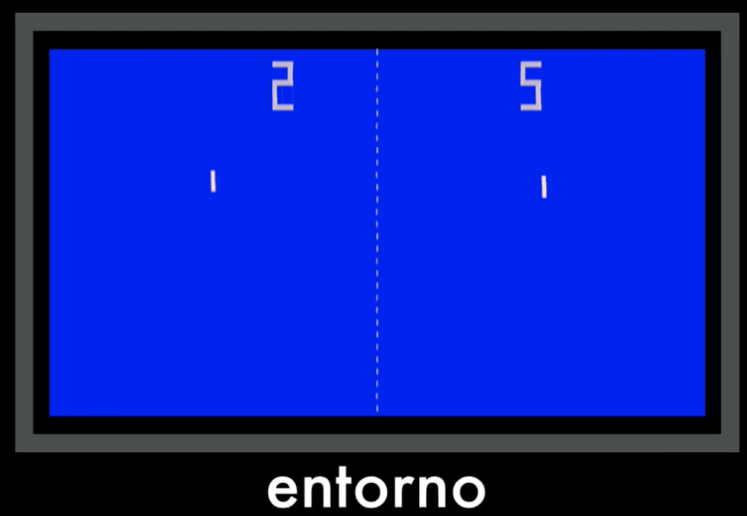
Después de esto el agente debe “entender” lo que está sucediendo en el entorno, es decir, por ejemplo, la dirección de la bola o los movimientos de su oponente. A esto lo llamaremos estado:
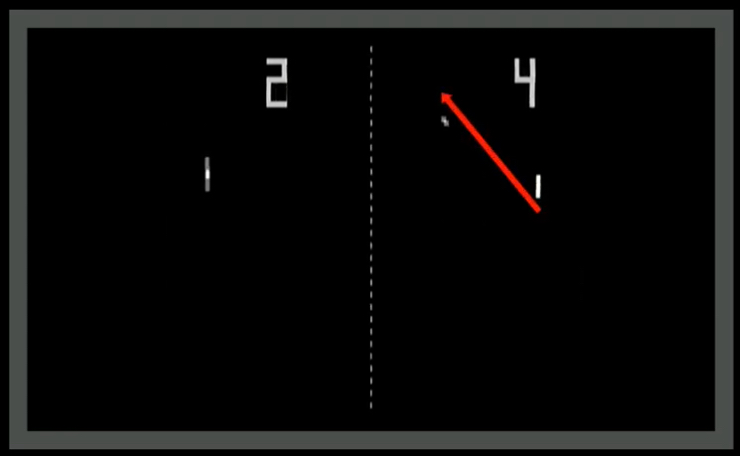
Dependiendo del estado el agente deberá aprender a moverse en el tablero para tratar de vencer a su oponente. A esto lo llamaremos acción:
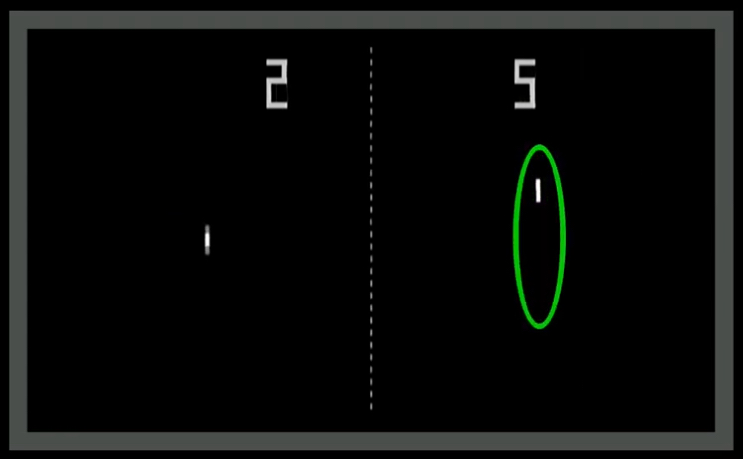
La manera de saber si lo hizo bien o mal será a través del puntaje: si el agente lo hace mal recibirá un punto en contra (una penalización), pero si lo hace bien recibirá un premio. A este premio o castigo les daremos el nombre genérico de recompensa (que podrá ser por tanto positiva o negativa):
Con estos elementos ahora sí podemos dar una definición de lo que es el aprendizaje reforzado: la idea detrás del aprendizaje reforzado es que “un agente aprenderá de su entorno, mediante la observación de su estado y mediante su interacción a través de una serie de acciones por las cuales recibirá una recompensa”:
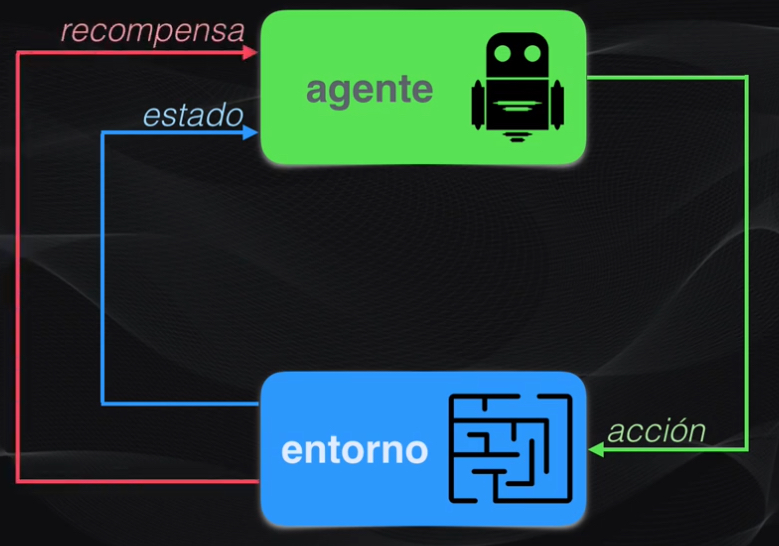
Al final la idea es que el agente aprenda a ejecutar la mejor acción posible, dependiendo del estado observado, lo que a la larga le permitirá obtener la mayor recompensa positiva posible. En el contexto de Pong! esto equivale simplemente a ganar el juego.
Y esta misma definición la podemos aplicar a diferentes contextos. Por ejemplo, en el caso de un robot el agente será el programa que controla su movimiento. El entorno será el mundo real, el estado serán los posibles obstáculos que encuentre en su camino, las acciones serán los movimientos realizados y la recompensa será positiva si el robot logra llegar a su destino final, y negativa si por ejemplo gasta tiempo yendo en la dirección contraria, o si se cae.
El Aprendizaje Reforzado: una definición más formal
Bien, ya tenemos una idea general de lo que es el aprendizaje por refuerzo. ¿Pero cómo lograr que el agente aprenda del entorno y para que sirve en este caso el Machine Learning?
En esencia hay dos maneras de hacerlo, dependiendo de si el agente conoce al detalle su entorno o sólo parcialmente.
Aprendizaje reforzado basado en modelos
Cuando se conoce en detalle el entorno y sus reglas de juego tendremos un algoritmo de aprendizaje reforzado basado en modelos. Un ejemplo de un modelo de un entorno es precisamente el juego Go: con antelación el agente puede conocer las reglas del juego, los movimientos que puede realizar, el tamaño del tablero. Con este modelo el agente puede planear con antelación su siguiente movida, y puede analizar las implicaciones de este movimiento o elegir otras alternativas. El sistema Alphazero, desarrollado precisamente por DeepMind en 2017, es un ejemplo de un algoritmo de aprendizaje forzado basado en modelos.

El problema de este tipo de algoritmos es que sólo en contadas aplicaciones se tiene toda la información para construir un modelo del entorno. En la mayoría de las aplicaciones reales sólo se tiene acceso parcial, y en estos casos hablamos de aprendizaje reforzado libre de modelos, al que pertenecen la mayor parte de los algoritmos usados en la actualidad.
Aprendizaje reforzado libre de modelos
En este caso el agente debe aprender a tomar las decisiones por prueba y error, pues no conoce todos los detalles del entorno. En realidad sólo tiene acceso a dos elementos: los estados y la recompensa resultante de sus acciones. Un ejemplo de esto es precisamente la inteligencia artificial desarrollada en 2013 por DeepMind, y que fue capaz de vencer al ser humano en varios juegos de Atari, pero sobre esto volveremos más adelante para entenderla en detalle.

Pero para entender cómo funcionan los diferentes algoritmos de aprendizaje por refuerzo libres de modelos, necesitamos hablar de política…
Pero no, no es de la tradicional y aburrida política de nuestros países, no. En este caso la política se refiere al cerebro del agente, es el algoritmo o programa que le permite decidir qué acción tomar, dependiendo del estado observado.
La Política en el Aprendizaje Reforzado
Por ejemplo, si tenemos un juego hipotético en el cual el agente debe recolectar un diamante y obtener al final el puntaje más alto posible, en este caso la política le permitirá determinar la ruta más adecuada para evitar la mayor cantidad de penalizaciones y así al final lograr la recompensa positiva más alta.

Así que en el aprendizaje reforzado libre de modelos la idea es desarrollar un algoritmo que sea capaz de calcular esta política de manera tal que el agente se pueda desenvolver de manera óptima dentro del entorno.
Y para esto existen esencialmente dos algoritmos que son los pilares fundamentales del aprendizaje reforzado moderno: las Políticas de Gradientes y el Q-learning.
La Política de Gradientes
Hablemos primero de la política de Gradientes. La idea en este caso es que dado un estado en particular, el algoritmo debe predecir la acción a realizar maximizando de esta forma la recompensa total.

Volvamos a nuestro juego hipotético. En este caso el agente puede ejecutar 4 posibles acciones: movimiento a la izquierda, arriba, a la derecha o abajo. Supongamos que diseñamos un algoritmo de política con 4 parámetros, cada uno indicando la probabilidad de que el agente se desplace en estas direcciones.
Una forma de entrenar al agente es definiendo, por ejemplo, un set inicial de valores para estos 4 parámetros, donde cada valor indica la probabilidad de que el agente se mueva en dicha dirección.

Luego debemos hacer que el agente se mueva hasta que llegue a la meta, es decir hasta el final del episodio, y calcular la recompensa total obtenida. Después, modificamos ligeramente los parámetros, ejecutamos el episodio y calculamos la recompensa obtenida, y repetimos una y otra vez hasta lograr afinar los parámetros de forma tal que se obtenga la recompensa más alta posible.

Así que con la política de gradientes la idea es reajustar iterativamente los parámetros del algoritmo, y la dirección en la que nos debemos mover con estos ajustes es la de la máxima variación (o gradiente) de la recompensa obtenida al final.
Aunque para nuestro ejemplo hipotético esta forma de ajustar los parámetros funciona, en un caso más realista, es decir un agente que puede ejecutar múltiples acciones y en un escenario con muchísimos más estados, el problema se hace más complejo, y es casi como buscar una aguja en un pajar.
Afortunadamente una solución a este inconveniente está en el Machine Learning, pero esto lo veremos más adelante. Por el momento hablemos del segundo método más usado para el entrenamiento del agente: el Q-learning.
El Q-learning
En ese caso, el algoritmo Q-learning no generará directamente una predicción de la acción a realizar. En su lugar, el método permite calcular, para cada par de estados y acciones, la máxima recompensa que se obtendrá.

Para entender esto volvamos al caso de nuestro pequeño juego. Supongamos que nuestro agente se encuentra en el estado inicial, y que a partir de este estado puede ejecutar una de tres posibles acciones: moverse arriba, a la izquierda o a la derecha:

Lo ideal sería seleccionar la acción que resultase en el máximo puntaje posible al final del juego. Si tuviéramos una función mágica que, con antelación, muchas jugadas atrás, nos permitiese predecir la acción más inmediata a tomar, pues el agente tendría muchas probabilidades de culminar con éxito este juego.
Pues a esta función mágica la vamos a llamar la función Q (de “quality” o calidad) y va a representar qué tan buena será la acción que el agente tome en un estado determinado.
Así, lo que hace el Q-learning es encontrar esta función iterativamente, a medida que el agente va interactuando con el entorno, paso a paso.
Una manera simple de calcular esta función Q, o de calidad, es construyendo una tabla.
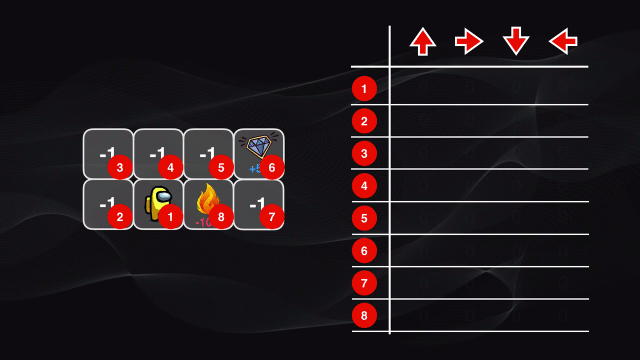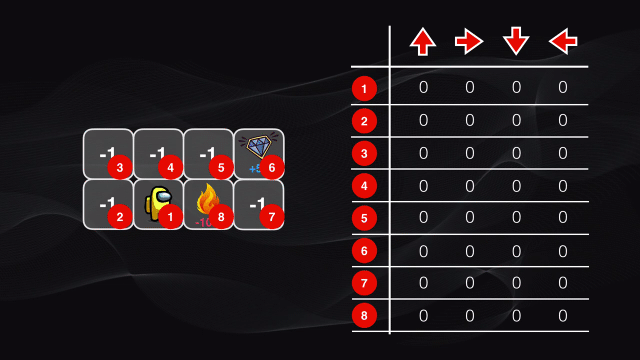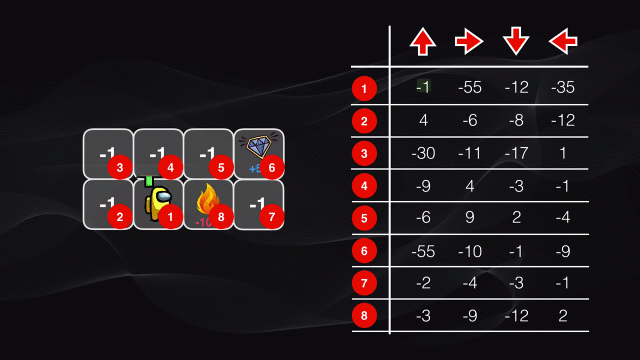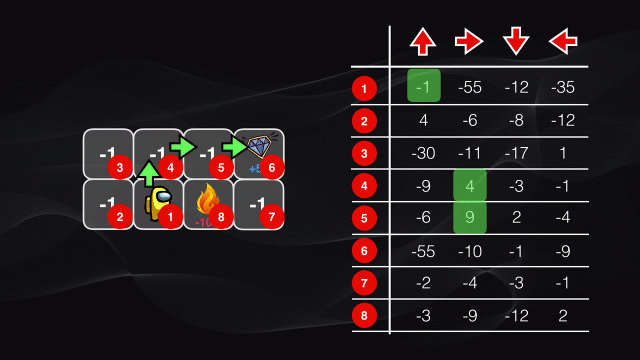
Volviendo a las recompensas pre-definidas para nuestro juego vemos que las casillas blancas entregan una penalización de -1 punto, la que contiene fuego -100, mientras que la que corresponde al diamante dará un premio de +50 puntos. Este esquema de puntuación pre-definido permitirá que el agente aprenda a moverse por las casillas blancas (que tienen una penalidad menor), a que en lo posible evite el fuego (con mayor penalidad) y a que busque la ruta más corta (con menor penalización) para llegar al diamante (con la máxima recompensa).

Para lograr esto, en cada una de estas visitas se va llenando una tabla, que tendrá tantas filas como estados haya disponibles, y tantas columnas como acciones pueda ejecutar el agente. Cada celda contendrá el valor máximo de la recompensa esperada para cada estado y cada acción.
En nuestro juego, se tendrá entonces una tabla con 7 filas (correspondientes a los 7 estados) y 4 columnas correspondientes a los 4 tipos de movimiento que puede realizar: izquierda, derecha, arriba o abajo.
Al comienzo todos los valores de la tabla serán cero, pues el agente no ha explorado el entorno. Luego comienza a desplazarse por el tablero y en cada caso almacena el puntaje en la posición correspondiente de la tabla. Al comienzo del algoritmo se moverá de manera aleatoria, pero cuando el procedimiento se repite muchas veces poco a poco nuestro agente irá descubriendo el patrón existente: los valores más altos de la tabla corresponderán a los pares estado-acción que arrojen el mayor puntaje posible:
Este algoritmo de Q-learning usa un enfoque de fuerza bruta: se deben visitar todos los posibles estados y analizar todas las posibles acciones en cada estado.
Y el método funciona bastante bien para nuestro juego hipotético, pues la tabla tenía únicamente 28 celdas. Pero en una situación práctica realmente no resulta viable.
Así que la gran desventaja del algoritmo del Q-learning es similar a la de política de gradientes: no es escalable. Entre más estados y acciones existan, más difícil será lograr el entrenamiento del agente.
Afortunadamente muchos de estos inconvenientes pueden ser resueltos usando el Machine Learning. Así que ahora sí hablaremos de cómo combinar estos dos métodos con todo el poder de las redes neuronales.
El Aprendizaje Reforzado Profundo
En esencia una [red neuronal] es una arquitectura de Machine Learning que permite generalizar el conocimiento, que a través de un proceso de entrenamiento es capaz de encontrar patrones en los datos y aplicar este conocimiento adquirido en datos que no ha visto previamente. Si quieren saber más sobre las redes neuronales los invito a ver este post en donde explico en detalle cómo funcionan.
Así que si en los dos algoritmos reemplazamos los bloques funcionales por redes neuronales, en cada caso tendremos un agente con un “cerebro” más potente.
Y es que al contar con redes neuronales, estos sistemas de aprendizaje reforzado ahora tienen la capacidad de analizar escenarios más complejos, tanto continuos como discretos, con muchos más estados y más acciones.
Y esto gracias a la capacidad de estas redes neuronales de generalizar y de encontrar patrones en los datos que a simple vista los seres humanos no podemos percibir.
Aplicaciones del Aprendizaje Reforzado
El potencial del aprendizaje por refuerzo profundo es inmenso, porque ahora se cuenta con algoritmos muy potentes y robustos que permiten a un agente aprender de forma autónoma, tan sólo observando e interactuando con su entorno, tareas relativamente complejas, en algunos casos equiparando e incluso superando el desempeño del ser humano.
Y esto no se reduce simplemente a los videojuegos o la robótica, como hemos visto hasta el momento. El aprendizaje reforzado profundo tiene por ejemplo un potencial inmenso en la industria, en donde se pueden entrenar agentes capaces de optimizar el consumo de energía o el uso de materia prima, o mejorando el transporte en las bodegas y las cadenas de suministro, o logrando desarrollar robots capaces de ejecutar autónomamente tareas en entornos hostiles, a los cuales resulta difícil el acceso de los seres humanos. Incluso, resulta posible desarrollar sistemas autónomos que aceleren el proceso de desarrollo de medicamentos.
Conclusión
Así que el aprendizaje reforzado, y en particular el aprendizaje por refuerzo profundo, es tal vez el área más prometedora del machine learning y que en los próximos años nos traerá desarrollos que cada vez más se asemejen a lo que a veces vemos tan sólo en ciencia ficción: la capacidad de desarrollar máquinas realmente inteligentes, que aprendan de la experiencia, similar a como lo hacemos nosotros los humanos.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: