MLOps: el Machine Learning Engineering
En este artículo hablaremos del Machine Learning Engineering o Machine Learning Operations (o simplemente MLOPs), el puente que nos permite pasar del Machine Learning Académico/Investigativo a un modelo en fase de producción.
Este es el primer artículo de la Machine Learning Operations, que explora cada una de las fases de un proyecto de Machine Learning, desde la obtención de los datos, pasando por la creación del modelo y finalizando en el despliegue, monitoreo y mantenimiento del sistema.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción: de hacer Pizzas en casa a montar una Pizzería
Imagina por un momento que, como yo, eres fanátic@ de la comida Italiana, y en particular de la Pizza. Y que por eso decides aprender a prepararla: buscas la mejor receta disponible, comienzas a practicar y con el tiempo logras ser un@ expert@ preparando Pizzas.
Y te gusta tanto que te animas a montar una Pizzería. Pero acá te das cuenta de que una cosa era preparar la Pizza en casa y otra muy diferente es comenzar a venderla. Te das cuenta de que necesitas un mejor horno, más materia prima, alguien que tome los pedidos y que haga las entregas… Así que debes aprender varias cosas adicionales para lograr pasar de la Pizza casera a un negocio de producir y vender Pizzas.
Pero bueno, y todo esto ¿qué tiene que ver con el Machine Learning? Pues tiene que ver mucho si queremos trabajar en una empresa y resolver algunas de sus necesidades usando precisamente el Machine Learning. Si ya sabemos los fundamentos es como saber hacer la Pizza en casa, pero llevar un modelo a producción para resolver un problema en la industria es como montar la Pizzería:

¿Qué es el Machine Learning Operations ó MLOps?
Y acá hay una idea súper importante: debemos aprender a llevar el modelo a producción. Y el MLOps es precisamente esto: es tomar un modelo, desarrollado usando esos fundamentos del Machine Learning, llevarlo a un usuario final, y lograr que este modelo se pueda actualizar periódicamente para garantizar que tenga siempre el desempeño esperado:
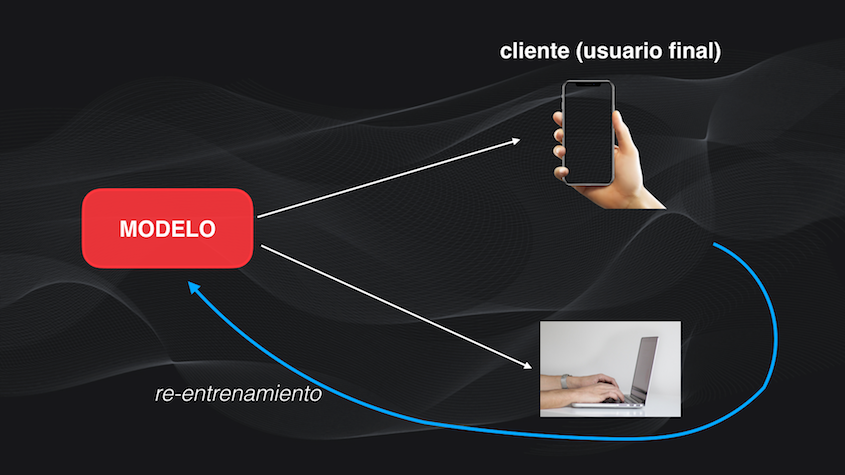
Y para lograr esto debemos contar con unas habilidades y herramientas menos científicas y más de Ingeniería. De algunas de estas herramientas hemos hablado en artículos anteriores, como el uso de Git en el Machine Learning, la importancia de SQL en el Machine Learning o el uso de contenedores como Docker en el Machine Learning, pero el tema va mucho más allá de estas herramientas.
Pues lo que vamos a ver ahora es un panorama completo de lo que es el MLOps, veremos cuáles son esas etapas que nos permiten llevar ese modelo a producción, como el despliegue (o deployment), el servicio (o model serving) y en qué consisten el monitoreo y mantenimiento del modelo.
De hecho, el Ingeniero o Ingeniera de Machine Learning es básicamente un híbrido entre el científico de Machine Learning, que conoce temas como el análisis exploratorio, el pre-procesamiento de datos y el desarrollo de modelos, y un Ingeniero de Software convencional, que conoce cómo diseñar, probar, desplegar y hacer el mantenimiento del software.
Pero hay una diferencia fundamental entre esta ingeniería de software convencional y lo que hace el MLOps. En la primera el software usualmente es estático y sólo ocasionalmente debe ser actualizado.
Sin embargo, en el MLOps tenemos un modelo dinámico, porque, una vez en producción, los datos cambiarán y por tanto el modelo deberá ser re-entrenado para ajustarse a esos nuevos datos, o de lo contrario sufrirá algo que se conoce como degradación (pero de esto hablaremos en detalle en un momento):
Así que un Ingeniero o Ingeniera de Machine Learning debe ser capaz de prevenir este comportamiento, o al menos de detectarlo y de implementar los correctivos necesarios para mejorar el comportamiento del modelo.
El ciclo de vida de un proyecto de MLOps
Para entender qué es esto de la “degradación” de un modelo, necesitamos tener claro el ciclo de vida de un proyecto de MLOps, así que veamos un ejemplo real: el caso de un sistema desarrollado por Airbnb, la plataforma online que permite contactar propietarios de viviendas en alquiler con huéspedes que necesitan este alojamiento. Esta plataforma es capaz de extraer información relevante a partir de las imágenes de los inmuebles, subidas por los usuarios de la plataforma.
Una de las metas de Airbnb es hacer que el mismo “negocio sea más eficiente, y que sus productos sean mucho más fáciles de usar”. Y uno de los inconvenientes es que muchas de las propiedades listadas en la plataforma tienen una descripción (dada por los propietarios) que no coincide con las características físicas del inmueble. Y como existen miles de propiedades ofertadas a través de la plataforma, para Airbnb es imposible visitar personalmente cada propiedad para verificar esta información:
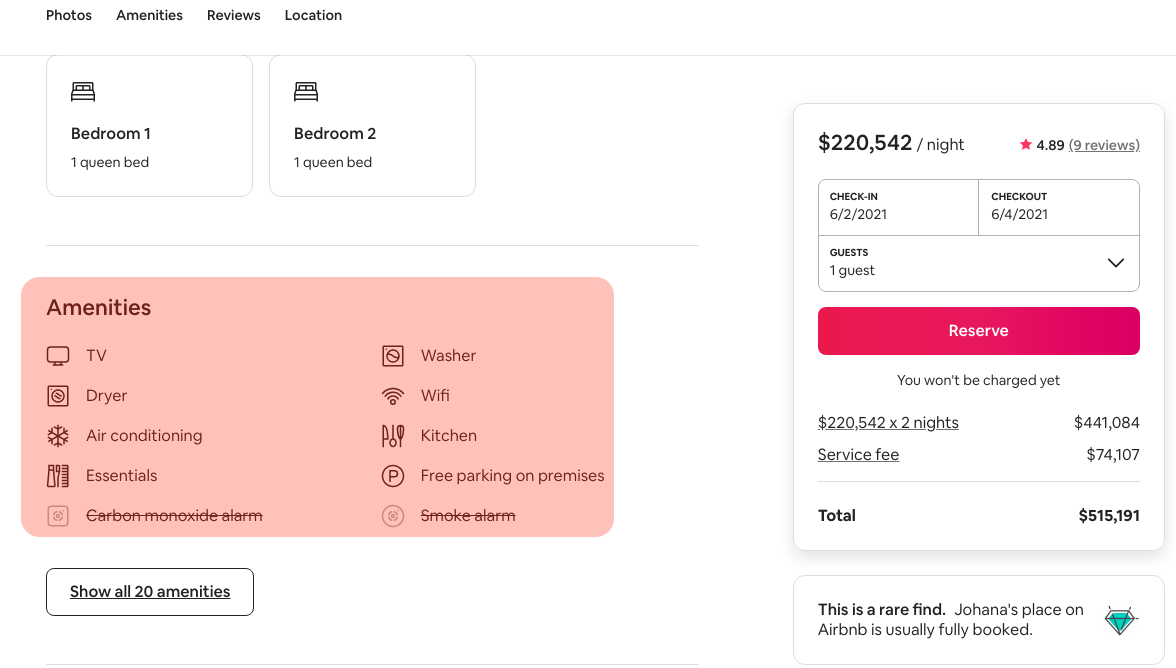
Así que la necesidad de la empresa es verificar de la forma más eficiente posible que la descripción hecha por los propietarios coincida con lo que físicamente se encuentra en el inmueble.
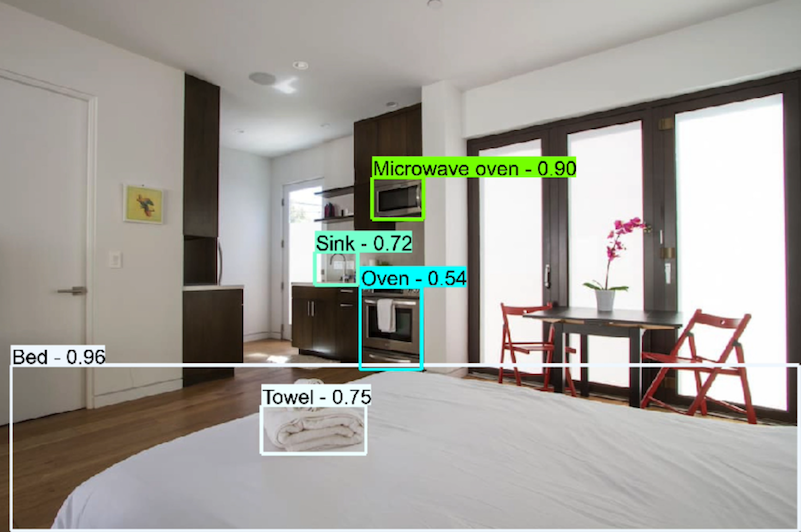
Y aunque de entrada esta necesidad parece no tener relación alguna con el Machine Learning, si la analizamos en detalle veremos que de hecho podríamos desarrollar un sistema de visión artificial de detección de objetos que analíce las imágenes subidas por los propietarios y detecte automáticamente los objetos de interés: los servicios, el equipamiento y el mobiliario disponible en el inmueble:
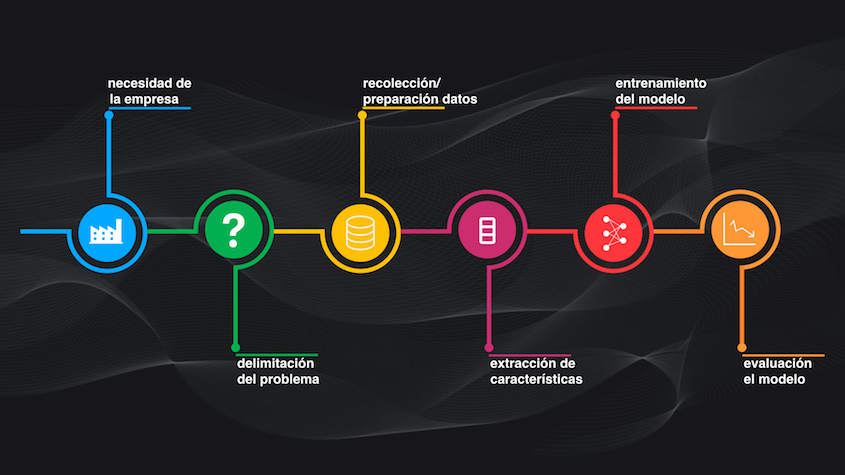
Si volvemos al ciclo de vida del proyecto de Machine Learning, podemos decir que la primera fase es tener claro el problema o la necesidad de la empresa (en este caso Airbnb).
Si el problema puede ser resuelto a través del Machine Learning, podemos pasar a la segunda fase de este ciclo de vida del proyecto: la delimitación del problema en términos propios del Machine Learning. Es decir que debemos definir el tipo de modelo a usar, la entrada y salida y sus criterios de desempeño:

En el caso de Airbnb este modelo se encargará de detectar los diferentes objetos presentes en la imagen con un alto nivel de confianza. Su entrada será una imagen y la salida será una serie de etiquetas (estufa, nevera, cocina, mesa, sofá, etc.), y este nivel de confianza se medirá por ejemplo con la precisión media media.
Las fases tres, cuatro, cinco y seis son las etapas convencionales de un proyecto de Machine Learning: recolectar y preparar los datos, de ser necesario realizar una extracción de características, entrenar y evaluar el modelo. Y, en el Machine Learning académico o de investigación, y para quienes son principiantes, hasta acá llegaría el proceso:
Pero si llegamos hasta acá no estaríamos dando respuesta al problema de negocio planteado. Es decir, en este punto sólo sabremos preparar la Pizza en casa, ¡pero nos falta montar la pizzería!
Es decir, ahora tenemos que llevar el modelo a producción, para que llegue al usuario final, que en este caso será el sitio web de Airbnb. Y acá es donde entran los elementos adicionales del Machine Learning Engineering.
Despliegue, servicio, monitoreo y mantenimiento: el Machine Learning en producción
Para montar nuestra pizzería se requieren cuatro fases adicionales: el despliegue del modelo, llevarlo a un servicio, e incluir una fase de monitoreo y una de mantenimiento:
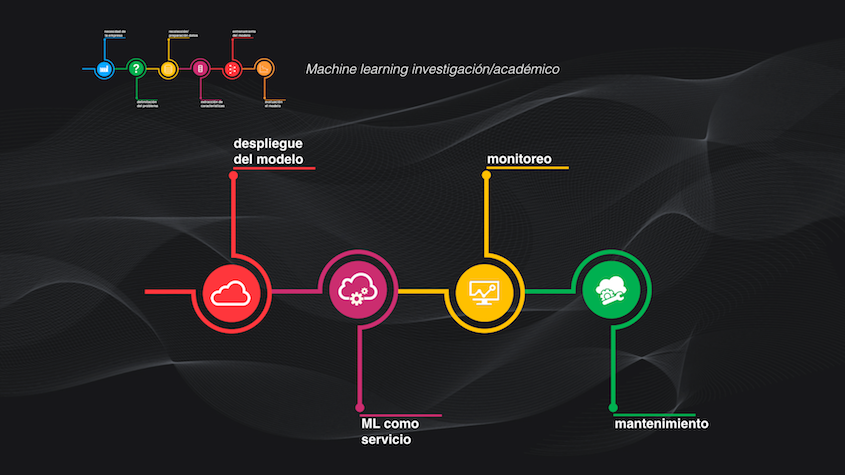
Veamos cada una de estas fases en detalle.
El despliegue (model deployment) y el servicio (model serving)
El despliegue consiste simplemente en poner a disposición del usuario final lo implementado en las fases anteriores, mientras que el servicio implica permitir que ese sistema acepte solicitudes del usuario y las lleve al modelo para generar una predicción.
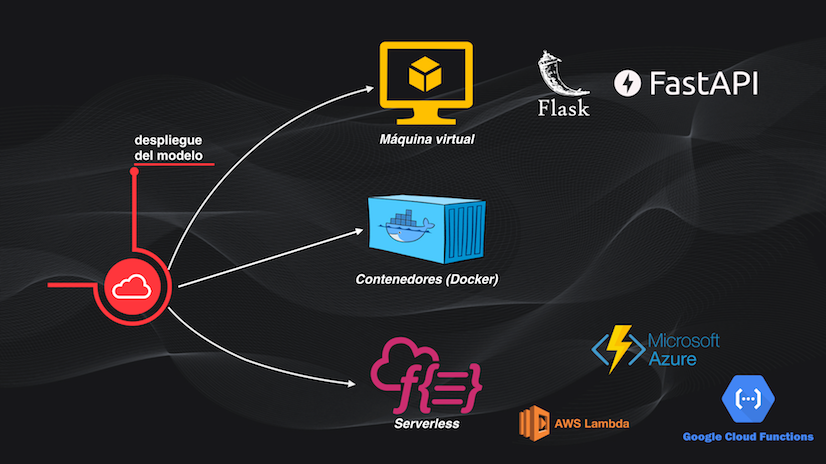
Y este despliegue, que se realiza usualmente a través servicios en la nube, viene esencialmente en tres diferentes sabores:
-
La primera forma es llevando el modelo y todas sus dependencias a una máquina virtual, para lo cual se pueden usar librerías como Flask o FastAPI, de las que voy a hablarles en próximos artículos. De hecho, el sistema de Airbnb se implementa precisamente usando este esquema de las máquinas virtuales.
-
La segunda alternativa consiste en usar contenedores de aplicaciones (si no saben lo que es un contenedor los invito a ver el artículo sobre cómo usar Docker en el Machine Learning, en donde les explico en detalle cómo funciona esta plataforma). Usualmente se usa Docker para crear y distribuir este contenedor, y luego un orquestador, que es como un director de orquesta (de ahí el nombre!), que se encarga de coordinar, en la nube, la interacción de todos los elementos del sistema. Uno de los orquestadores más usados es precisamente Kubernetes, del cual también hablaremos más adelante en otro post.
-
Y la tercera alternativa es hacer un despliegue sin servidor (o serverless). En este caso el modelo y el código asociado para recibir datos y realizar la predicción se almacenan en un archivo en formato zip que luego se sube a un servicio de la nube como “Lambda” de Amazon Web Services o “Functions” de Microsoft Azure y de Google Cloud. También, en un próximo artículo hablaremos de este esquema de despliegue más en detalle.
En este último caso la gran ventaja, con respecto a las dos formas de despliegue anteriores, es que no se tienen que aprovisionar recursos como servidores o máquinas virtuales: sólo se debe pagar por el tiempo de cómputo, es decir cuando se quiere hacer la predicción.
Monitoreo y mantenimiento del modelo
Bien, y después del despliegue y servicio del modelo están las fases de monitoreo y mantenimiento. Y la razón de esto es un elemento fundamental de cualquier proyecto de Machine Learning: los datos están cambiando constantemente.
De hecho, si volvemos al sistema de detección de objetos de Airbnb podremos ver que el modelo inicial fue entrenado con un set de datos específico. Sin embargo, la plataforma está en continuo movimiento, y los usuarios contínuamente estarán subiendo imágenes de sus inmuebles, así que no existe garantía alguna de que el modelo siga funcionando correctamente para esas nuevas imágenes:
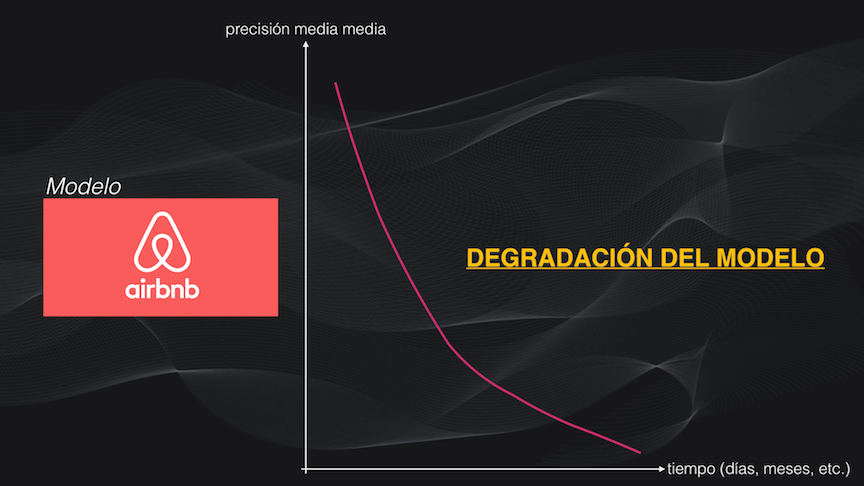
De hecho, esto es una constante en todos los sistemas de Machine Learning: el modelo se degrada con el tiempo, lo que quiere decir que sus predicciones irán empeorando poco a poco, pues los datos que se introducen al modelo cambiarán periódicamente.
Entonces la fase de monitoreo se encarga de verificar que el desempeño del modelo se mantenga, teniendo en cuenta que los datos están cambiando constantemente. Si hay degradación del modelo, entra a jugar la fase de mantenimiento, que se encarga de recolectar nuevos datos y re-entrenar el modelo para desplegarlo nuevamente y retomar el ciclo de producción del sistema:
Y si revisamos nuevamente todo el ciclo de vida de nuestro proyecto de MLOps, veremos que en realidad las fases no se ejecutan secuencialmente sino que por el contrario se trata de un proceso cíclico, pues si los datos cambian es muy probable que en alguna etapa del proceso tengamos que regresar por ejemplo a recolectar más datos, para luego re-entrenar el modelo, validarlo y llevarlo nuevamente a producción, y este proceso se debe repetir periódicamente para evitar la degradación del sistema:
Conclusión
Así que son muchos los elementos que se requieren para desplegar un modelo en un entorno de producción, adicionales a la creación misma del modelo. Estos elementos requieren el desarrollo de habilidades más de tipo ingenieril, y estas habilidades junto con los conocimientos básicos del Machine Learning son las que dan origen precisamente al MLOps.
En el segundo artículo de esta serie hablaremos de uno de los elementos centrales del MLOps: el despliegue de un modelo de Machine Learning.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: