Guía completa para el Manejo de Datos Faltantes
En este post nos vamos a enfocar en uno de los problemas ineludibles del análisis exploratorio de datos: ¿qué hacer cuando hay datos faltantes?
Al final del artículo encontrarás las instrucciones para descargar esta guía en formato PDF.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
En el artículo anterior hablamos del Análisis Exploratorio de Datos, y mencionamos que en cualquier proyecto de Machine Learning o Ciencia de datos nos tenemos que enfrentar a una situación ineludible: los datos no son ideales.
Pues en este post nos vamos a enfocar en uno de esos problemas ineludibles, y que es una etapa fundamental de ese análisis exploratorio: el manejo de los datos faltantes.
Así que veremos en detalle las dos grandes técnicas para el manejo de datos faltantes, que son el descarte y la imputación. Al final del post encontrarás el enlace de descarga de la guía detallada, para que fácilmente la puedas utilizar en tus proyectos cuando sea necesario.
La pregunta inicial: ¿por qué faltan datos?
Para saber cuál técnica podremos utilizar para el tratamiento de los datos faltantes, primero debemos determinar el mecanismo detrás de esa pérdida de datos. Y estos mecanismos se dividen en tres:
Datos faltantes completamente aleatorios (o MCAR: Missing Completely at Random)
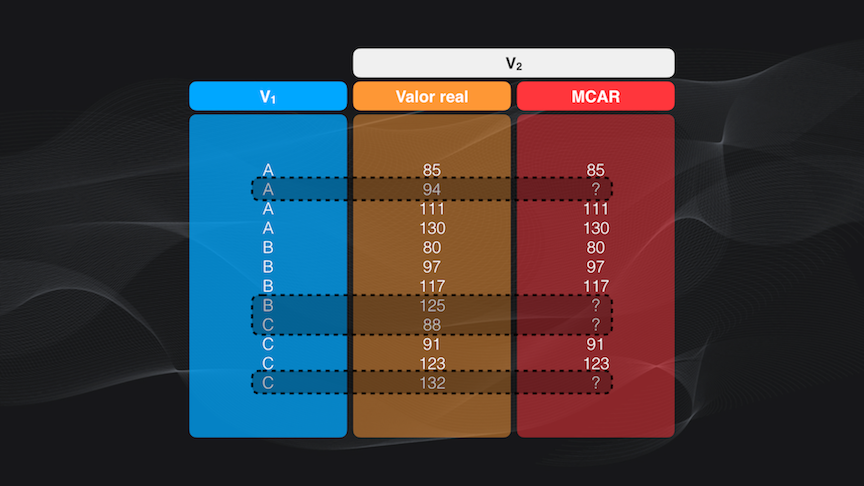
Primero están los datos faltantes completamente aleatorios (o MCAR por sus siglas en Inglés). En este caso la razón de la falta de datos es ajena a los datos mismos (???)
Para entender esto supongamos que tenemos un set de datos y que los datos faltantes aparecen tanto en la categoría A como en la B o en la C, y los valores faltantes pueden ser altos o bajos. Esto quiere decir que esos datos faltantes no dependen ni de la categoría ni del valor mismo de los datos, por lo que podemos decir que el mecanismo es completamente aleatorio:
Datos Faltantes NO aleatorios (o MNAR: Missing Not at Random)
El segundo mecanismo, los datos faltantes no aleatorios (o MNAR por sus siglas en Inglés) es totalmente opuesto al anterior. Esto quiere decir que la razón por la cual faltan los datos depende precisamente de los mismos datos que hemos recolectado (???)
De nuevo esto se entiende mejor con un ejemplo. Volviendo a nuestro set de datos hipotético podemos ver que sistemáticamente los datos con valores menores a 100 faltan, tanto para las categorías A, B como C. Es decir que los valores faltantes dependen de la variable “V2”, y por tanto la razón de la falta de datos NO es aleatoria:
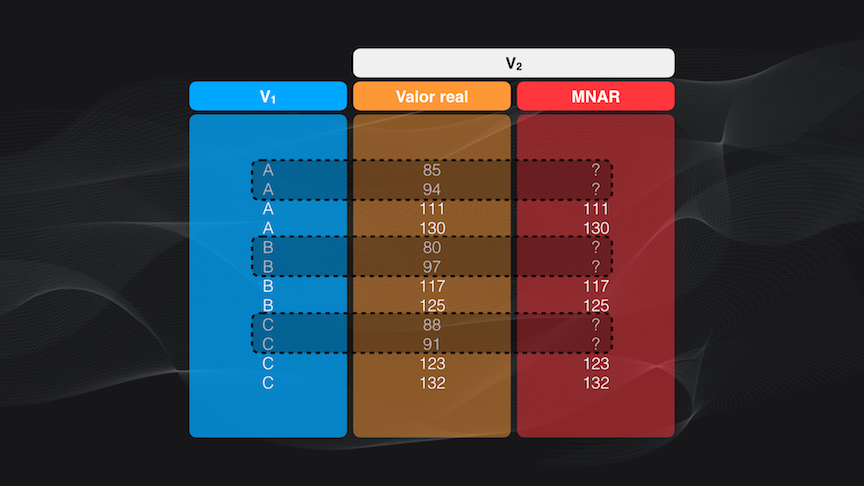
Este mecanismo es el más complicado de todos, porque como la pérdida de datos es sistemática tenemos que encontrar esta razón, intentar corregir el problema y, muy probablemente, adquirir los datos nuevamente.
Datos Faltantes Aleatorios (o MAR: Missing at Random)
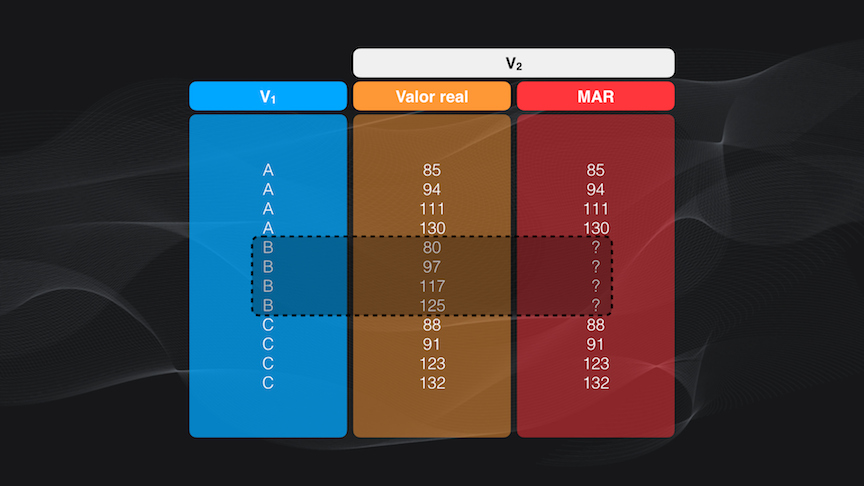
Y el tercer mecanismo es un punto intermedio entre los dos anteriores: los datos faltantes aleatorios (o MAR por sus siglas en Inglés). En este caso la causa de los datos faltantes NO depende de estos mismos datos faltantes, pero si puede estar relacionada con otras variables (es decir columnas) dentro del set de datos.
De nuevo, en el ejemplo vemos que los datos faltantes corresponden únicamente a datos en la categoría B, y que estos datos faltantes van desde los más pequeños a los más grandes. Esto quiere decir que los valores faltantes dependen sólo de la variable “V1” (la categoría) y no de la propia variable “V2”.
Para este mecanismo, y para el primero (MCAR), también podremos usar las técnicas que vamos a ver a continuación.
¿Cómo manejar los datos faltantes?
Estas técnicas se dividen en dos grandes grupos que son el descarte de datos y la imputación.
El descarte consiste simplemente en eliminar los registros que contengan datos faltantes, mientras que en la imputación lo que se busca es estimar el valor del dato faltante usando la información de los registros vecinos o la información presente en otras variables (o columnas) del set de datos.
En términos generales estas técnicas se pueden aplicar a datos faltantes aleatorios o completamente aleatorios, es decir que asumen un grado de aleatoriedad en el mecanismo responsable de la pérdida de los datos.
Sin embargo, para el caso de datos faltantes no aleatorios no es recomendable usar estas técnicas porque como les comenté antes la pérdida de datos en este caso es sistemática.
Entonces que ahora sí hablemos en detalle de los algoritmos más usados en cada caso cuando implementamos un proyecto de Machine Learning o Ciencia de Datos.
El descarte: la técnica más sencilla de todas
En el caso del descarte, la eliminación de datos la podemos hacer de dos formas. La primera se conoce como eliminación de la lista (listwise deletion) y consiste en remover del set de datos las filas que contengan datos faltantes, con la desventaja de que al eliminar la fila completa eliminaremos también algunos datos existentes, lo que puede llevar a una pérdida significativa de información:

La segunda forma es la eliminación por pares (pairwise deletion), que es un método menos agresivo que el anterior, pues en lugar de eliminar la fila completa se quitarán únicamente las casillas con el dato faltante. La ventaja es que preservaremos los datos conocidos, pero la desventaja es que podremos tener características (es decir columnas) con diferente cantidad de datos, lo que puede complicar el entrenamiento de un modelo de Machine learning pues el número de datos debe ser el mismo para cada característica:

De todos modos sugiero usar estos métodos con pinzas, porque si tenemos demasiados datos faltantes (generalmente más del 10%) estaremos cambiando la distribución de nuestro dataset y esto puede afectar el modelo de Machine Learning que estemos entrenando o el análisis que hagamos posteriormente. Por ejemplo, si estamos hablando de un problema de clasificación podríamos al final tener más datos completos de una categoría que de otra.
La imputación: ¿inventar datos?
Para evitar una pérdida significativa de datos lo mejor es usar la imputación. Y ojo, porque esto es diferente de inventar datos: al inventar no usamos ningún criterio, y el valor asignado será totalmente arbitrario. Pero en la imputación lo que hacemos es mirar el comportamiento de los datos vecinos para poder estimar el valor del dato faltante.
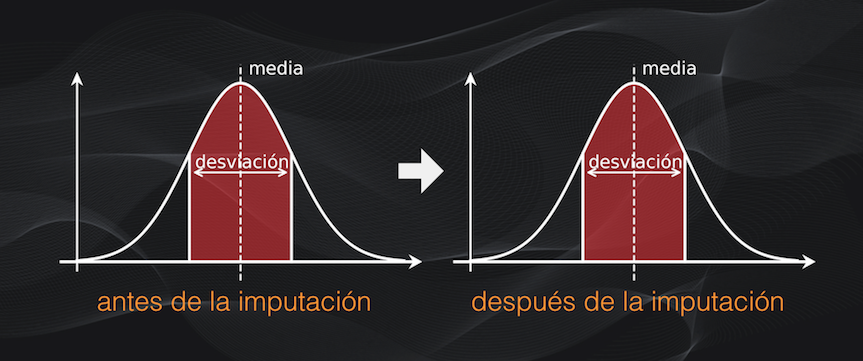
Idealmente esta imputación no debería cambiar la distribución de nuestros datos. Así que si originalmente teníamos una distribución normal (con forma de campana), entonces después de la imputación se debería mantener esta distribución original (en el artículo sobre el Análisis Exploratorio de Datos se discute en detalle el concepto de distribución):
Para esta imputación podemos usar dos técnicas: la imputación simple y la imputación múltiple, y en ambos casos sugiero, al igual que con el descarte, usarlas sólo si estamos seguros de que los mecanismos son datos faltantes completamente aleatorios o aleatorios.
La imputación simple
En la imputación simple se usa un algoritmo para hacer una única estimación y el valor obtenido se usa para reemplazar el dato faltante correspondiente. En este caso las tres técnicas más usadas en el Machine Learning y la Ciencia de Datos son: la imputación por la media o la mediana; la imputación por regresión y la imputación hot-deck.
La imputación por la media o la mediana es la más sencilla de todas: simplemente se toman los valores conocidos en la variable donde están los datos faltantes, se calculan la media o la mediana y se reemplazan los datos faltantes con cualquiera de estos dos valores. Aunque es muy fácil de implementar, este método tiene la desventaja de que al reemplazar muchos datos faltantes con un único valor estaremos cambiando la distribución de los datos:
Una alternativa es hacer la imputación por regresión. En este caso cada dato faltante es reemplazado con el valor predicho por un modelo de regresión. Para esto primero se combina la información de la columna con los datos faltantes con columnas en donde los datos están completos para así ajustar un modelo de regresión. Y luego se usa este modelo para predecir los datos faltantes:
Este método es mejor que la imputación por la media o la mediana, porque los datos faltantes no serán reemplazados por un mismo valor en todos los casos, lo que permite preservar la distribución de los datos. La desventaja es que para poder realizar cualquier tipo de regresión (regresión lineal, polinómica o regresión logística) debe haber algún tipo de correlación entre las variables que estamos usando para construir este modelo.
El tercer método de imputación simple es la imputación hot-deck. En este caso, el dato faltante es reemplazado con valores tomados de datos “cercanos” al dato faltante. Dentro de esta categoría el método más usado es el de k-vecinos más cercanos (o kNN por sus siglas en Inglés: k-Nearest Neighbors). Este algoritmo busca los k valores más cercanos (donde k es un número entero, como 2, 3, o 10 por ejemplo) y reemplaza el valor faltante con el promedio de estos vecinos:
La ventaja de este método es que es mucho más preciso que la media o la mediana, y puede funcionar en lugar de la regresión cuando los datos no están correlacionados. La desventaja es que si tenemos muchos datos se requiere bastante tiempo de cómputo, porque para completar cada dato faltante se debe calcular su distancia con respecto a cada uno de los demás datos del set.
La imputación múltiple: el algoritmo MICE
Una alternativa más robusta que todas las técnicas que vimos anteriormente es la imputación múltiple, que de hecho es una de las más usadas en la actualidad.
Y es que todas las técnicas de imputación simple tienen un gran problema: para reemplazar el dato faltante se fían de una única estimación. Es como intentar reemplazar la altura desconocida de una persona con el valor promedio de 1000 personas: ¡muy probablemente el valor resultante estará muy lejos de la altura real!.
Así que en lugar de hacer una sola estimación, en la imputación múltiple (como su nombre lo indica) se hacen múltiples estimaciones, que luego se combinan para producir un único valor, que será el usado para reemplazar el dato faltante correspondiente, con lo cual se puede disminuir el sesgo de la estimación.
El método de imputación múltiple más usado es el algoritmo de Imputación Múltiple con Ecuaciones Encadenadas (o MICE por sus siglas en Inglés: Multiple Imputation by Chained Equations).
En este algoritmo, de forma iterativa, se harán progresivamente cada vez mejores estimaciones de los datos faltantes. Inicialmente la primera estimación no es muy buena, pues se hace con la imputación por la media que vimos anteriormente, pero en los pasos restantes se aplica una regresión lineal entre pares consecutivos de columnas, y el procedimiento se repite una y otra vez hasta completar un número pre-definido de iteraciones. La idea es que progresivamente las estimaciones sean cada vez más precisas y se acerquen más y más al valor real:
Este algoritmo MICE es mucho más robusto que cualquiera de los de imputación simple, y en la práctica no cambia la distribución obtenida. Sin embargo tampoco es perfecto, porque para usarlo debemos garantizar que las variables están relacionadas linealmente. De no ser así debemos usar modelos estadísticos más sofisticados, o incluso entrenar algún modelo de machine learning para que realice la regresión.
Enlace de descarga de la guía
Suscríbete a la newsletter mensual de Codificando Bits y recibe el enlace de descarga de la guía en tu e-mail:
Conclusión
Bien, y con esto ya tenemos una guía completa de los métodos más usados para el manejo de datos faltantes. En resumen recordemos que lo primero es determinar el mecanismo que da origen a estos datos faltantes: si el mecanismo es aleatorio o completamente aleatorio (MAR o MCAR), podemos usar las técnicas que acabamos de ver.
Pero si el mecanismo es no aleatorio (MNAR) lo mejor es intentar recolectar nuevos datos si es posible, porque al aplicar cualquiera de estas técnicas podríamos tener un sesgo en la distribución del dataset resultante.
Si miramos en detalle las técnicas, creo que las más robustas son la de imputación simple con k-vecinos más cercanos, y por supuesto el algoritmo MICE para la imputación múltiple.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: