Redes Adversarias (Generative Adversarial Networks): explicación y tutorial en Python
En este post veremos una completa explicación y un tutorial acerca de las Redes Adversarias (o GAN: Generative Adversarial Networks) una nueva arquitectura del Machine Learning con la que progresivamente se han venido desarrollando impresionantes aplicaciones en el área de procesamiento de imágenes.
En el tutorial veremos cómo implementar una Red Adversaria en Python, capaz de generar imágenes artificiales de rostros humanos.
Al final del artículo se encuentra el enlace para descargar el set de datos y el código fuente.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
En posts anteriores hemos visto cómo usar las Redes Neuronales y las Redes Convolucionales para clasificar datos, o cómo implementar un Autoencoder para obtener una representación compacta de esos datos.
En este post hablaremos de una aplicación muy interesante de las Redes Neuronales y Convolucionales: la generación de datos. Esto se logra con una arquitectura conocida como Redes Adversarias (o GAN, por sus siglas en Inglés: Generative Adversarial Networks), que son tal vez uno de los desarrollos más llamativos del Deep Learning durante los últimos años, y que tienen aplicaciones principalmente en el procesamiento de imágenes y la visión por computador.
Con estas Redes Adversarias se logra, tras un proceso de entrenamiento, generar por ejempo imágenes totalmente artificiales que se asemejan a la distribución de los datos reales usados durante el entrenamiento.
Primero veremos en qué consiste una Red Adversaria y cómo se lleva a cabo el proceso de entrenamiento. Después veremos paso a paso cómo implementar de forma sencilla en una Red Adversaria en Python, capaz de generar rostros humanos artificiales muy similares a un rostro real.
En primer lugar veamos qué son las Generative Adversarial Networks o Redes Adversarias Generativas.
¿Qué son las Redes Adversarias?: una idea general
Las Redes Adversarias fueron propuestas por Ian Goodfellow en el año 2014.
En una red adversaria se tienen dos modelos (que pueden ser Redes Neuronales o Convolucionales) compitiendo: un Generador y un Discriminador:

La competencia entre estos dos modelos se puede ver a través de una analogía: el Generador es como un falsificador, que intenta producir billetes falsos sin que estos sean detectados, mientras que el Discriminador es como el policía, que intenta detectar estos billetes falsos:

Esta competición lleva a ambos equipos (falsificador y policía, o generador y discriminador) a mejorar sus métodos.
En el caso de las Redes Adversarias se busca que al final sea el falsificador quien gane este juego: ¡es decir que logre finalmente engañar al policía!

Las Redes Adversarias en detalle
Entendamos ahora esta idea de las Redes Adversarias en el contexto del Deep Learning.
Supongamos que entrenamos un primer modelo que llamaremos Discriminador (el policía) para que sea capaz de reconocer rostros humanos. Este discriminador será simplemente un clasificador, como por ejemplo una Red Convolucional.
Idealmente, si ingresamos una imagen con un rostro humano, la salida generada por el discriminador será igual a 1, mientras que si ingresamos otra imagen diferente, la salida será 0:

Ahora crearemos un segundo modelo, que llamaremos Generador (el ladrón) y nuestro objetivo es entrenarlo para que sea capaz de tomar una entrada aleatoria y a la salida generar algo muy parecido a una imagen de un rostro:

¡Pues estos dos modelos combinados reciben el nombre de Red Adversaria Generativa!
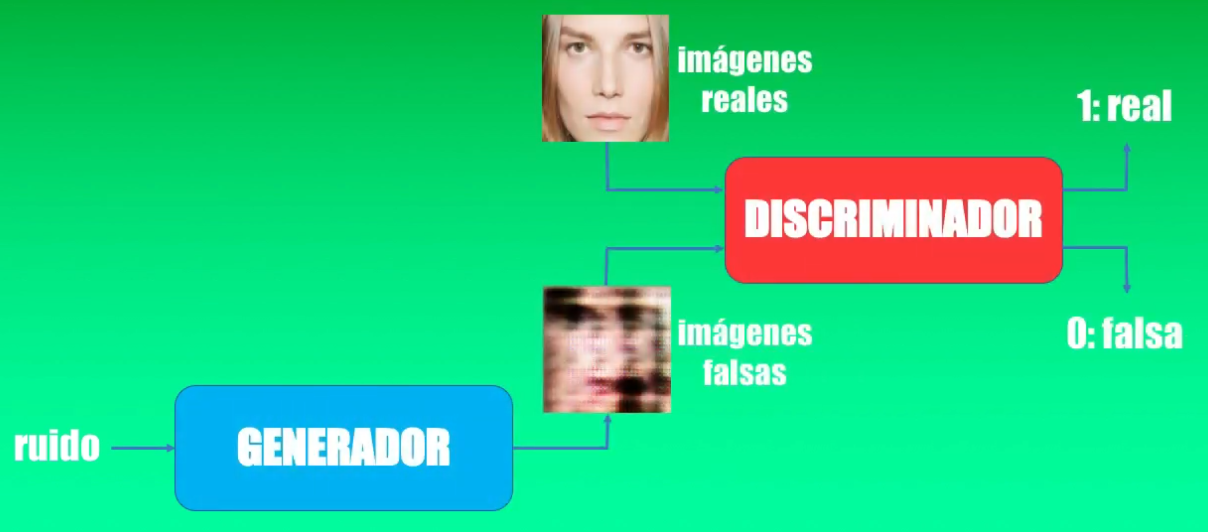
La idea es entrenar esos dos modelos simultáneamente buscando que al final sea el Generador el vencedor en esta competencia.
¿Y cómo podemos saber si este entrenamiento es adecuado? Pues en este caso debemos analizar el error del Discriminador, tanto con imágenes reales como con las imágenes falsas, obtenidas con el Generador.
Al inicio del entrenamiento es de esperar que las imágenes obtenidas con el Generador no sean similares a un rostro. Así, para el Discriminador resultará muy fácil diferenciar entre una imagen real y una imagen falsa, y por tanto el error en uno y otro caso será muy pequeño.
Sin embargo, a medida que avanza el proceso de entrenamiento, el Generador aprenderá poco a poco a producir imágenes cada vez más parecidas a un rostro humano:

Esto quiere decir que a medida que avanza el entrenamiento el Generador logrará “confundir” al Discriminador, y por tanto el error de dicho discriminador será cada vez más alto, lo cual quiere decir que no estará en capacidad de diferenciar claramente una imagen real de una falsa:
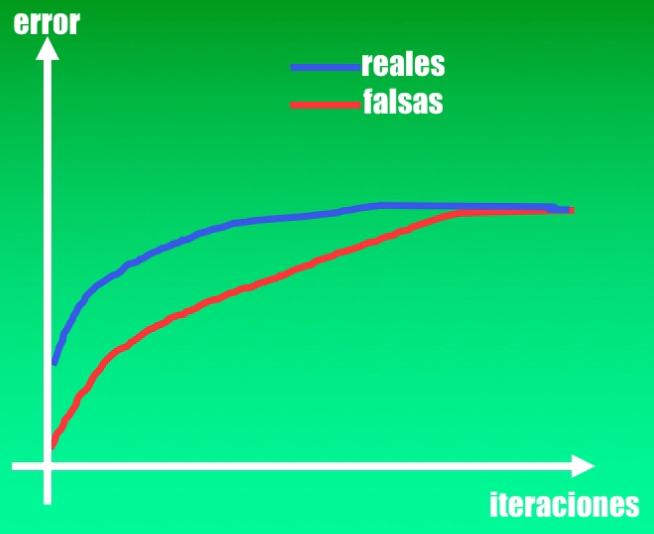
Así, al final del entrenamiento, idealmente la salida del Discriminador no será ni 0 (imagen falsa) ni 1 (imagen real), sino que será precisamente 0.5, lo cual quiere decir que habrá sido engañado por completo por el Generador.
Por su parte, en este caso podremos concluir que el Generador ha aprendido la distribución de los datos de entrada y por tanto ha aprendido a replicar con precisión esta distribución.
Veamos entonces cómo combinar estas ideas en un tutorial en Python, donde implementaremos una Red Adversaria capaz de generar rostros humanos.
Tutorial en Python: generación de rostros humanos con Redes Adversarias
1. Preparación del set de entrenamiento
Para este ejemplo usaremos un set de datos que contiene aproximadamente 3800 imágenes con rostros humanos, cada una con un tamaño de 128x128 y que han sido normalizadas en el rango de -1 a 1:

Para leer estos datos crearemos una sencilla función en Python:
import os
import numpy as np
from imageio import imread
def cargar_datos():
print('Creando set de entrenamiento...',end="",flush=True)
filelist = os.listdir(dataset)
n_imgs = len(filelist)
x_train = np.zeros((n_imgs,128,128,3))
for i, fname in enumerate(filelist):
if fname != '.DS_Store':
imagen = imread(os.path.join(dataset,fname))
x_train[i,:] = (imagen - 127.5)/127.5
print('¡Listo!')
return x_train
Y ahora la instanciamos para que se ejecute y podamos crear nuestro set:
x_train = cargar_datos()
2. Creación de la Red Adversaria
Por su parte, la Red Adversaria será creada usando capas convolucionales.
El Generador tomará un vector con 100 números aleatorios y será entrenado para generar imágenes de 128x128 que progresivamente serán cada vez más parecidas a una imagen de un rostro:

Por su parte, el Discriminador tendrá como entrada una imagen real o una imagen falsa, y a la salida entregará un número entre 0 y 1 indicando la categoría a la que pertenece la imagen de entrada (0: imagen falsa, 1: imagen real):

Para las arquitecturas del discriminador usaremos la arquitectura DC-GAN (Deep Convolutional Generative Adversarial Networks).
Bien, creemos inicialmente el Generador. Para ello haremos uso de la librería Keras, con la cual crearemos una función en Python (crear_generador).
Esta función inicia con un vector de 100 elementos que será conectado a una capa neuronal con 1024x4x4 elementos, que posteriormente será redimensionado a un volumen de 4x4x1024. Para esto usaremos los módulos Sequential y Dense de Keras:
from keras.models import Sequential, Model
from keras.layers import Dense, Reshape, Conv2DTranspose, BatchNormalization, Conv2D, LeakyReLU, Flatten, Input
from keras.layers.core import Activation
from keras.optimizers import Adam
OPTIMIZADOR = Adam(lr=0.0002, beta_1=0.5)
TAM_ENTRADA = 100
ERROR = 'binary_crossentropy'
LEAKY_SLOPE = 0.2
def crear_generador():
modelo = Sequential()
modelo.add(Dense(1024*4*4, use_bias=False, input_shape=(TAM_ENTRADA,)))
En las capas restantes usaremos la convolución inversa (Conv2DTranspose) hasta progresivamente llegar al volumen deseado de 128x128x3 (es decir las dimensiones de la imagen a generar):
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
modelo.add(Reshape((4,4,1024)))
#Tamaño resultante: 4x4x1024
modelo.add(Conv2DTranspose(512,(5,5),strides=(2,2),padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 8x8x512
modelo.add(Conv2DTranspose(256,(5,5),strides=(2,2),padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 16x16x256
modelo.add(Conv2DTranspose(128,(5,5),strides=(2,2),padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 32x32x128
modelo.add(Conv2DTranspose(64,(5,5),strides=(2,2),padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 64x64x64
En el código anterior podemos ver que en cada una de las capas, exceptuando la de salida, hemos usado la función de activación LeakyReLU, una variante de la función ReLU convencional pero que no elimina completamente los valores de entrada negativos.
También podemos ver que en todas las capas, exceptuando la de salida, hemos usado BatchNormalization “batch normalization”, que garantiza que a la salida de cada capa los valores tendrán un valor medio igual a cero y una desviación estándar igual a 1, lo que permitirá la convergencia del algoritmo de optimización durante el entrenamiento.
Finalmente, en la capa de salida usaremos la función de activación tangente hiperbólica, para obtener imágenes generadas con pixeles en el rango de -1 a 1 (el mismo rango usado en las imágenes de entrenamiento reales):
modelo.add(Conv2DTranspose(3, (5,5),strides=(2,2),padding='same', use_bias=False))
modelo.add(Activation('tanh'))
#Tamaño resultante: 128x128x3
Este Generador será entrenado usando el algoritmo Adam que es una variante del Gradiente Descendente pero que requiere menos iteraciones para lograr la convergencia.
El error a usar será la entropía cruzada, que es la misma métrica usada en la Regresión Logística, pues en este caso se tienen precisamente dos categorías (imagen falsa o imagen real)
modelo.compile(optimizer=OPTIMIZADOR, loss=ERROR)
return modelo
donde las variables OPTIMIZADOR y ERROR fueron creadas al inicio de la función.
Y bien, con esto ya tenemos toda la estructura de la función. Así que simplemente la instanciamos para tener listo nuestro Generador:
generador = crear_generador()
Ahora continuamos con el Discriminador, que será también una Red Convolucional prácticamente opuesta a la arquitectura del Generador.
Para ello crearemos la función crear_discriminador que inicia definiendo que la entrada será una imagen de 128x128x3 (el mismo tamaño de la imagen producida por el Generador):
def crear_discriminador():
modelo = Sequential()
modelo.add(Conv2D(64, (5,5), strides=(2,2), padding='same', input_shape=(128,128,3),
use_bias=False))
y luego agregaremos las capas convolucionales Conv2D, que se encargarán de progresivamente reducir el tamaño de la entrada (ancho y alto) y de incrementar el número de características extraídas de la imagen, tal como lo hace una Red Convolucional convencional:
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 64x64x64
modelo.add(Conv2D(128, (5,5), strides=(2,2), padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 32x32x128
modelo.add(Conv2D(256, (5,5), strides=(2,2), padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 16x16x256
modelo.add(Conv2D(512, (5,5), strides=(2,2), padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 8x8x512
modelo.add(Conv2D(1024, (5,5), strides=(2,2), padding='same', use_bias=False))
modelo.add(BatchNormalization(momentum=0.3))
modelo.add(LeakyReLU(alpha=LEAKY_SLOPE))
#Tamaño resultante: 4x4x1024
modelo.add(Flatten())
modelo.add(Dense(1, activation='sigmoid', use_bias=False))
Al igual que en el caso del Generador, podemos ver que en este Discriminador también hemos usado BatchNormalization y las activaciones LeakyReLU, exceptuando la capa de salida que será sigmoidal para obtener valores entre 0 y 1 (pues recordemos que el Discriminador es un clasificador).
Para entrenar este Discriminador usaremos exactamente el mismo optimizador (ADAM) y la misma función de error (la entropía cruzada):
modelo.compile(optimizer=OPTIMIZADOR, loss=ERROR)
return modelo
Al igual que en el caso anterior, debemos instanciar la función que acabamos de crear para tener listo nuestro Discriminador:
discriminador = crear_discriminador()
Una vez creados el Generador y el Discriminador, resulta sencillo crear la Red Adversaria. Usamos inicialmente Sequential para crear el contenedor, y luego agregamos el Generador y posteriormente el Discriminador:
def crear_GAN(generador, discriminador):
modelo = Sequential()
modelo.add(generador)
discriminador.trainable = False
modelo.add(discriminador)
modelo.compile(optimizer=OPTIMIZADOR, loss=ERROR)
return modelo
gan = crear_GAN(generador, discriminador)
En un momento veremos el significado de la línea discriminador.trainable = False.
Bien, teniendo lista la Red Adversaria, veamos cómo realizar el entrenamiento.
3. Entrenamiento de la Red Adversaria
Para el entrenamiento vamos a usar lotes de 128 imágenes y un total de 5000 iteraciones:
TAM_LOTE = 128
N_ITS = 5000
n_lotes = x_train.shape[0]/TAM_LOTE
Recordemos que la variable x_train contiene nuestro set de entrenamiento (creado en la primera parte de este tutorial).
La dinámica de entrenamiento en este caso es diferente a la que usamos convencionalmente cuando se entrenan un simple clasificador (como una Red Neuronal o una Convolucional).
En el caso de las Redes Adversarias debemos llevar a cabo estos pasos:
- Entrenar el Discriminador
- “Congelar” los coeficientes del Discriminador
- Entrenar únicamente el Generador
- “Descongelar” los coeficientes del Discriminador
- Repetir los pasos 1 a 4 por el número de iteraciones que se vayan a usar el entrenamiento
Es por esto que inicialmente hemos “congelado” el Discriminador (usando la línea de código discriminador.trainable = False en la sección anterior), para durante el entrenamiento activar y desactivar su entrenamiento en cada iteración.
Lo debemos hacer de esta forma, pues lo que se busca es generar una competencia entre los dos modelos: el generador y el discriminador, con el objetivo de que el generador que estamos entrenando logre incrementar el valor del error del discriminador (es decir, ¡que logre confundirlo!).
Como en cada iteración se deben seguir precisamente los pasos 1 al 4 descritos anteriormente, no resulta posible acudir al método fit de Keras que convencionalmente se usa para entrenar las Redes Convolucionales. En lugar de esto usaremos el método train_on_batch, que nos permite controlar lo que ocurrirá en cada iteración del entrenamiento.
Así, en primer lugar crearemos dos lotes de 128 imágenes cada uno: uno con imágenes falsas obtenidas con el Generador y otro con imágenes reales (provenientes del set de entrenamiento):
for i in range(1,N_ITS+1):
print("Epoch " + str(i))
# Crear un "batch" de imágenes falsas y otro con imágenes reales
ruido = np.random.normal(0,1,[TAM_LOTE,TAM_ENTRADA])
batch_falsas = generador.predict(ruido)
idx = np.random.randint(low=0, high=x_train.shape[0],size=TAM_LOTE)
batch_reales = x_train[idx]
Una vez generados estos lotes, entrenamos el discriminador con cada uno de ellos.
En primer lugar “descongelamos” los coeficientes del discriminador para permitir su entrenamiento, usando “trainable = True”:
discriminador.trainable = True
Después entrenamos el discriminador con estos lotes usando train_on_batch, generando para cada lote las categorías correspondientes: unos para cada imagen real (np.ones) y ceros para cada imagen falsa (np.zeros):
dError_reales = discriminador.train_on_batch(batch_reales,
np.ones(TAM_LOTE)*0.9)
dError_falsas = discriminador.train_on_batch(batch_falsas,
np.zeros(TAM_LOTE)*0.1)
Y finalmente, “congelamos” de nuevo los coeficientes del discriminador para que estos no sean modificados al entrenar el generador. Para ello usamos “Trainable = False”:
discriminador.trainable = False
Para entrenar el Generador podemos usar la GAN (que contiene tanto al Discriminador como al Generador), y le presentamos a la entrada el vector de ruido aleatorio (que es precisamente la entrada al Generador).
Podemos usar la Red Adversaria en lugar del Generador pues al haber congelado los coeficientes del Discriminador solo los coeficientes de este generador serán modificados. Nuevamente en este caso, debemos usar train_on_batch para el entrenamiento:
ruido = np.random.normal(0,1,[TAM_LOTE,TAM_ENTRADA])
gError = gan.train_on_batch(ruido, np.ones(TAM_LOTE))
4. Generación de rostros artificiales con la Red Adversaria entrenada
Finalmente, podemos usar el generador para obtener algunos ejemplos de imágenes falsas en diferentes etapas del entrenamiento (en este caso cada 1000 iteraciones). Podemos igualmente almacenar en disco duro el modelo obtenido:
if i==1 or i%1000 == 0:
graficar_imagenes_generadas(i,generador)
generador.save('generador.h5')
Al ejecutar el código podemos ver cómo es la evolución del entrenamiento a través de las imágenes falsas obtenidas con el generador. Vemos que en la primera iteración inicia con imágenes totalmente aleatorias, pero a medida que avanza el entrenamiento progresivamente se obtendrán imágenes que cada vez se parecen más a un rostro humano:

¡Recordemos que estas imágenes artificiales están siendo generadas a partir de un vector con 100 datos totalmente aleatorios!
Para finalizar, y con el modelo ya entrenado, podemos generar algunos ejemplos de rostros:

Podemos observar que muchas de estas imágenes generadas tienen un alto grado de similitud con las imágenes de rostros reales. Es realmente impresionante el resultado.
Datos y código fuente
En este enlace de Github podrás descargar el set de datos y el código fuente de este tutorial.
Conclusión
Bien en este video hemos visto en qué consisten las Redes Adversarias Generativas, que están conformadas por dos redes (neuronales o convolucionales): un Generador y un Discriminador. Durante el entrenamiento, estos dos elementos compiten, y el objetivo final es lograr que el Generador sea capaz de engañar al Discriminador, produciendo datos muy similares a los de la distribución original usada durante el entrenamiento.
El ejemplo que vimos permite tomar un set de datos que contiene rostros humanos reales, y tras el entrenamiento vimos que el Generador aprende esta distribución y es capaz de producir rostros artificiales a partir de una entrada que, en este caso, era simplemente un arreglo con números aleatorios.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: