Redes Transformer (... o el fin de las Redes Recurrentes)
En este post vamos a ver cómo funcionan en detalle las Redes Transformer, un nuevo tipo de red neuronal que promete convertirse en un hito en el ya vertiginoso avance del Machine Learning. Además entenderemos porqué han desbancado por completo a las Redes Recurrentes, que hasta hace poco dominaban el campo del Natural Language Processing.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube encontrarán el video de este post:
Introducción
Desde hace aproximadamente tres años se viene gestando otra gran revolución en la Inteligencia Artificial.
En febrero de 2019 OpenAI creó el modelo GPT-2 capaz de sintetizar texto muy similar al que generaría un ser humano. El pasado mes de mayo lanzó GPT-3, un modelo de natural language processing 10 veces más grande que su antecesor y mucho más poderoso: alimentado con tan solo una corta frase de inicio, este modelo de Machine Learning es capaz de escribir una historia completa, de manera bastante convincente, siendo incluso capaz de engañar a un ser humano.
Y en Abril de este año Facebook liberó el código fuente de BlenderBot, un chatbot que se percibe más humano en una conversación que una persona real. Y a comienzos de este mes también presentó TransCoder, un modelo capaz de tomar código en Python y convertirlo en código C++, ¡y esto a pesar de que nunca fue entrenado para esta tarea!
Detrás de esta nueva revolución están las Redes Transformer, que nacieron en el contexto del Procesamiento del Lenguaje Natural (o NLP por sus siglas en Inglés: Natural Language Processing), un área del Machine Learning que busca que los computadores logren entender, interpretar y manipular el lenguaje humano.
¿Y por qué no las Redes Recurrentes?
Hasta hace muy poco las Redes Recurrentes dominaban esta área, pues el lenguaje humano es precisamente una secuencia de palabras. Y estas redes se especializan en procesar secuencias.
Pero estas redes recurrentes tienen un gran inconveniente: tienen una memoria de corto plazo.
Por ejemplo, para la generación de texto la red podrá producir frases relativamente cortas y bastante coherentes. Pero cuando la secuencia generada es extensa, la red no está en capacidad de tener como referencia el texto que apareció al inicio, y así el texto generado no será del todo coherente:
Además el texto es procesado de manera secuencial, es decir palabra por palabra.
Por el contrario, las Redes Transformer tienen una memoria de mucho más largo plazo. Pues logran analizar secuencias muy extensas usando un mecanismo que se llama atención y adicionalmente logran procesar toda la secuencia en paralelo, y no en serie como ocurre con las Redes Recurrentes.
Así que veamos en detalle en qué consiste la Red Transformer
La Red Transformer
La Red Transformer descrita en el artículo de 2017 Attention is all you need, desarrollado por investigadores de Google, y nacieron inicialmente como una alternativa al problema de la traducción de texto de un idioma a otro.
En estas redes la totalidad de la secuencia de entrada es procesada en paralelo por la red, a diferencia de las Redes Recurrentes en donde se procesan uno a uno (es decir de forma serial) los elementos de la secuencia.
Esta secuencia es inicialmente convertida en una representación numérica usando un embedding
Después se añade una codificación de posición y los vectores resultantes ingresan a la etapa de codificación, que se encarga de extraer la información mas relevante de la secuencia en su idioma original.
La salida de esta etapa se conecta al decodificador, que toma esta información para generar secuencialmente el texto traducido al segundo idioma.
Aunque tiene muchos elementos realmente es sencillo entender cómo funciona. Veamos entonces en detalle cada módulo de esta red.
El embedding de entrada
Primero está el bloque embedding, que es simplemente un algoritmo que convierte el texto en una serie de vectores, o tokens, es decir en una representación numérica que puede ser “comprendida” por la red.
El codificador de posición
Como la secuencia se procesa en paralelo es necesario indicarle a la red el orden en el que se encuentran las palabras dentro del texto. Esto se logra con el codificador de posición.
Este codificador genera una serie de vectores que se sumarán a los tokens, y que indican la posición relativa de cada token dentro de la secuencia. Para esto se usan funciones senoidales para las posiciones pares, y cosenoidales para las impares, con lo que cada vector generado tendrá un patrón numérico único con la información de la posición.
Codificación y el bloque atencional
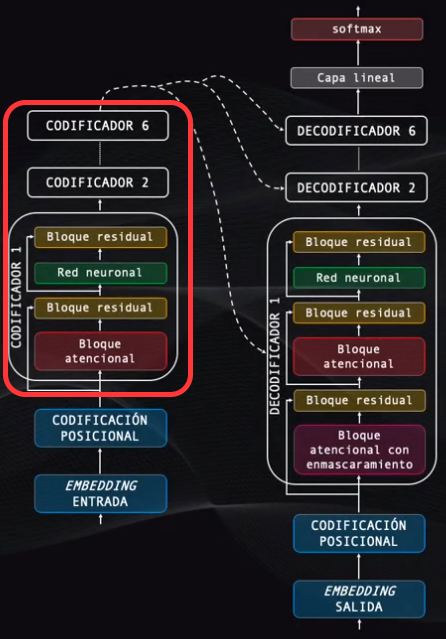
Ahora viene el bloque de codificación, que contiene seis codificadores, todos con una estructura idéntica. Analicemos en detalle uno de estos codificadores.
Cada codificador tiene cuatro elementos: un bloque atencional, un bloque de conexión residual, una red neuronal y otro bloque de conexión residual:
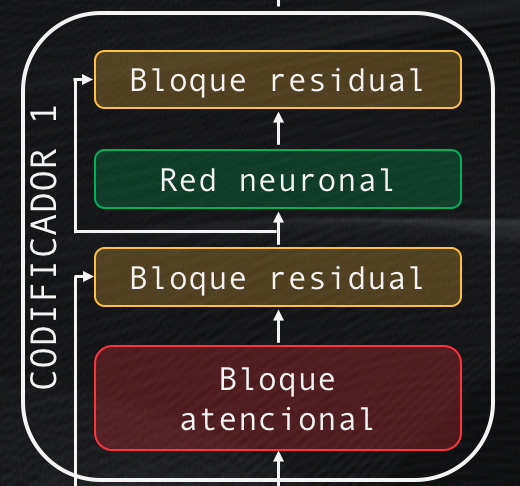
Veamos en detalle el bloque atencional, que es tal vez el más importante de toda la red, pues se encarga de analizar la totalidad de la secuencia de entrada (recordemos que la red la procesa de manera simultánea) y de encontrar relaciones entre varias palabras de esta secuencia.
Por ejemplo, si el texto de entrada es “I love Italian food”, podemos ver que hay al menos dos posibles asociaciones entre palabras: el verbo “love” y el sujeto (“I”) y el sustantivo “food” asociado al adjetivo “Italian”. Pero además entre estas dos frases (I Love e Italian Food) también hay una asociación:

Así, lo que hace el bloque atencional es expresar numéricamente las relaciones que existen a diferentes niveles dentro de la secuencia, y luego codifica cada una de ellas con esta información del contexto, indicando así cuáles son los elementos del texto a los que se deben prestar más atención al momento de hacer la traducción.
Esta es precisamente la manera como las redes transformer “comprenden” este contexto para codificar adecuadamente cada palabra.
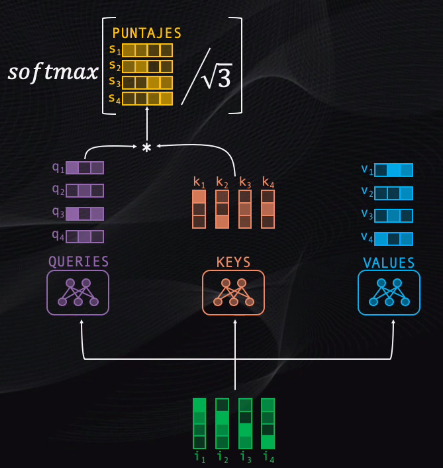
Para lograr esto en primer lugar los tokens se llevan simultáneamente a tres pequeñas redes neuronales, entrenadas para calcular los vectores “query”, “key” y “value”. Estos vectores son simplemente tres representaciones alternativas de los tokens originales:
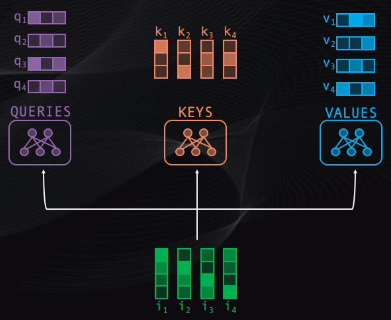
Después de esto se toma el query de cada token y se compara con cada uno de los keys existentes. Esta comparación es simplemente una multiplicación de vectores, y con esto se obtendrá un puntaje que mide el grado de asociación entre pares de palabras.
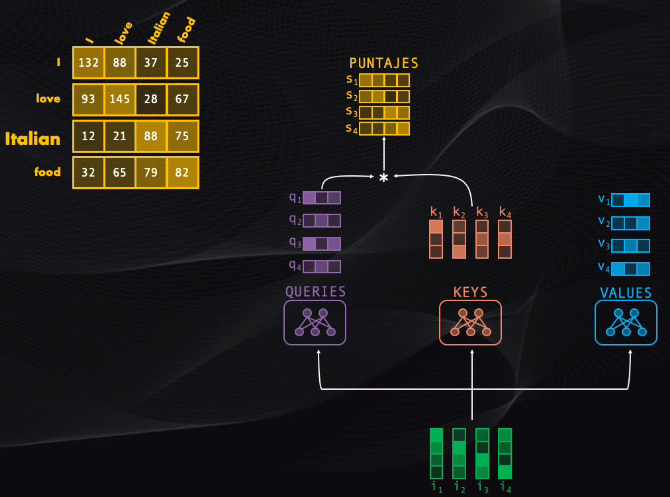
Así, para el caso de la frase que queremos traducir, si analizamos la palabra “Italian” los puntajes obtenidos indican que al codificar este token se le debería prestar más atención a la propia palabra “Italian” seguida por la palabra “food”, y se debería enfocar menos en las palabras “love” y “I”, que tienen los menores puntajes.
La idea es ahora usar estos puntajes para ponderar cada uno de los vectores values, indicando así la importancia de cada palabra al momento de la codificación de los tokens.
Para poder hacer esto se deben escalar los puntajes, dividiéndolos primero entre el tamaño de cada vector, y luego llevándolos a una función softmax. Esta función permite simplemente representar cada puntaje como una probabilidad entre cero y uno:
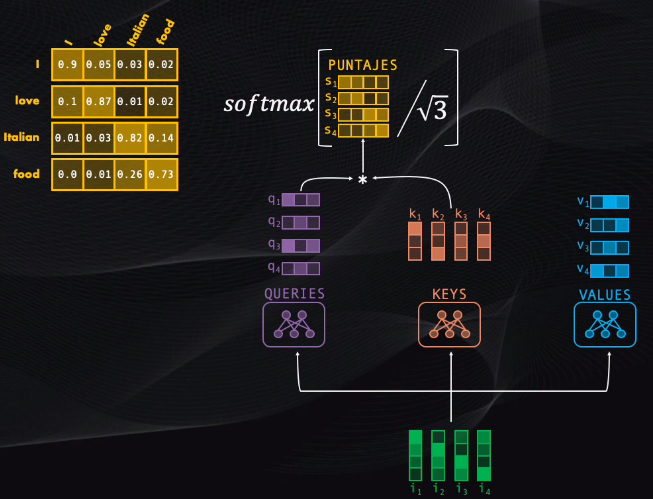
Un valor cercano a uno indica que la red debe prestarle más atención a ese token en particular, y un valor cercano a 0 que la palabra no es muy relevante.
Finalmente, se debe condensar toda esta información resultante de la comparación en un solo vector por cada token. Así que tomamos la matriz de puntajes que acabamos de obtener y la multiplicamos por la matriz de values: el resultado serán cuatro nuevos tokens, que contendrán la codificación de la información de contexto más relevante para cada palabra de la secuencia:
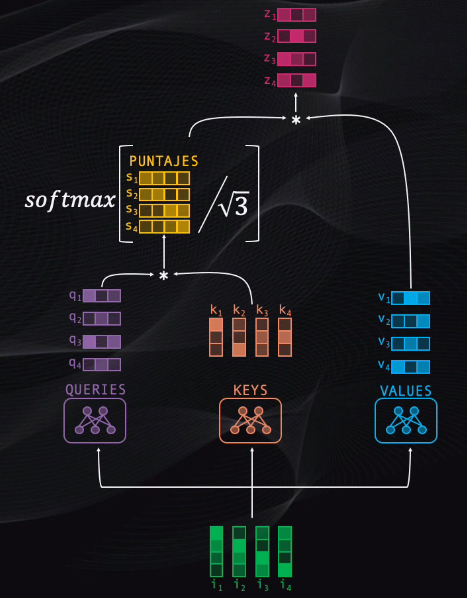
Así que, en resumen, el bloque atencional toma los tokens iniciales y codifica en los tokens resultantes los elementos de la secuencia a los que se debe dar más relevancia.
Sin embargo recordemos que en nuestra frase original encontramos, además de asociaciones entre palabras, asociaciones entre frases: para traducir la porción “Italian food” se necesita prestar atención a “I love”.
Así que un solo bloque atencional no es suficiente. Al usar múltiples bloques atencionales es posible detectar y codificar asociaciones entre palabras y grupos de palabras a diferentes niveles.
Las salidas de estos bloques se combinan en una última red neuronal que condensa toda la información resultante en un único vector para cada token de entrada:
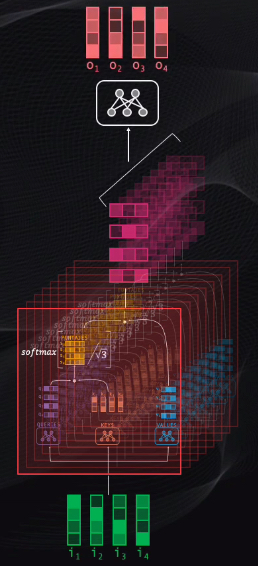
¡Y listo, este es el bloque atencional! Si me siguieron hasta acá y si entendieron esta parte ya tenemos el 99% de la red transformer lista, los demás bloques son menos complicados, así que los revisaremos rápidamente.
Codificación y el bloque residual
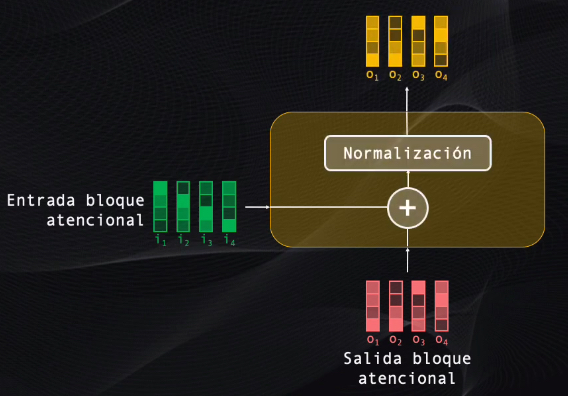
Bien, sigue el bloque residual. A este bloque se llevan tanto la entrada como la salida del bloque atencional, y esto se hace pues la red es muy profunda y si tan solo se enviara la salida la información progresivamente se degradaría y esto dificultaría el entrenamiento y desempeño de la red.
Esta etapa toma los dos datos, los suma y luego los normaliza para que tengan la escala adecuada requerida por el siguiente bloque:
Codificación: red neuronal y otro bloque residual
Después de esto tenemos una red neuronal seguida por un bloque residual:
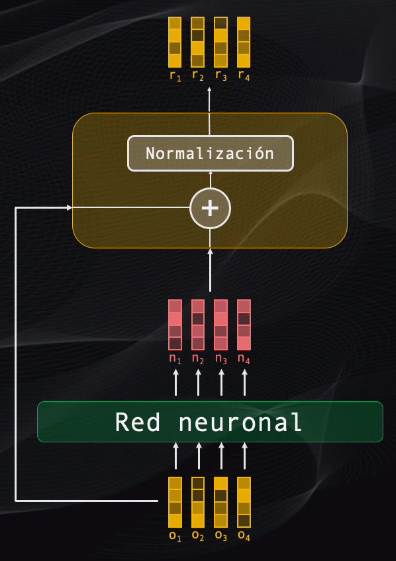
La red neuronal procesa en paralelo todos los vectores de la secuencia, tomando la información atencional de las capas anteriores y consolidándola en una única representación. La entrada y la salida de esta red neuronal son luego llevadas a un bloque residual que tiene exactamente las mismas características del bloque anterior: una suma seguida por una normalización de los datos.
Codificación: resultado final
Y con esto está listo el primer codificador.
Así que en resumen este bloque toma los tokens de entrada, los procesa en paralelo y entrega a la salida una representación que contiene información atencional sobre las diferentes relaciones entre palabras o grupos de palabras de la secuencia, importantes al momento de la traducción:
Y este proceso se repite para los codificadores restantes, que son idénticos en estructura al codificador que acabamos de analizar.
Decodificación
Ahora nos enfocamos el segundo bloque importante de la red transformer, que se encarga de hacer la traducción:
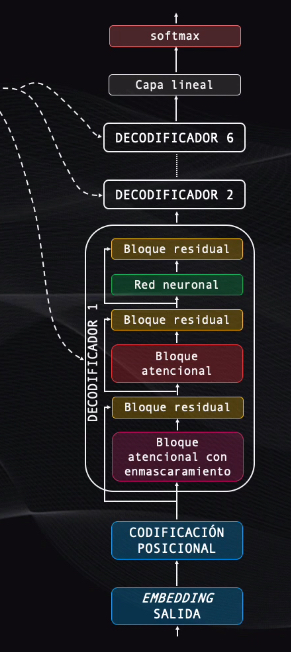
En primer lugar tenemos los bloques de embedding de salida y un codificador posicional, que cumplen exactamente la misma función de los bloques que vimos en la etapa de codificación.
Luego viene el decodificador, que es muy similar al bloque de codificación: en total cuenta con 6 decodificadores, cada uno de ellos conectado al codificador, lo que permite conocer la información atencional de la entrada, en el idioma original, para poder realizar la traducción.
Cada decodificador es similar a los bloques de codificación que vimos anteriormente: cuenta con bloques atencionales, residuales y redes neuronales que tienen la misma estructura de los codificadores. Sin embargo tienen un bloque atencional de enmascaramiento y un bloque residual adicionales.
Luego viene una capa lineal que, junto con la capa softmax, permite generar una a una las palabras de la secuencia de salida.
Veamos entonces cómo funciona paso a paso la decodificación.
Decodificación: bloque atencional con enmascaramiento
La traducción comienza con la palabra clave “inicio”, la cual es codificada con el embedding y posicionalmente.
Al ingresar al primer decodificador es procesada por el bloque atencional de enmascaramiento. Este bloque es prácticamente idéntico al bloque atencional visto anteriormente: codifica la relación entre diferentes elementos de la secuencia de salida, usando los queries, keys y values vistos anteriormente:
Pero con una diferencia importante: como se está generando cada palabra de manera secuencial, una a una, el decodificador debe prestar atención únicamente a la palabra generada actualmente y a las anteriores, no a las futuras.
Por ejemplo, si en la secuencia traducida nos ubicamos en la palabra “la”, el decodificador debería tener acceso a esta palabra y a “amo”, pero no a palabras que aparecerán posteriormente en la secuencia (“comida” e “italiana”):
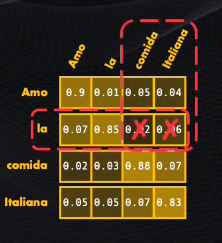
Así que para evitar esto se agrega un bloque que enmascara, es decir que simplemente hace cero, las palabras a las que durante la decodificación no se debe prestar atención:

Al igual que con el codificador, en este caso también se emplean múltiples bloques atencionales para detectar relaciones a diferentes niveles.
Decodificación: el bloque atencional
Todos los bloques residuales, así como la red neuronal de este decodificador funcionan de forma idéntica a como ocurría en los codificadores.
Así que nos enfocaremos ahora en el bloque atencional que en este caso tiene la misma estructura pero un funcionamiento ligeramente diferente al del codificador.
Este bloque enfoca su atención tanto en la secuencia original como en la de salida y para ello toma la salida del codificador y las lleva a las redes “queries” y “keys”, mientras que el nodo “values” usa como entrada el dato proveniente del bloque residual anterior:
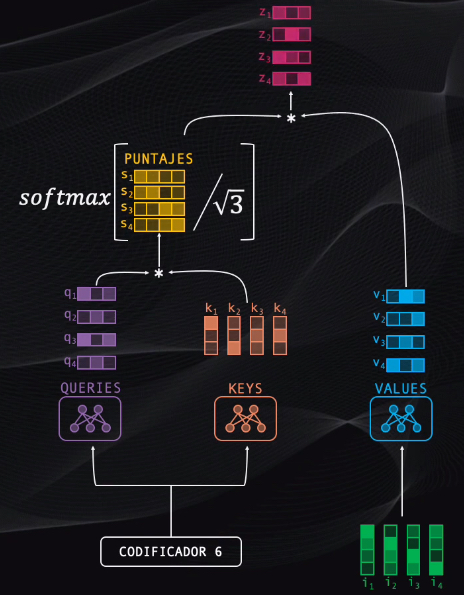
Es de esta manera como el codificador le indica al decodificador a qué elementos debe prestar más atención al momento de generar la secuencia de salida.
De nuevo, se usan múltiples bloques atencionales de manera simultánea para codificar asociaciones a diferentes niveles.
Bien, y ya tenemos el primer decodificador.
Decodificación: múltiples decodificadores y etapas de salida
Este bloque se replica un total de seis veces, y al final genera un vector con cantidades numéricas, y lo único que falta es convertirlo en una palabra:
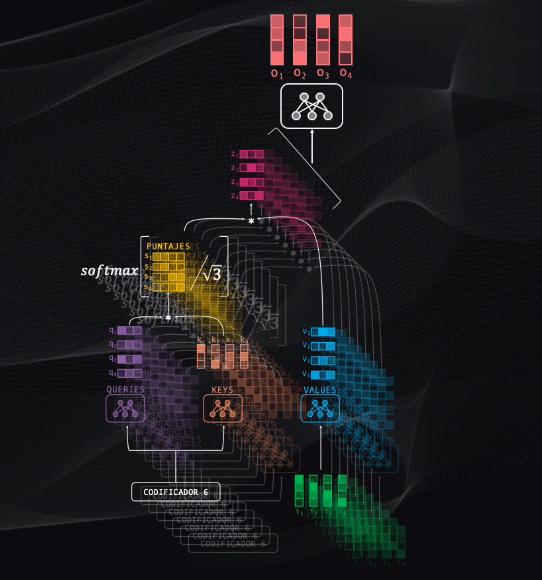
Para eso se usa en primer lugar la capa lineal, que es simplemente una red neuronal que toma el vector producido por el decodificador y lo transforma en un vector mucho más grande.
Por ejemplo, si el traductor aprende 10000 palabras (es decir el tamaño del vocabulario), entonces el vector de salida de la capa lineal tendrá precisamente 10000 elementos.
La capa softmax toma cada elemento de este vector y lo convierte en una probabilidad, todas con valores positivos entre 0 y 1. La posición con la probabilidad más alta será seleccionada y la palabra asociada con dicha posición será precisamente la salida del modelo en ese instante de tiempo:

Y el proceso se repite hasta generar la totalidad de la secuencia de salida.
Conclusión
Y listo, esta es la Red Transformer. Aunque para analizarla miramos el caso particular de la traducción, realmente esta red funciona con cualquier tipo de aplicación de NLP, como por ejemplo la generación de texto o la sumarización.
Bien, esto es todo por el momento. En próximos posts de esta serie veremos varios tutoriales sobre cómo usar esta arquitectura para diferentes tipos de aplicaciones del procesamiento del lenguaje natural.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: