¿Se requiere SQL para trabajar en Machine Learning?
SQL es un lenguaje de programación con más de 40 años, y el Machine Learning es un área en constante evolución. ¿Qué tiene que ver lo uno con lo otro? Pues en este artículo les contaré por qué conocer SQL resulta fundamental en el Machine Learning.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
S-Q-L o “sequel” es un lenguaje de programación que tiene más de 40 años, y que muuuchos consideran en desuso.
Pero a pesar de esto es, después de Python, tal vez uno de los lenguajes de programación que sin duda debe estar en la caja de herramientas de todos los que quieran un trabajo en el área del Machine Learning o en general en la Ciencia de Datos.
Así que a continuación veremos las seis razones por las cuales considero que aprender y manejar SQL resulta fundamental en estas áreas. Además veremos en detalle qué es SQL y les compartiré una guía para que fácilmente puedan comenzar a incorporarlo en sus proyectos de Machine Learning y Ciencia de Datos.
¿Qué relación hay entre el Machine Learning y SQL?
“El Machine Learning es la ciencia (y el arte) de programar computadores para que puedan aprender de los datos”. Esta es una definición de Aurélien Gerón en su libro “Hands on Machine Learning”.
Y en esta frase hay un elemento súper importante: los datos. Sobre los datos descansa toda la teoría y todos los desarrollos del Machine Learning. Los datos, y cómo interpretarlos y aprender de ellos, han sido la razón de la evolución y de los logros impresionantes del Machine Learning durante sus más de 60 años de historia.
Cualquier desarrollo que se haga en el Machine Learning, sea en la academia o en la industria, parte precisamente de los datos. Así que es fundamental tener herramientas que permitan fácilmente acceder a esos datos.
Y los tipos de datos usados en el Machine Learning vienen en dos sabores: los no estructurados (como las imágenes, el audio y el video) y los estructurados: es decir los que vienen almacenados en formato tabular, que en el mundo real se encuentran en bases de datos (y no en un único archivo como usualmente los podemos encontrar cuando estamos apenas iniciando en el Machine Learning).
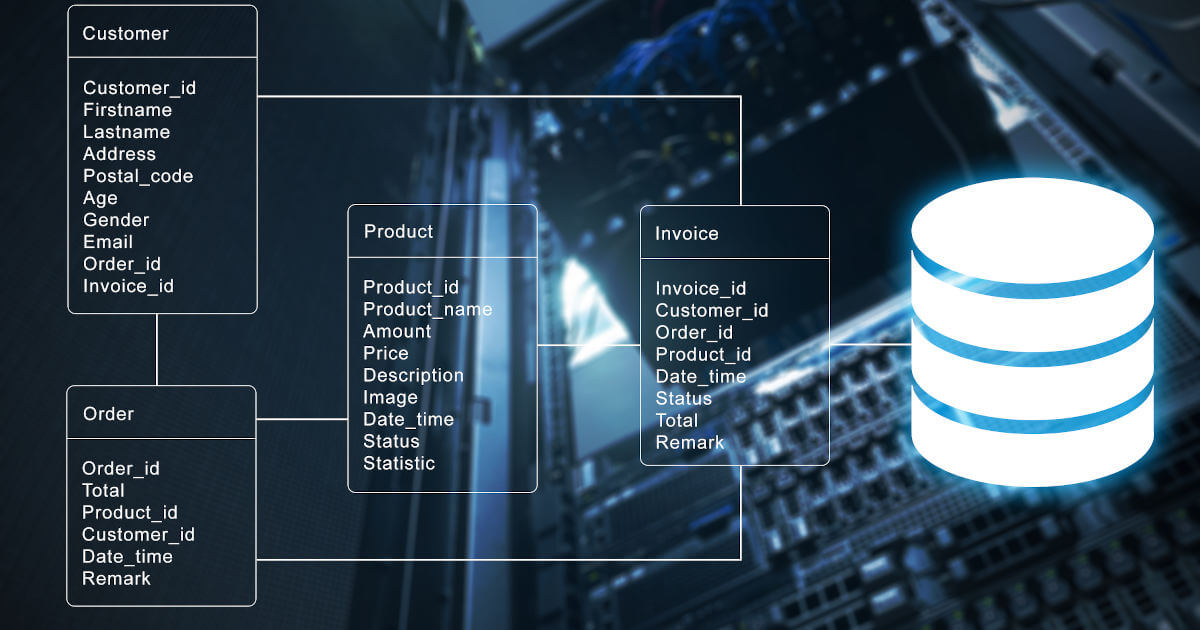
Y es acá donde entra SQL, el estándar usado actualmente en la mayor parte de las bases de datos corporativas a nivel mundial.
De hecho, el último reporte del 2020 hecho por Kaggle, que resulta de una encuesta aplicada a más de 60.000 profesionales de 171 países y que trabajan en las áreas del Machine Learning y la Ciencia de Datos, demuestra que después de Python, SQL es el segundo lenguaje más usado en el mundo laboral en estas áreas:
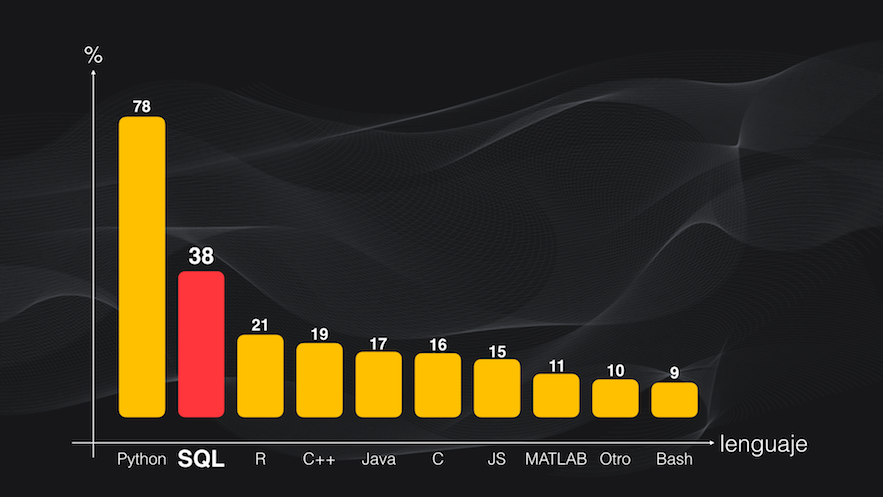
Así que, sin duda alguna, y a pesar de que es un lenguaje bastante “antiguo” y subestimado en la actualidad, SQL es fundamental en el día a día para el desarrollo de modelos y sistemas de Machine Learning.
¿Qué es SQL?
En unos momentos veremos en detalle las seis principales razones por las cuales creo que este lenguaje es esencial en el Machine Learning Engineering. Pero por ahora veamos más en detalle qué es SQL.
Pues en términos simples SQL es un lenguaje para realizar consultas (o “queries” en inglés, de ahí el nombre del lenguaje) en bases de datos relacionales.
¿Y qué es una base de datos relacional? Pues es una base de datos donde la información está almacenada en tablas, pero la información entre cada una de estas tablas está interrelacionada, de allí el término relacional.
Por ejemplo, supongamos que estamos desarrollando un sistema de Machine Learning para un hospital que quiere hacer el seguimiento a varios de sus pacientes y la información está almacenada en una base de datos que contiene cuatro tablas, cada una con miles de registros que contienen información de los pacientes, los médicos, las citas médicas y los medicamentos suministrados.
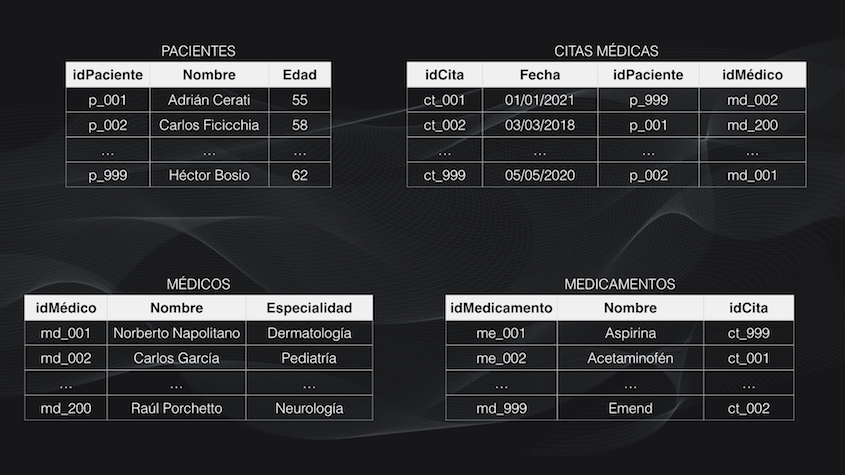
Aunque de entrada parecen tablas independientes en realidad podemos ver que, por ejemplo, la tabla de pacientes se relaciona con la de las citas médicas a través del ID del paciente, y que a su vez la tabla de las citas médicas se relaciona con la de medicamentos a través del ID de la cita:
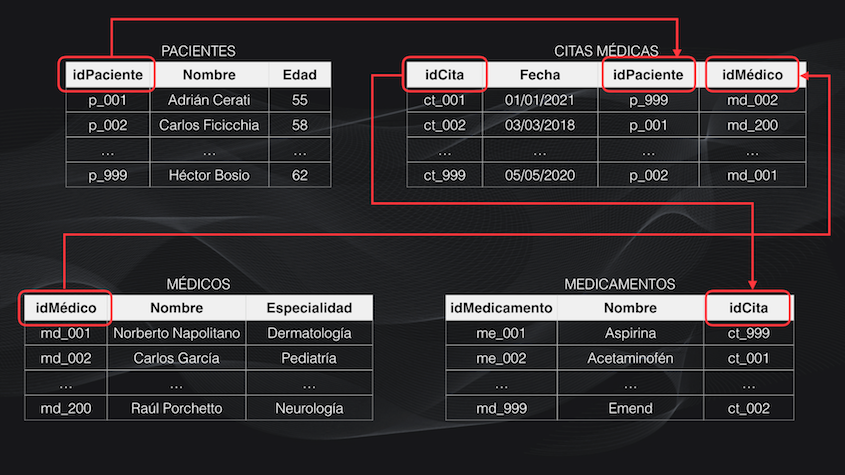
Y si queremos por ejemplo en un momento dado saber cuál médico trató a un paciente específico y qué medicamento le recetó, necesitamos relacionar la información entre estas cuatro tablas para poder extraer la información. ¡Y esto es precisamente una base de datos relacional!
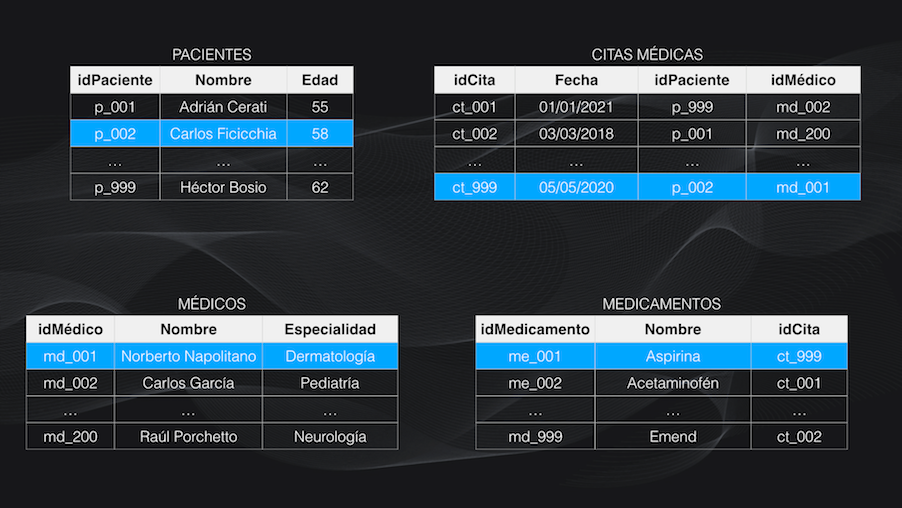
Entonces la información no está condensada en una única tabla y, dependiendo de la consulta que queramos realizar, necesitamos un método eficiente que nos permita relacionar la información entre unas tablas y otras para poder extraer los datos que necesitamos.
Y SQL fue creado precisamente para esto, para poder realizar este tipo de consultas fácilmente, incluso si la base de datos es inmensa, lo que lo hace tremendamente útil para el caso particular del Machine Learning, en donde precisamente desarrollamos modelos que muchas veces usan sets de datos con miles o millones de registros.
Veamos entonces una guía con lo que considero son las formas de uso esenciales de SQL para el caso del Machine Learning y la Ciencia de Datos.
SQL: una guía introductoria para Machine Learning y Ciencia de Datos
La consulta más sencilla en SQL selecciona una columna de una única tabla. Para ello escribimos inicialmente la palabra SELECT y luego el nombre de la columna, y en la segunda línea de la consulta escribimos la palabra FROM y luego especificamos el nombre de la tabla:

Las palabras SELECT y FROM se conocen como palabras clave, y pueden ser escritas en mayúscula o minúscula, aunque usualmente se dejan en mayúscula para hacer el código más entendible.
Usualmente trabajamos con sets de datos muy grandes, así que muchas veces sólo queremos extraer los registros que cumplan con ciertas condiciones. Para esto podemos usar WHERE.
Por ejemplo, si en el caso anterior no queremos extraer la columna completa sino únicamente los registros de pacientes con edades mayores de 60 años entonces escribimos la misma consulta anterior y agregamos una línea con la palabra WHERE seguida de la condición:

También podemos realizar agrupaciones y conteos. Si por ejemplo queremos saber cuántos médicos tiene el hospital en cada especialidad, primero usamos SELECT seguido de la columna de la tabla que nos interesa, y agregamos la palabra clave COUNT. Luego, con FROM especificamos en cuál tabla queremos realizar la consulta y finalmente usamos GROUP BY para especificar que queremos realizar agrupación por especialidad:

Si queremos por ejemplo saber únicamente las especialidades que tienen dos o más médicos, podemos agregar la palabra clave HAVING especificando esta condición:

También podemos organizar los registros de forma ascendente o descendente, usando como criterio columnas con datos numéricos o en formato de texto y las palabras clave ORDER BY y DESC:

Y como les contaba hace un momento, lo más útil de SQL es que nos permite establecer relaciones entre varias tablas. Por ejemplo, si queremos saber cuál es el médico tratante de cada paciente, podemos usar la palabra clave JOIN, para unir la información de dos o más tablas:

Y estos son sólo algunos ejemplos de uso que considero básicos, un nivel introductorio. Desde luego hay infinidad de combinaciones que se pueden realizar, y todo esto depende, como les comentaba hace un momento, del tipo de información que queramos extraer de la base de datos.
Más allá de eso lo que pudimos ver con este ejemplo es que realmente usar SQL es relativamente sencillo, porque es un lenguaje de programación bastante intuitivo. Y si revisan las consultas que acabamos de realizar realmente es fácil entender lo que se está haciendo.
6 razones para aprender SQL para Machine Learning y Ciencia de Datos
Bien, ya tenemos un panorama bastante detallado de qué es y cómo funciona SQL. Ahora sí veamos las 6 razones por las cuales considero que cualquiera que esté interesado en trabajar en las áreas del Machine Learning o la Ciencia de Datos, debería aprender a usar SQL.
La primera y la más importante es porque cuando se habla de datos estructurados usualmente SQL es el estándar utilizado en la mayoría de empresas. Así que si queremos un trabajo en Machine Learning o Data Science, debemos ser capaces de realizar consultas y extraer información de estas bases de datos.
La segunda es porque usualmente estas bases de datos son inmensas, con decenas o cientos de tablas, y cada una con miles o incluso millones de registros. Pensar en almacenar esta información en una tabla de excel para luego consultarla es simplemente una opción que no resulta viable.
La tercera razón está relacionada con la anterior: y es que si manejamos SQL podemos crear consultas muy específicas que nos pemitirán extraer únicamente los datos que queremos para nuestro proyecto de Machine Learning. Además que en este proceso vamos a tener un contacto directo con los datos, sabremos cómo fueron recolectados, podremos entender su estructura, y todo esto en últimas nos permitirá entender los datos, algo fundamental para las demás fases del proyecto, porque nos facilitará posteriormente su depuración, hacer un análisis exploratorio, una extracción de características, así como determinar el modelo de Machine Learning más adecuado para esos datos.
La cuarta razón es porque SQL se puede integrar fácilmente con Python o R. Así que fácilmente podemos usar SQL para extraer la información de la base de datos, y luego usar por ejemplo Python para realizar el procesamiento de estos datos e implementar el modelo.
La quinta razón es porque, a pesar de que SQL tiene más de 40 años, aún sigue siendo usado para implementar la siguiente generación de bases de datos en la nube, como las plataformas ofrecidas por Microsoft, Google o Amazon, por ejemplo.
Y la sexta razón es porque simplemente el mercado lo está pidiendo. Si hacemos una búsqueda de los perfiles requeridos para Ingeniería de Machine Learning o Ciencia de Datos veremos que en muchos de estos casos el manejo de SQL es un requisito fundamental.
Conclusión
Bien, con todo lo que te acabo de contar espero que puedas tener un panorama completo de la importancia que tiene saber usar SQL si quieres desempeñarte profesionalmente en las áreas del Machine Learning o la Ciencia de Datos.
A pesar de que en los últimos años han surgido otras alternativas, SQL sigue siendo el estándar de facto para interactuar con bases de datos, y en mi opinión personal lo seguirá siendo durante muchos años más.
Además, como lo vimos en los ejemplos , aprender SQL es relativamente sencillo, es un lenguaje de programación bastante simple y muy intuitivo. Así que definitivamente te recomiendo aprenderlo bien sea que ya estés trabajando o si te estás preparando para desempeñarte como futuro ingeniero o ingeniera de Machine Learning.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: