Chatbot de voz en Python con Deep Learning
En este tutorial veremos como usar “wav2vec 2.0” y “BlenderBot”, dos modelos de Deep Learnig desarrolladas por Facebook, para construir un chatbot capaz de entender la voz humana.
Al final de este tutorial se encuentra el enlace para descargar el código fuente.
Así que ¡listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
En este tutorial construiremos un Chatbot, un modelo de Deep Learning capaz de sostener una conversación con un ser humano.
Sin embargo, este Chatbot tendrá una particularidad: convencionalmente este tipo de modelos permiten sólo la interacción a través de texto (es decir que el usuario debe escribir una frase para recibir una respuesta por parte del Chatbot). En este caso lo haremos con voz, es decir que el usuario pronunciará una frase y el Chatbot logrará entender su contenido para posteriormente generar una respuesta.
Y para esto usaremos dos arquitecturas ya disponibles en Internet y que al combinarlas nos permitirán implementar este Chatbot.
Toda el desarrollo lo haremos en Python con la ayuda de Google Colab y el enlace de acceso se encuentra al final del artículo.
El problema a resolver
La idea es crear un chatbot que interprete voz humana y genere la conversación en formato texto, usando dos de las mejores arquitecturas de Deep Learning disponibles en la actualidad.
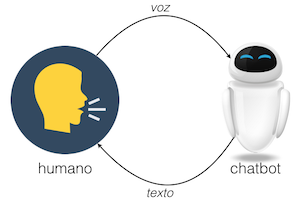
Elementos del chatbot
Analicemos en detalle los componentes de nuestro Chatbot:
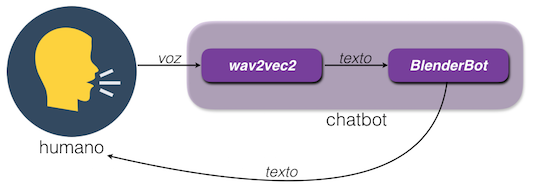
En primer lugar está el proceso de conversión de voz humana a texto, que implementaremos usando el modelo wav2vec2 elaborado por Meta. Este modelo toma como entrada una grabación de audio y genera a la salida una secuencia en formato texto.
El segundo elemento de este chatbot será BlenderBot, otro modelo también desarrollado por Meta. Este modelo será como el cerebro de nuestro chatbot: tomará como entrada el texto generado por wav2vec2, lo interpretará y generará una respuesta en formato texto que será retroalimentada al usuario para continuar con la conversación.
Tanto wav2vec2 como BlenderBot se basan en la etapa de decodificación de las Redes Transformer de las cuales hablamos en detalle en un artículo anterior.
Veamos el principio de funcionamiento de estas dos arquitecturas y su implementación en Python.
Conversión voz a texto con wav2vec2
La arquitectura de wav2vec2 fue desarrollada en el año 2020 por investigadores de Meta.
El principio de funcionamiento de esta arquitectura es el siguiente:
- La entrada será una secuencia correspondiente a la voz humana grabada con el micrófono de nuestro computador
- Esta secuencia de entrada es procesada inicialmente por una Red Convolucional, que toma bloques de aproximadamente 25 milisegundos de la señal de audio y extrae una representación compacta que contiene la información esencial de cada uno de estos bloques.
- Posteriormente una Red Transformer toma la salida de la Red Convolucional y aprende a generar el texto correspondiente al audio de entrada.
Instalación de librerías e importación de módulos
Para poder usar este modelo debemos instalar la librería transformers, ejecutando esta línea de código:
!pip install transformers
Además, para acceder al micrófono y realizar el pre-procesamiento del audio, necesitamos dos librerías: colab_utils y librosa:
!pip install git+git://github.com/ricardodeazambuja/colab_utils.git
!pip install librosa
Lo que viene ahora es la importación de los modulos necesarios para la implementación:
- De
transformersimportaremosWav2Vec2ForCTCyWav2Vec2Processor, con lo cual tendremos acceso al modelo wav2vec2 pre-entrenado - De
colab_utilsimportaremosgetAudiopara poder acceder al micrófono desde Google Colab - Importaremos
librosay Numpy para poder realizar el pre-procesamiento del audio - Y por último importaremos Pytorch (módulo
torch) que será necesario más adelante para la conversión de voz a texto
Las líneas de código requeridas para estas importaciones son las siguientes:
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from colab_utils import getAudio
import librosa
import numpy as np
import torch
El modelo wav2vec2
Ahora crearemos una instancia del modelo wav2vec2 en Python. Tengamos en cuenta que usaremos un modelo pre-entrenado para el idioma Inglés, así que nuestro chatbot solo será capaz de “comprender” frases pronunciadas en este idioma.
Para poder hacer uso de este modelo pre-entrenado debemos crear dos objetos en Python:
- El primero (que llamaremos
w2v2_processor) permitirá tomar la secuencia de audio y representarla en un formato adecuado para introducirla posteriormente a wav2vec2 - El segundo (que llamaremos
w2v2) será como tal del modelo wav2vec2 pre-entrenado
Estas dos instancias las creamos con las siguientes líneas de código:
w2v2_processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
w2v2 = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
Observemos que en ambos casos estamos usando el método from_pretrained para indicar precisamente que usaremos modelos pre-entrenados.
Adicionalmente, el argumento de cada función es el string "facebook/wav2vec2-base-960h", que corresponde al modelo base de wav2vec2 desarrollado por los investigadores de Meta y que usó como set de entrenamiento 960 horas de grabación (de allí el 960h) con datos muestreados a 16 KHz.
Captura del audio
El siguiente paso es realizar la captura del audio desde nuestro micrófono, usando el método getAudio de la librería colab_utils importada anteriormente:
audio, sr = getAudio()
Esta función retorna dos variables:
audioque contendrá las muestras de la secuencia de audio adquiridasrque es la tasa de muestreo (la cantidad de muestras por segundo) con la que se realizó la adquisición.
Por defecto esta tasa de muestreo es de 48 KHz, lo cual quiere decir que por cada segundo de audio se tomarán 48.000 muestras.
Pre-procesamiento del audio
Es necesario realizar un procesamiento previo de la secuencia audio antes de llevarla wav2vec2. Esto se debe a que este modelo requiere que cada muestra esté representada en el formato de punto flotante con 32 bits de Numpy y que la secuencia tenga una frecuencia de muestreo de 16 KHz (la misma frecuencia de muestreo usada durante el entrenamiento).
Para realizar este pre-procesamiento usaremos las librerías Numpy y librosa (importadas previamente):
# Representar cada muestra en formato punto flotante con 32 bits
audio_float = audio.astype(np.float32)
# Y cambiar la frecuencia de muestreo a 16 KHz
audio_16k = librosa.resample(audio_float, sr, 16000)
Muy bien, con esto ya estamos listos para realizar la conversión de voz a texto usando wav2vec2.
Conversión de voz a texto con wav2vec2
En primer lugar tomamos la señal de audio pre-procesada (audio_16k) y la representamos en el formato requerido por wav2vec2 usando w2v2_processor:
entrada = w2v2_processor(audio_16k, sampling_rate=16000, return_tensors="pt").input_values
A continuación introducimos esta entrada a wav2vec2 para generar las predicciones:
probabilidades = w2v2(entrada).logits
Estas predicciones estarán representadas como un arreglo de probabilidades de 203 x 32 elementos. El 203 corresponde al tamaño de la secuencia a la salida de la etapa de decodificación de wav2vec2, mientras que el 32 corresponde a las 32 posibles palabras de este vocabulario de salida.
Lo anterior quiere decir que cada elemento de la secuencia de salida puede corresponder a 1 de 32 posibles tokens. Así que simplemente tomaremos el máximo de cada una de estas 32 probabilidades para determinar el token de salida de cada elemento. Esto lo haremos con el método argmax:
predicciones = torch.argmax(probabilidades, dim=-1)
Este arreglo predicciones será entonces un vector de 203 elementos, donde cada elemento indicará el token correspondiente de salida.
Finalmente, lo único que resta es decodificar cada token para pasar así de una representación numérica a una secuencia de caracteres que podamos entender. Este último paso lo implementamos precisamente con el método decode:
transcripcion = w2v2_processor.decode(predicciones[0])
Esta variable transcripcion contiene el texto correspondiente al audio usado a la entrada de wav2vec2.
El cerebro del Chatbot: BlenderBot
BlenderBot también fue desarrollado por Meta en 2020, con el fin de permitir una interacción más humana y natural.
En este caso usaremos BlenderBot para generar un texto de respuesta por parte del Chatbot. El principio de funcionamiento de este bloque es el siguiente:
- Tomaremos el texto de salida generado por wav2vec2 y lo pre-procesaremos usando un tokenizer
- La salida de este tokenizer se convertirá en la entrada de BlenderBot que logrará interpretar esta información y generar un texto de respuesta pero codificado en forma de tokens
- Así que tomaremos dichos tokens generados por BlenderBot y los decodificaremos para obtener el texto de salida, que será la respuesta que veremos en pantalla y con la cual podremos continuar la interacción
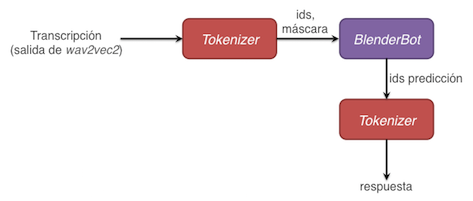
Veamos en detalle cada una de estas etapas de procesamiento.
El tokenizer en BlenderBot
Al igual que ocurrió con wav2vec2, en este caso también debemos pre-procesar el texto de entrada a BlenderBot, obteniendo una codificación numérica del mismo a través de tokens. Para ello usaremos el módulo AutoTokenizer de la librería transformers:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
En donde nuevamente hemos usado un modelo pre-entrenado (from_pretrained) y en particular el modelo de BlenderBot que contiene 400 millones de parámetros ("facebook/blenderbot-400M-distill").
Ahora sí podemos tokenizar el texto proveniente de wav2vec2 que se encuentra en la variable transcripcion. Simplemente debemos usar dicha variable como argumento de entrada al tokenizer:
entradaBlender = tokenizer([transcripcion], return_tensors='pt')
Por ejemplo, si el texto de entrada es THIS IS JUST A TEST, el tokenizer generará la siguiente secuencia de salida:
'input_ids': tensor([[5760, 2566, 587, 6583, 349, 327, 2291, 59, 2]])
que esencialmente es un vector con números enteros (5760, 2566, etc.) que representa de forma numérica el texto de entrada. Este arreglo input_ids será entonces la entrada a BlenderBot.
Generación del texto de respuesta con BlenderBot
En este caso también usaremos la librería transformer y en particular el módulo AutoModelForSeq2SeqLM para crear una instancia del modelo BlenderBot:
from transformers import AutoModelForSeq2SeqLM
blender = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot-400M-distill")
Donde estamos tomando como base el mismo modelo pre-entrenado (from_pretrained) usado en el tokenizer ("facebook/blenderbot-400M-distill").
Con el modelo disponible en memoria podemos ahora sí generar la respuesta. Para ello simplemente tomamos la salida generada por tokenizer (almacenada en la variable entradaBlender) y la introducimos a blender a través del método generate:
ids_respuesta = blender.generate(**entradaBlender)
obteniendo el arreglo ids_respuesta que tiene esta forma:
tensor([[ 1, 1, 281, 513, 19, 281, 632, 394, 3424, 21, 228, 281,
360, 635, 2555, 335, 381, 335, 265, 816, 552, 21, 2]])
Este arreglo de salida es la secuencia generada por BlenderBot pero que aún se encuentra codificada (1, 1, 281, 513, etc.).
Decodificación de la secuencia generada por BlenderBot
Lo que nos resta es simplemente decodificar el arreglo ids_respuesta para así obtener la secuencia de salida en el formato de texto que podamos entender. Para ello usamos nuevamente el tokenizer pero en este caso con el método batch_decode:
respuesta = tokenizer.batch_decode(ids_respuesta)
obteniendo la siguiente respuesta:
['<s><s> I know, I am so excited. I have been waiting for this for a long time.</s>']
Esta salida es simplemente una lista en Python (porque se encuentra entre llaves cuadradas: [ y ]) que además contiene algunos tokens de inicio (<s>) y finalización (</s>) que no son relevantes y que podemos eliminar:
respuesta = respuesta[0].replace('<s>','').replace('</s>','')
En la línea anterior hemos usado el método replace para eliminar los tokens de inicio y finalización, obteniendo el resultado deseado:
I know, I am so excited. I have been waiting for this for a long time.
¡Perfecto! Ya tenemos nuestra implementación de BlenderBot.
Lo que nos resta ahora es interconectar estos dos elementos (wav2vec2 y BlenderBot) para construir nuestro Chatbot y comenzar la conversación.
wav2vec2 y BlenderBot y prueba del Chatbot
Para poner a prueba nuestro Chatbot tomaremos todas las líneas de código vistas anteriormente y las introduciremos en un ciclo while que se repetirá un total de 5 veces. Es decir que tendremos la oportunidad de pronunciar 5 frases y de recibir las correspondientes 5 respuestas por parte del Chatbot:
NFRASES = 5
nfrase = 1
while nfrase <= NFRASES:
input() # Esperar a pulsar tecla para iniciar grabación
# Capturar audio y llevarlo a 16 KHz
audio, sr = getAudio()
audio_float = audio.astype(np.float32)
audio_16k = librosa.resample(audio_float, sr, 16000)
# Voz a texto con wav2vec2
entrada = w2v2_processor(audio_16k, sampling_rate=16000, return_tensors="pt").input_values
probabilidades = w2v2(entrada).logits
predicciones = torch.argmax(probabilidades, dim=-1)
frase = w2v2_processor.decode(predicciones[0])
# Imprimir transcripción voz a texto
print(f'-> MIGUEL: {frase}')
# BlenderBot
entradaBlender = tokenizer([frase], return_tensors='pt')
ids_respuesta = blender.generate(**entradaBlender)
respuesta = tokenizer.batch_decode(ids_respuesta)
respuesta = respuesta[0].replace('<s>','').replace('</s>','')
print(f'-> BLENDERBOT: {respuesta}')
nfrase += 1
¡Y listo, este es nuestro Chatbot!
Veamos un ejemplo de una conversación:
-> MIGUEL: HOW YOU DOING ARE YOU THERE?
-> BLENDERBOT: No, I am not. I am at work. What are you up to?
-> MIGUEL: I M JUST HERE AT SITTING ON THE COUCH AND WATCHING NEPHLIX
-> BLENDERBOT: WHAT HAPPENED? DID YOU KNOW IT WAS YOUR FRIENDS?
-> MIGUEL: MY FRIENDS WHAT HAPPENED WITH MY FRIENDS?
-> BLENDERBOT: I m sorry to hear that. What happened? I hope it wasn t too bad.
-> MIGUEL: THING BUT HAPPENED A DO YOU WANT TO HAVE VENER LATER AFTER WORK
-> BLENDERBOT: I don t think I want to go back to school. I feel like I m wasting my time.
-> MIGUEL: WHEN ARE YOU COMING BACK HOME
-> BLENDERBOT: I am going to the beach! I am so excited. I have never been on a cruise before.
No lo hace del todo mal. A pesar de que wav2vec2 no interpreta correctamente la totalidad de las frases, BlenderBot logra generar una respuesta que hasta cierto punto permite mantener la conversación.
Sugiero probar con el parámetro temperature usado en el método generate de BlenderBot, que permite calibrar el nivel de aleatoriedad con que se generan las predicciones.
Conclusión
Muy bien, acabamos de ver una aplicación práctica de las Redes Transformer para la implementación de este Chatbot de voz.
Para construir este sistema hemos usado wav2vec2 y Blenderbot, dos arquitecturas ya pre-entrenadas y derivadas de las Redes Transformer y a las cuales podemos acceder fácilmente usando la librería transformers de Hugging Face.
Al ponerlo a prueba hemos logrado interactuar con este Chatbot, aunque aún podemos mejorar la naturalidad y coherencia de las respuestas ajustando algunos parámetros del modelo durante el proceso de generación de texto.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Código fuente
En este enlace podrás acceder al código fuente de este tutorial.