Tutorial: generación de texto con Redes Recurrentes en Python
En este tercer post de la serie “Redes Neuronales Recurrentes” veremos cómo entrenar una Red Recurrente en Python y Keras capaz de generar texto.
En particular veremos cómo implementar una Red Neuronal Recurrente capaz de generar nombres de dinosaurios. Para ello usaremos Python y la librería Keras, e implementaremos el código para la lectura de los datos, para implementar y entrenar la red recurrente y para generar nombres una vez realizado el entrenamiento.
Al final del artículo se encuentra el enlace para descargar el set de datos y el código fuente.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
Recordemos que una Red Neuronal Recurrente es una arquitectura que permite analizar secuencias (como texto, conversaciones o videos).
Para ello usa el concepto de recurrencia: además de generar un dato de salida, genera algo conocido como el “estado oculto” (o hidden state), encargado de almacenar la información presente en instantes previos de la secuencia.
En los dos primeros posts de esta serie vimos una introducción a las Redes Neuronales Recurrentes y una explicación detallada de las Redes Recurrentes. Te invito a revisar estos post si quieres conocer los detalles de funcionamiento de esta arquitectura del Deep Learning.
Descripción de la Red Recurrente a entrenar
Para entrenar la red recurrente de este tutorial usaremos un set de datos que contiene nombres de dinosaurios.
El objetivo es que la red tome un caracter de entrada y aprenda a predecir el siguiente caracter en la secuencia, generando así nuevos nombres de dinosaurios:

El código que implementaremos está dividido en cinco partes: importación de librerías, lectura de los datos, implementación del modelo en Keras, entrenamiento y generación de nombres con el modelo ya entrenado.
Veamos entonces paso a paso cómo realizar esta implementación.
Importación de librerías
Las librerías que necesitamos en este caso son similares a las usadas en tutoriales anteriores.
Usaremos Numpy y ajustaremos la semilla del generador aleatorio para garantizar la reproducibilidad del entrenamiento:
import numpy as np
np.random.seed(5)
Después importaremos de Keras las funciones Input y Dense, y especialmente prestaremos atención a SimpleRNN, que nos permite precisamente crear una celda recurrente:
from keras.layers import Input, Dense, SimpleRNN
Después importaremos Model y el optimizador del Gradiente Descendente (SGD) que nos permitirán crear y entrenar el modelo:
from keras.models import Model
from keras.optimizers import SGD
Finalmente importaremos “to_categorical” y el backend para poder representar la entrada y salida al modelo en el formato adecuado durante el entrenamiento y la durante la predicción:
from keras.utils import to_categorical
from keras import backend as K
Lectura y pre-procesamiento del set de datos
El set de entrenamiento está almacenado en un archivo de texto (al final del artículo encontrarás el enlace de descarga), y contiene un total de 1536 nombres de dinosaurios.
La lectura es sencilla: usamos la función open de Python, y posteriormente representamos todos los caracteres en minúscula usando el método lower:
nombres = open('nombres_dinosaurios.txt','r').read()
nombres = nombres.lower()
Como la Red Recurrente no acepta caracteres a la entrada, debemos convertir cada uno de estos a una representación numérica.
Para ello definiremos un alfabeto, que corresponde a los diferentes caracteres que conforman el set de datos.
Esto lo logramos de forma sencilla usando la función set de Python. Simplemente introducimos el contenido del archivo de texto y la función set encuentra el listado de caracteres únicos:
alfabeto = list(set(nombres))
tam_datos, tam_alfabeto = len(nombres), len(alfabeto)
Aunque el set de datos contiene 19909 caracteres, el alfabeto consta de tan solo 27 caracteres, dentro de los cuales se incluye el carácter de cambio de línea que indica el final de cada nombre:
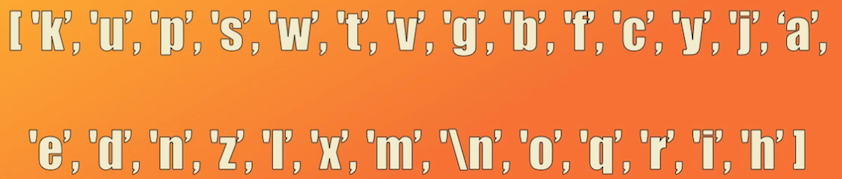
La idea es que durante el entrenamiento cada carácter será representado en el formato one-hot, es decir con un vector de 27 elementos (el tamaño del alfabeto) donde sólo uno de estos elementos será diferente de cero:

Para realizar esta conversión necesitamos entonces un diccionario, que nos permita definir la equivalencia correspondiente entre el carácter y el índice correspondiente dentro del vector one-hot.
Para hacer esto simplemente creamos un diccionario en Python, definiendo para cada carácter del alfabeto un índice (o numero entero):
car_a_ind = { car:ind for ind,car in enumerate(sorted(alfabeto))}
Así por ejemplo, el cambio de línea será representado con el índice 0, la “a” con el 1, la “b” con el 2 y así sucesivamente:

De igual forma, una vez entrenada la Red Recurrente, seremos capaces de generar números (no caracteres) a la salida de la misma. Por tanto, para obtener el nombre generado, debemos realizar el proceso inverso: convertir vectores one-hot a su carácter correspondiente, para lo cual crearemos un segundo diccionario que permite mapear índices a caracteres:
ind_a_car = { ind:car for ind,car in enumerate(sorted(alfabeto))}

Creación de la Red Recurrente en Keras
Veamos ahora las características del modelo a implementar:
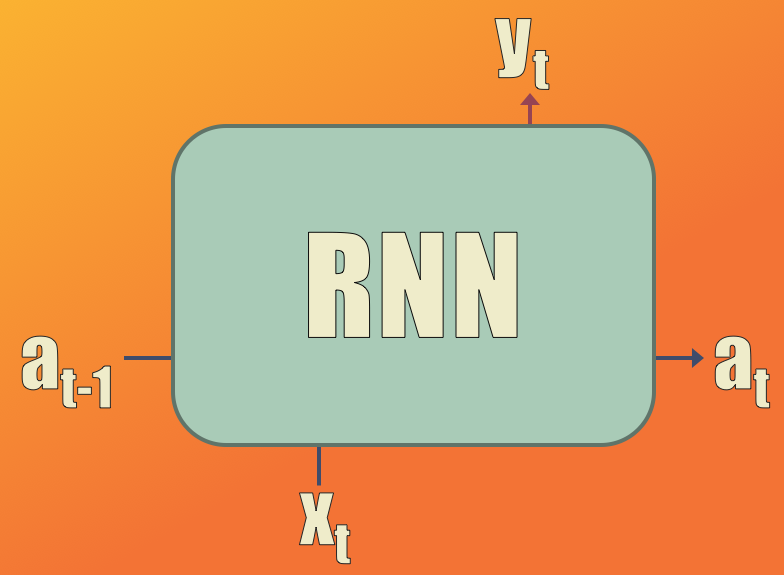
Tendrá dos entradas:
- $x$ (un carácter del set de entrenamiento) que se representará en el formato one-hot como un vector con 27 elementos (que es el tamaño del alfabeto)
- $a_{t-1}$ (el estado oculto en el instante de tiempo anterior) que se representará con un vector de 25 elementos (que será el mismo tamaño de la capa oculta)
Además, el modelo generará dos salidas:
- $y$ (la predicción, o el carácter generado por el modelo) que, al igual que la entrada, se representará como un vector con 27 elementos en formato one-hot
- $a_t$ (el estado oculto en el instante de tiempo actual), un vector también de 25 elementos.
Para implementar este modelo usaremos dos elementos:
- Una celda recurrente, que tomará la entrada $x$ y el estado oculto anterior, y generará el nuevo estado oculto usando la función de activación tangente hiperbólica
- Una capa de salida con función de activación softmax, que tomará la activación generada por la celda recurrente y generará la salida $y$ o predicción
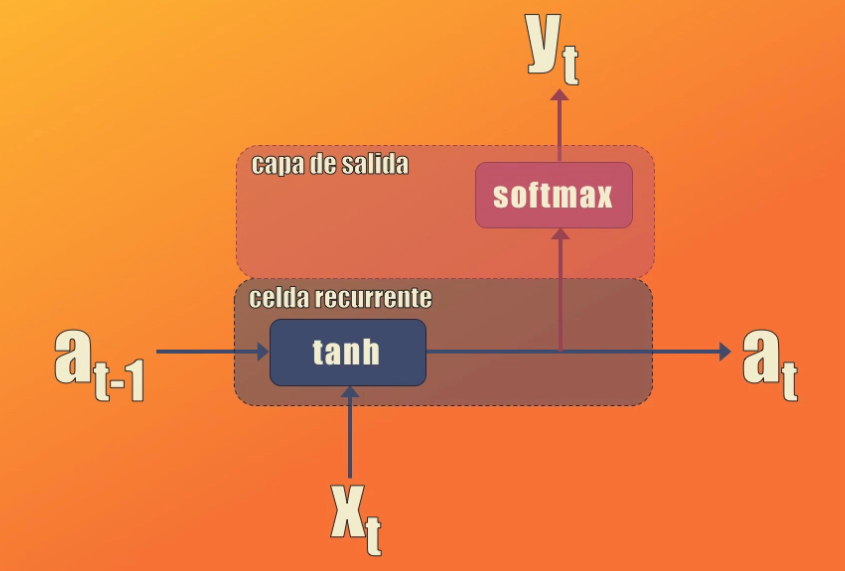
Estos dos elementos (la celda recurrente y la capa softmax) los usaremos más adelante para la generación de nombres, una vez hayamos entrenado el modelo.
La implementación de este modelo es sencilla en Keras. En primer lugar definimos el número de neuronas de la capa oculta (es decir 25), y creamos dos contenedores:
- Uno para la entrada ($x_t$ en el diagrama anterior), en donde hemos usado la palabra clave
None, lo cual nos permite tener entradas (es decir nombres de dinosaurio) con tamaños variables. - Uno para el estado oculto ($a_{t-1}$ en el diagrama anterior), que será precisamente un vector con 25 elementos
n_a = 25 # Número de unidades en la capa oculta
entrada = Input(shape=(None,tam_alfabeto))
a0 = Input(shape=(n_a,))
Ahora creamos la celda recurrente. Para ello usamos la función SimpleRNN importada anteriormente.
Esta celda tendrá 25 neuronas, función de activación tangente hiperbólica y usaremos la palabra clave return_state para que a la salida nos entregue el nuevo estado oculto actualizado:
celda_recurrente = SimpleRNN(n_a, activation='tanh', return_state = True)
Ahora creamos la capa softmax. Para ello usamos la función Dense. Esta capa tendrá 27 neuronas de salida (el tamaño del alfabeto) y usará precisamente la función de activación “softmax”:
capa_salida = Dense(tam_alfabeto, activation='softmax')
Finalmente creamos un modelo en Keras, usando la función Model importada anteriormente.
Para ello instanciamos la celda recurrente, agregando las dos entradas definidas anteriormente. Posteriormente creamos la variable “salida” y en ella almacenamos la activación entregada por la celda recurrente.
hs, _ = celda_recurrente(entrada, initial_state=a0)
salida = []
salida.append(capa_salida(hs))
Ahora creamos el modelo, dejando explícito que tendremos dos entradas (el caracter actual y el estado oculto anterior) y la salida correspondiente a la predicción:
modelo = Model([entrada,a0],salida)
Por último (al igual que lo hacíamos en el caso de las Redes Neuronales o Convolucionales, creamos el optimizador (Gradiente Descendente) y lo añadimos al modelo:
opt = SGD(lr=0.0005)
modelo.compile(optimizer=opt, loss='categorical_crossentropy')
Entrenamiento de la Red Recurrente
Para el entrenamiento generamos inicialmente una lista con los nombres de cada dinosaurio y los mezclamos aleatoriamente, usando np.random.shuffle como lo vemos en las siguientes líneas de código:
with open("nombres_dinosaurios.txt") as f:
ejemplos = f.readlines()
ejemplos = [x.lower().strip() for x in ejemplos]
np.random.shuffle(ejemplos)
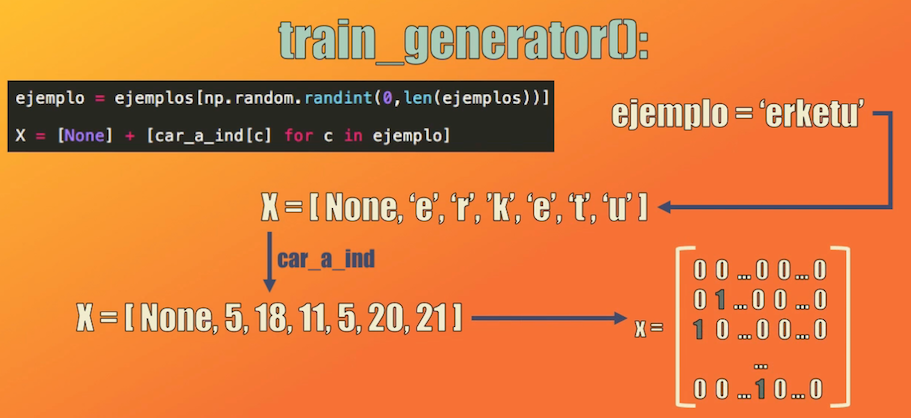
Después definimos una función que tome uno a uno cada ejemplo de entrenamiento y que genere tres vectores, que serán las entradas al modelo:
def train_generator():
while True:
# Tomar un ejemplo aleatorio
ejemplo = ejemplos[np.random.randint(0,len(ejemplos))]
# Convertir el ejemplo a representación numérica
X = [None] + [car_a_ind[c] for c in ejemplo]
# Crear "Y", resultado de desplazar "X" un caracter a la derecha
Y = X[1:] + [car_a_ind['\n']]
# Representar "X" y "Y" en formato one-hot
x = np.zeros((len(X),1,tam_alfabeto))
onehot = to_categorical(X[1:],tam_alfabeto).reshape(len(X)-1,1,tam_alfabeto)
x[1:,:,:] = onehot
y = to_categorical(Y,tam_alfabeto).reshape(len(X),tam_alfabeto)
# Activación inicial (matriz de ceros)
a = np.zeros((len(X), n_a))
yield [x, a], y
Veamos paso a paso los vectores generados por esta función:
- La entrada $X$, correspondiente a un nombre de dinosaurio tomado aleatoriamente del set de entrenamiento. Cada carácter será representado primero como un número entero (usando el diccionario creado al inicio del código) y luego representado en formato one-hot. Entrenaremos el modelo para que el primer carácter presentado sea siempre un vector de ceros:
- La salida $Y$, que será simplemente el resultado de tomar la entrada y desplazarla un carácter a la derecha. De nuevo, cada carácter es representado con un índice correspondiente y luego convertido al formato one-hot:

- Finalmente definimos la activación inicial que será simplemente una matriz de ceros, y que se irá actualizando a medida que se presentan uno a uno los caracteres al modelo durante el entrenamiento:
a = np.zeros((len(X)), n_a)
Para entrenar esta Red Recurrente definimos un total de 10000 iteraciones, en cada una de las cuales presentaremos 80 ejemplos de entrenamiento.
El entrenamiento lo haremos con el método fit_generator, y como parámetros de entrada tendremos la función creada anteriormente (train_generator) que permite crear un ejemplo de entrenamiento, así como el número de ejemplos a usar durante cada iteración (es decir 80):
BATCH_SIZE = 80 # Número de ejemplos de entrenamiento a usar en cada iteración
NITS = 10000 # Número de iteraciones
for j in range(NITS):
historia = modelo.fit_generator(train_generator(), steps_per_epoch=BATCH_SIZE, epochs=1, verbose=0)
# Imprimir evolución del entrenamiento cada 1000 iteraciones
if j%1000 == 0:
print('\nIteración: %d, Error: %f' % (j, historia.history['loss'][0]) + '\n')
Predicción con la Red Recurrente: generación de nombres de dinosaurios
Para generar los nombres con el modelo entrenado usaremos la celda recurrente y la capa de salida softmax creadas anteriormente y ya entrenadas en el paso anterior. Para esto crearemos la función generar_nombre:
def generar_nombre(modelo,car_a_num,tam_alfabeto,n_a):
# Inicializar x y a con ceros
x = np.zeros((1,1,tam_alfabeto,))
a = np.zeros((1, n_a))
# Nombre generado y caracter de fin de linea
nombre_generado = ''
fin_linea = '\n'
car = -1
# Iterar sobre el modelo y generar predicción hasta tanto no se alcance
# "fin_linea" o el nombre generado llegue a los 50 caracteres
contador = 0
while (car != fin_linea and contador != 50):
# Generar predicción usando la celda RNN
a, _ = celda_recurrente(K.constant(x), initial_state=K.constant(a))
y = capa_salida(a)
prediccion = K.eval(y)
# Escoger aleatoriamente un elemento de la predicción (el elemento con
# con probabilidad más alta tendrá más opciones de ser seleccionado)
ix = np.random.choice(list(range(tam_alfabeto)),p=prediccion.ravel())
# Convertir el elemento seleccionado a caracter y añadirlo al nombre generado
car = ind_a_car[ix]
nombre_generado += car
# Crear x_(t+1) = y_t, y a_t = a_(t-1)
x = to_categorical(ix,tam_alfabeto).reshape(1,1,tam_alfabeto)
a = K.eval(a)
# Actualizar contador y continuar
contador += 1
# Agregar fin de línea al nombre generado en caso de tener más de 50 caracteres
if (contador == 50):
nombre_generado += '\n'
print(nombre_generado)
Esta función es bastante extensa, así que la desglosaremos a continuación:
Al iniciar la predicción introduciremos a la celda inicialmente vectores de ceros tanto para la entrada “x” como para el estado oculto anterior:
x = np.zeros((1,1,tam_alfabeto,))
a = np.zeros((1, n_a))
Luego llevaremos la activación resultante a la capa softmax para generar así la predicción:
while (car != fin_linea and contador != 50):
# Generar predicción usando la celda RNN
a, _ = celda_recurrente(K.constant(x), initial_state=K.constant(a))
y = capa_salida(a)
prediccion = K.eval(y)
Esta predicción será un vector con 27 elementos, que representa una distribución de probabilidad. La idea es escoger aleatoriamente una de estas 27 posiciones, para lo cual usamos la función “choice” de numpy. Desde luego, la posición del elemento con la probabilidad más alta tendrá más opciones de ser seleccionada:
ix = np.random.choice(list(range(tam_alfabeto)),p=prediccion.ravel())
Una vez definida la posición buscamos el carácter correspondiente según el diccionario definido anteriormente y lo añadimos al nombre generado:
car = ind_a_car[ix]
nombre_generado += car
Por último actualizamos las entradas: ni x ni el estado oculto serán ahora vectores de ceros. La predicción que acabamos de generar se convertirá en la entrada a la celda para el siguiente instante de tiempo, mientras que la activación generada en esta iteración se convertirá en el nuevo estado oculto a usar en la siguiente iteración:
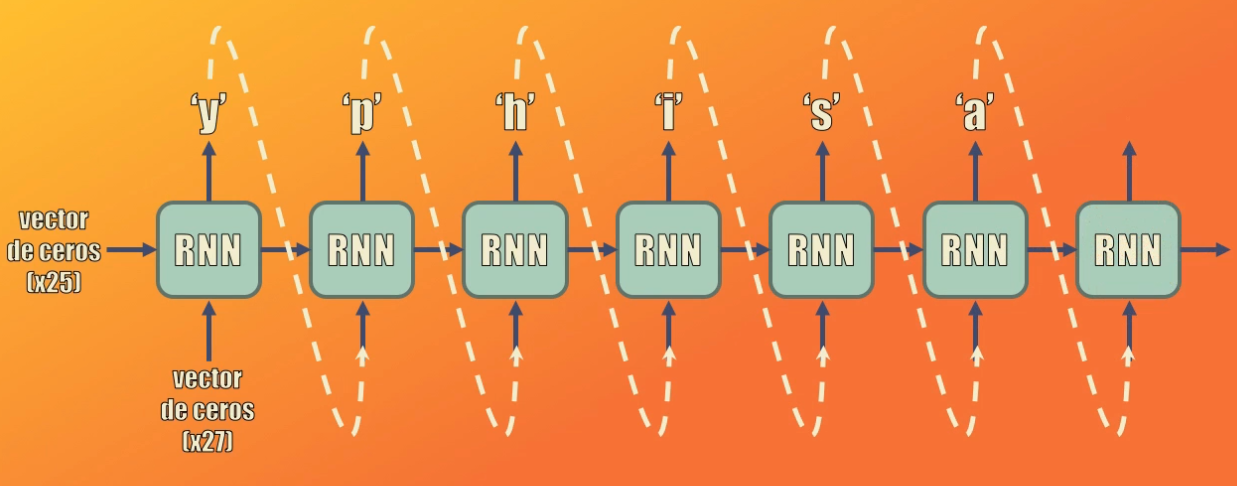
El proceso se repite de forma iterativa, generando uno a uno los caracteres de la predicción, hasta que se cumpla una de estas dos condiciones: que el número de caracteres generados sea 50 (es decir que el nombre generado contendrá máximo 50 caracteres) o que el último carácter generado corresponda al cambio de línea (lo cual indica el fin del nombre):
# Crear x_(t+1) = y_t, y a_t = a_(t-1)
x = to_categorical(ix,tam_alfabeto).reshape(1,1,tam_alfabeto)
a = K.eval(a)
# Actualizar contador y continuar
contador += 1
# Agregar fin de línea al nombre generado en caso de tener más de 50 caracteres
if (contador == 50):
nombre_generado += '\n'
print(nombre_generado)
Finalmente, usando esta función podemos generar 100 diferentes nombres:
for i in range(100):
generar_nombre(modelo,car_a_ind,tam_alfabeto,n_a)
Algunos ejemplos de nombres generados
Para finalizar, veamos algunos ejemplos de nombres generados por el modelo:

A la izquierda vemos algunos nombres generados antes del entrenamiento. Podemos ver que son nombres totalmente aleatorios, y es obvio, pues aún no hemos iniciado el entrenamiento.
A la derecha vemos algunos nombres generados por el modelo después de 10000 iteraciones de entrenamiento. Acá es evidente que la generación de nombres deja de ser aleatoria, y que las secuencias generadas se asemejan más a nombres reales de dinosaurios.
En particular podemos ver que los primeros nombres, los de extension más corta, parecen realmente nombres de dinosaurios.
Sin embargo observamos un comportamiento particular: a medida que la extensión de la secuencia generada es más grande (como en los cuatro últimos nombres generados) el nombre parece más aleatorio y no se asemeja al nombre de un dinosaurio.
Conclusión
Bien. En este episodio vimos paso a paso cómo implementar una Red Neuronal recurrente en Keras, capaz de generar nombres de dinosaurios.
Una vez entrenado el modelo vimos que los nombres generados se asemejan bastante a los nombres reales de dinosaurios, pero que esta semejanza desaparece cuando la secuencia generada es cada vez más extensa.
Esta es una limitación importante de este tipo de Redes Recurrentes: su memoria es de corto plazo y funcionan bastante bien cuando las secuencias (tanto de entrada como de salida) tienen una extensión relativamente corta.
En el siguiente post de esta serie veremos una variante de estas Redes Recurrentes, las Redes LSTM que resuelven este inconveniente y permiten así tener Redes Recurrentes más robustas capaces de procesar secuencias con mayor extensión.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Set de datos y código fuente
En este enlace de Github podrás descargar el set de datos y el código fuente de este tutorial.