Tutorial: Google Colab y el Machine Learning
En este tercer post de la serie “Tensorflow 2.0” veremos un tutorial con todos los detalles de Google Colab, una plataforma web de Google que nos permite entrenar modelos de Machine Learning usando máquinas virtuales de alto rendimiento, todo en la nube y usando precisamente TensorFlow 2.0.
Al final del artículo se encuentra el enlace para descargar el set de datos y el código fuente.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción: ¿qué son las CPUs, GPUs y TPUs?
Google Colab es una plataforma que nos permite, desde el mismo navegador de Internet, implementar y ejecutar código Python en la nube usando CPUs, GPUs o TPUs.
Pero antes de entender cómo usar Google Colab para implementar nuestros proyectos de Machine Learning resulta esencial que entendamos ¿qué eso de CPUs, GPUs y TPUs? y ¿por qué resultan importantes para el Machine Learning?
La CPU
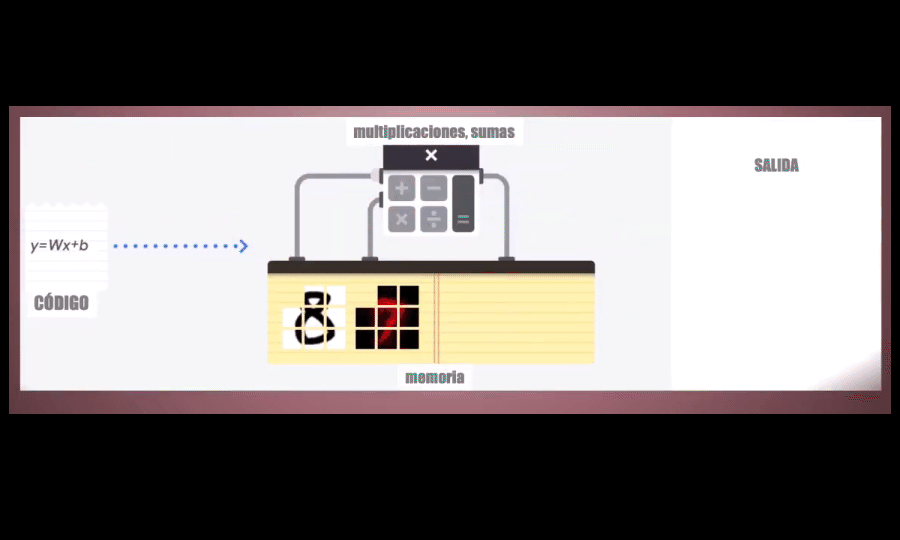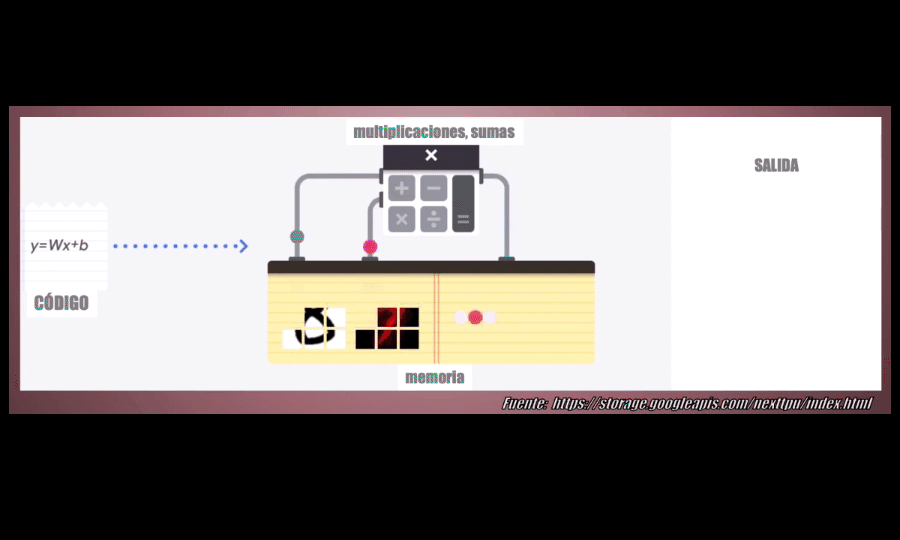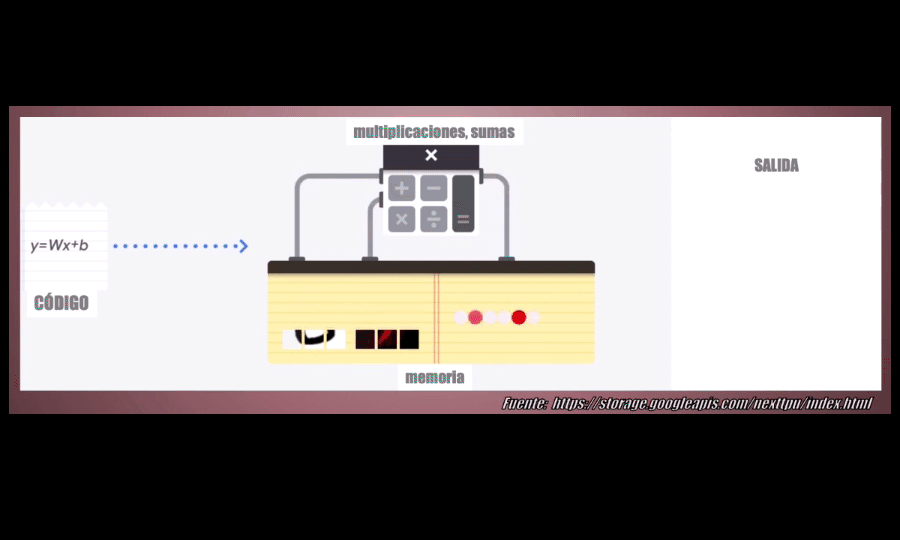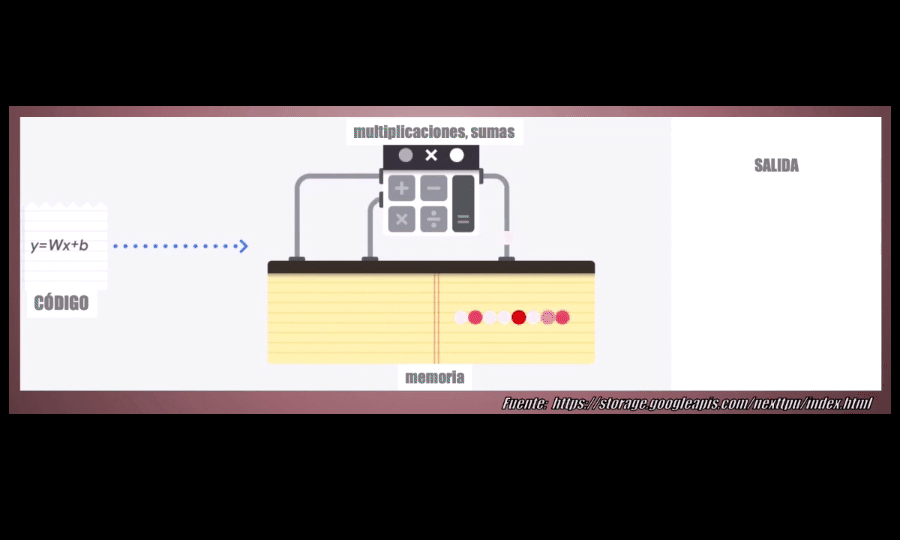
Una CPU, o Unidad Central de Procesamiento, es un procesador de propósito general. Esto quiere decir que está diseñado para funcionar para diferentes tipos de aplicaciones: en una CPU se puede ejecutar un programa de computador, o jugar un videojuego, reproducir música, navegar por Internet o realizar operaciones matemáticas . La desventaja es que puede realizar todas estas tareas pero no está optimizado para ninguna de ellas y por tanto, cuando pensamos en el Machine y el Deep Learning, los tiempos requeridos para entrenar un modelo y para posteriormente realizar predicciones son muuuy prolongados:

La unidad encargada de realizar estas operaciones es la A-L-U (unidad lógica aritmética) que permite realizar sumas y multiplicaciones. En particular, cuando se entrena un modelo de Machine o Deep Learning se deben realizar muchas (miles, millones) de estas operaciones pero el problema es que la ALU sólo es capaz de ejecutarlas UNA a UNA, lo que hace extremadamente lento el proceso. Es por eso que una CPU no es la más adecuada para desarrollar modelos de Machine Learning:
La GPU
Una GPU es una Unidad de Procesamiento Gráfico, que es principalmente usada por los “gamers” o los desarrolladores de videojuegos, o por personas que realizan animación por computador. Una GPU es más poderosa que una CPU, pues su arquitectura está pensada para procesar de manera eficiente datos más complejos, como gráficos 2D y 3D y secuencias de video:

La estrategia que usa la GPU, comparada con una CPU convencional, es simple: ¿por qué no usar miles de ALUs en lugar de una sola? Con esto se logran llevar a cabo miles de sumas y multiplicaciones simultáneamente (o en paralelo). A manera de ejemplo: actualmente una GPU aloja entre 2500 y 5000 ALUs, y esto permite que una GPU sea decenas, cientos o incluso algunos miles de veces más rápida que una CPU. Es por esto que hasta el momento las GPUs son una de las arquitecturas más usadas para desarrollar modelos Deep Learning en la actualidad:
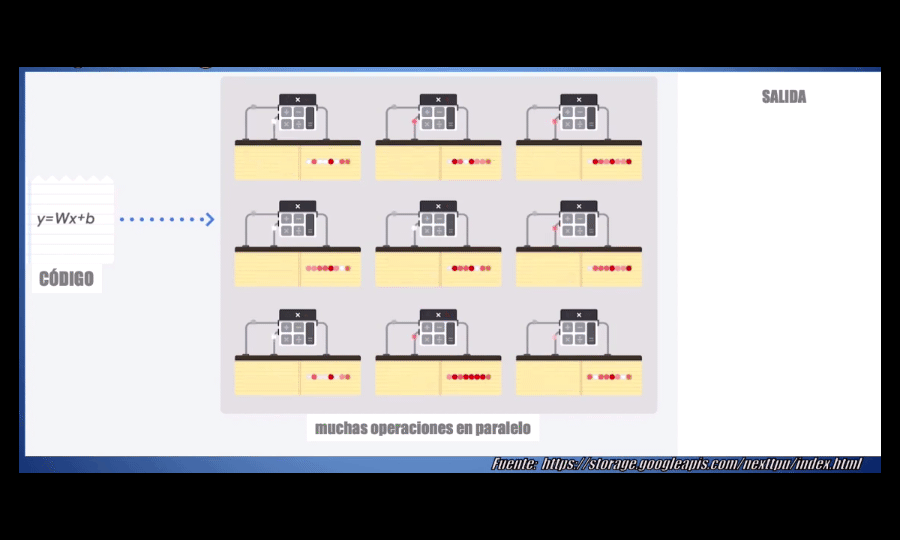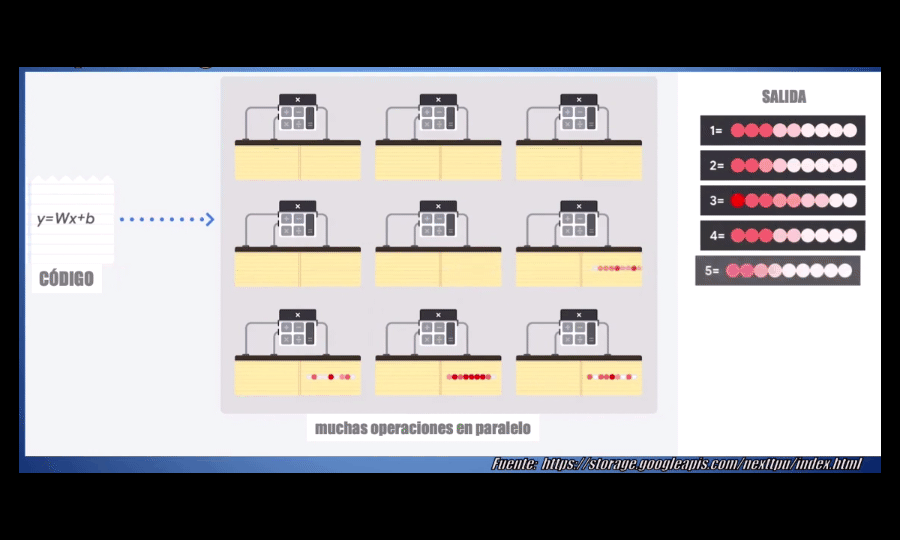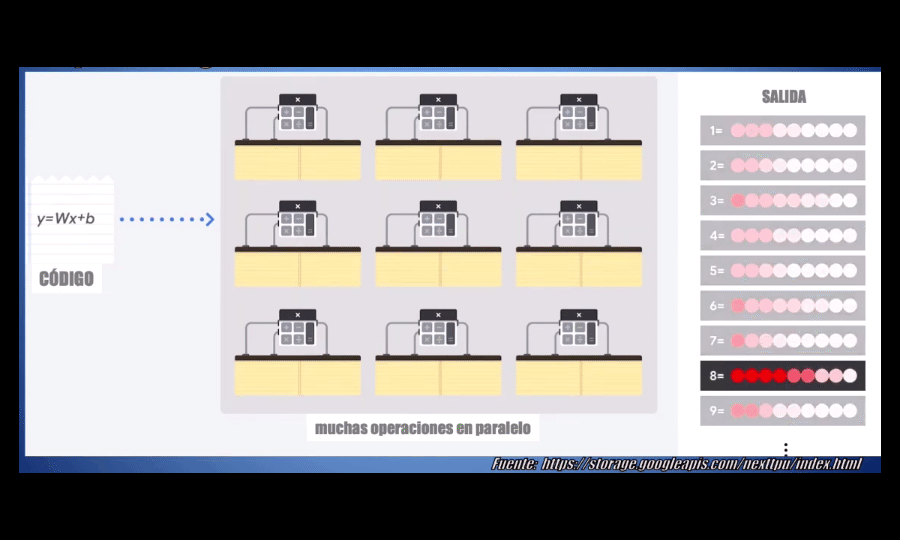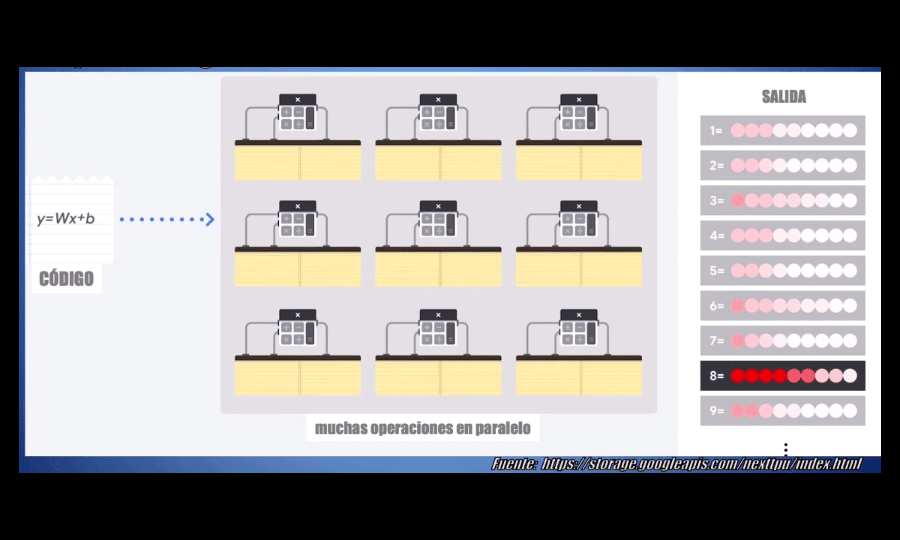
Sin embargo, las GPUs siguen teniendo una gran desventaja: a pesar de ser de propósito específico, es decir a pesar de haber sido pensadas para realizar un alto número de operaciones, no han sido diseñadas específicamente para el Machine Learning.
Las TPUs
Sin embargo, en 2013 Google comenzó a desarrollar la primera versión de lo que hoy se conoce como TPU (Tensor Processing Unit, o unidad de procesamiento de tensores). Esta es una arquitectura de computador pensada específicamente para el desarrollo de modelos de Machine Learning, y por tanto está optimizada para la realización de operaciones con matrices, que es precisamente el tipo de datos que usan las Redes Neuronales, las Redes Convolucionales, las Redes Recurrentes y LSTM, las Redes Transformer y, en general, todas las arquitecturas de Machine y el Deep Learning en la actualidad:
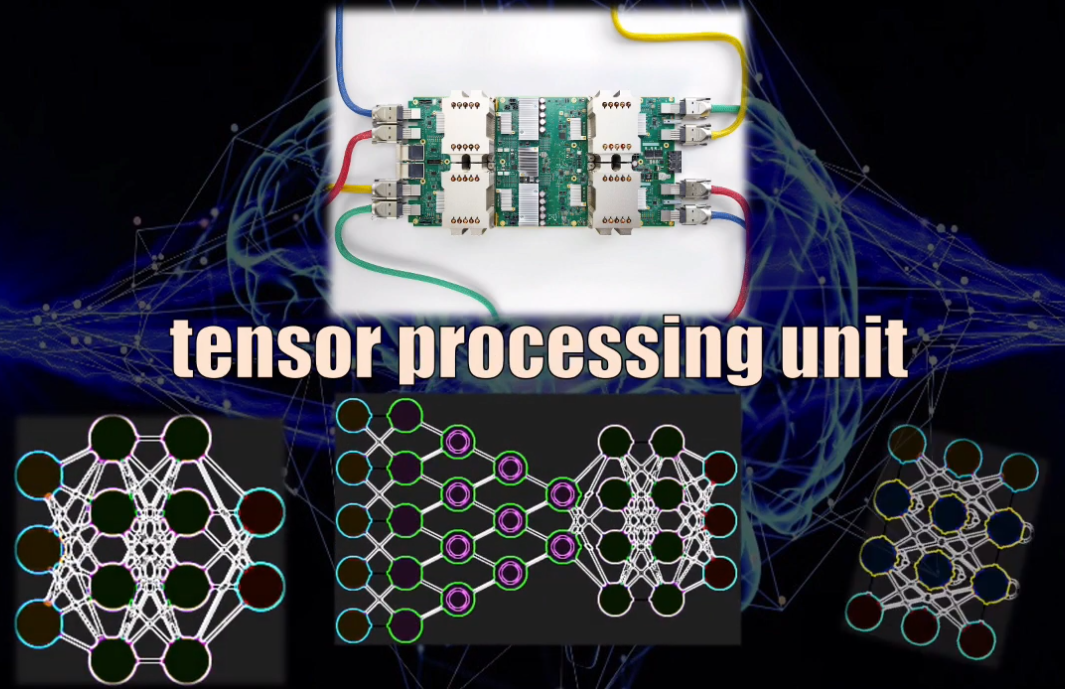
La TPU está optimizada para el Machine Learning, pues es capaz de realizar en paralelo miles de multiplicaciones y sumas (es decir operaciones matriciales) de manera simultánea, y durante este proceso no necesita acceder a la memoria del procesador en ningún momento (como sí ocurre con las CPUs y las GPUs):

Es por eso que una TPU es la arquitectura más potente hasta el momento para el desarrollo de modelos de Machine Learning, siendo cientos de veces más rápida que una GPU… y ni hablar de las CPUs.
Bien, ya tenemos clara la diferencia entre una CPU, una GPU y una TPU. Ahora sí hablemos de Google Colab.
Google Colab
Esta plataforma es de acceso libre, y nos permite ejecutar código Python en la nube. Para ello usa el formato de Jupyter Notebook, que es simplemente como una versión de Python “enriquecida”: además del código Python, es posible agregar texto con diferentes formatos o imágenes. Y todo el contenido de este “notebook” se puede ejecutar localmente (en nuestro computador) o en la nube (usando por ejemplo Google Colab):
Pero lo más interesante de Google Colab es que, por ser de Google y por estar desarrollada alrededor de Python, permite implementar modelos de Machine Learning usando la librería Tensorflow. Y no solo eso, también es posible acceder de forma gratuita a las GPUs y las TPUs que Google Colab tiene a disposición. Y esto es lo precisamente llamativo de esta plataforma: podemos entrenar modelos Deep Learning, usando tecnología de punta y de forma totalmente gratuita!
A continuación veremos cómo usar Google Colab, integrado con una cuenta de Google Drive, y con los procesadores ofrecidos por Google para desarrollar un modelo de Machine Learning en la nube.
Al igual que en el post anterior de esta serie, haremos uso de Tensorflow 2 y Keras para implementar una red convolucional capaz de clasificar imágenes del set Fashion MNIST. En particular vamos a ver detalladamente cómo usar las diferentes herramientas de Google Colab para implementar el modelo usando las diferentes arquitecturas disponibles: CPU, GPU y TPU.
Al final haremos una comparación que nos permitirá evidenciar las ventajas de las GPUs y TPUs sobre las CPUs convencionales. Recuerden que al final del post encontrarán los enlaces al código fuente y al set de datos usado en este tutorial.
Accediendo a Google Colab desde nuestra cuenta de Google
En primer lugar debemos acceder al sitio web de Google Colab. Después accedemos a nuestra cuenta de Google (botón Sign in en la esquina superior derecha de la pantalla), y en el cuadro de diálogo emergente oprimimos la opción de crear un nuevo notebook (New Notebook):
Modificamos el nombre del Notebook como queramos:
y listo. Hemos creado nuestro primer Notebook.
Ahora implementaremos nuestro clasificador usando la CPU.
Entrenamiento de una Red Convolucional usando una CPU
Ahora elegimos la CPU como la arquitectura a usar durante el entrenamiento. Para ello vamos al menú del Notebook, elegimos runtime y luego change runtime type:
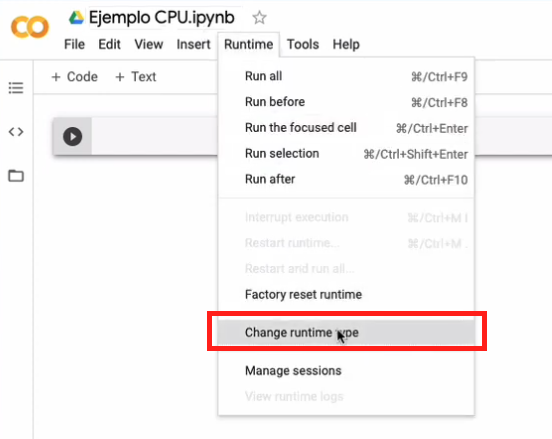
Y en el cuadro de diálogo emergente podemos elegir la versión de Python a usar (Python 3), y en la sección “Hardware accelerator” podemos escoger entre CPU, GPU y TPU. En este caso, la CPU corresponde a la opción “None”:
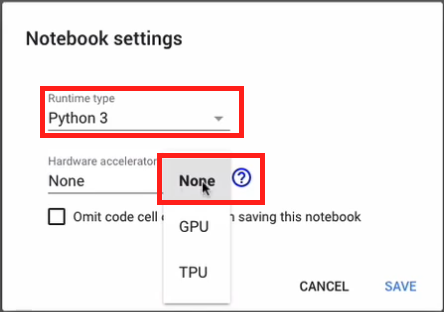
Bien, y estamos listos para hacer esta primera implementación.
Primero vamos a leer los datos. Aunque Tensorflow y Keras contienen ya funciones que permiten descargar el set Fashion MNIST, intencionalmente he guardado este set de datos en una carpeta de Google Drive, para mostrarles cómo desde Google Colab puedo leer y almacenar datos precisamente en Google Drive.
Así que crearemos inicialmente una función que nos permita cargar el set de imágenes de entrenamiento y validación, junto con la categoría a la que pertenece cada una de estas imágenes:
import numpy as np
import os
import gzip
def load_mnist(ruta, tipo='train'):
ruta_categorias = os.path.join(ruta, '%s-labels-idx1-ubyte.gz' % tipo)
ruta_imagenes = os.path.join(ruta, '%s-images-idx3-ubyte.gz' % tipo)
with gzip.open(ruta_categorias, 'rb') as rut_cat:
etiquetas = np.frombuffer(rut_cat.read(), dtype=np.uint8, offset=8)
with gzip.open(ruta_imagenes, 'rb') as rut_imgs:
imagenes = np.frombuffer(rut_imgs.read(), dtype=np.uint8, offset=16).reshape(len(etiquetas), 784)
return imagenes, etiquetas
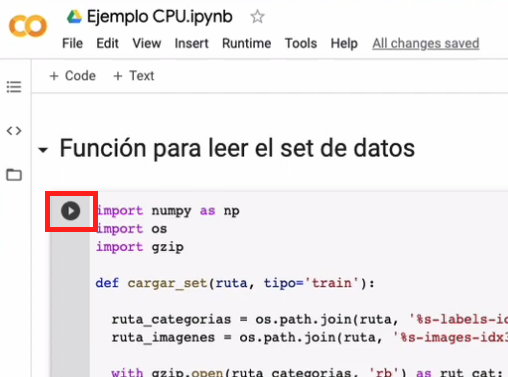
En la celda de código que acabamos de crear aparece un pequeño ícono del lado izquierdo. Al presionar este ícono podemos ejecutar el código en la CPU disponible en Google Colab:
Ahora sí vamos a importar la librería “drive” de Google Colab, que nos permitirá hacer la lectura de datos desde Google Drive. Una vez importada la librería, “montamos” nuestro “drive” en el servidor remoto de Google Colab y luego definimos la ruta completa en donde se encuentran almacenados los datos.
Al ejecutar la función que creamos anteriormente, el programa accede a la ruta de Google Drive especificada y por seguridad nos pide un código de autorización para poder acceder a los datos almacenados en esa carpeta. Ingresamos al enlace indicado, copiamos el código de autorización, lo pegamos en nuestro notebook y oprimimos la tecla Enter. Y listo, ya hemos logrado importar los datos almacenados en nuestro Google Drive y llevarlos así al servidor de Google Colab.
Estas son entonces las líneas de código que permiten acceder al “drive” y cargar el set de datos generando los respectivos sets de entrenamiento y validación:
from google.colab import drive
drive.mount('/content/gdrive')
ruta = 'gdrive/My Drive/Colab Notebooks/fashion_mnist_data'
X_train, Y_train = load_mnist(ruta, tipo='train')
X_test, Y_test = load_mnist(ruta, tipo='test')
Antes de crear el modelo debemos hacer dos ajustes en los datos.
Primero debemos garantizar que el set de entrenamiento contenga un número de datos que sea exactamente un múltiplo de 128. ¿Y esto por qué es necesario? Por que en el caso de la TPU la arquitectura requiere precisamente que durante el entrenamiento presentemos bloques de datos que sean múltiplos de 128 (es decir, 128, 256, 512, etcétera). Aunque esto no es necesario para la CPU ni la GPU, lo haremos en este paso para poder comparar los resultados con las otras arquitecturas.
El número más cercano a 60000 y que es a la vez múltiplo de 128 es 59904, así que reajustaremos el set de entrenamiento a este tamaño. De forma equivalente, el set de validación tiene originalmente 10000 datos, y lo reajustaremos a un tamaño de 9984.
Finalmente, usamos “reshape” para reajustar el tamaño de los sets de entrenamiento y validación y así garantizar que cada dato es una imagen en escala de grises de 28 x 28 pixeles, que será la entrada a la red convolucional que queremos entrenar.
Este es el código a utilizar para reajustar nuestros sets de datos:
X_train = X_train[0:59904,:]
X_test = X_test[0:9984,:]
Y_train = Y_train[0:59904]
Y_test = Y_test[0:9984]
X_train = np.reshape(X_train,(59904,28,28,1))
X_test = np.reshape(X_test,(9984,28,28,1))
¡Ahora sí vamos a implementar el modelo!
Lo primero que debemos hacer es importar Tensorflow 2. En este caso, teniendo en cuenta que la plataforma es Google Colab, debemos primero usar especificar que queremos importar la versión 2 y luego de esto sí importamos TensorFlow usando la directiva import.
También fijamos la semilla del generador aleatorio a un valor fijo (en este caso 200) que será el mismo valor que usaremos para la implementación en GPU y en TPU. Con esto garantizamos que todos los coeficientes de los modelos se inicializan de forma aleatoria pero en el mismo valor, lo que nos permitirá comparar los resultados una vez hecho el entrenamiento. Es decir que con esta semilla garantizamos la reproducibilidad del entrenamiento.
Al ejecutar esta parte del código vemos que efectivamente Google Colab está importando la versión 2 de Tensorflow.
%tensorflow_version 2.x # Para garantizar que la versión 2.x sea importada
import tensorflow as tf
print('Versión de TensorFlow: ' + tf.__version__)
tf.random.set_seed(200)
Para implementar el modelo usaremos la librería Keras, que, como lo vimos en el post sobre la [introducción a Tensorflow], ya viene instalada por defecto en Tensorflow 2.
Primero creamos el contenedor del modelo usando el módulo Sequential y después agregamos progresivamente las tres capas convolucionales. Estas tres capas son prácticamente idénticas: primero hacemos una normalización (para facilitar la convergencia del entrenamiento), luego agregamos los filtros convolucionales, luego agregamos una capa max pooling y finalmente una capa dropout para reducir el overfitting del modelo. La única diferencia entre estas tres capas radica en el número de filtros convolucionales usados: 64 para la primera capa, 128 para la segunda y 256 para la tercera:
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
Después de la tercera capa convolucional aplanamos los datos (usando el módulo Flatten) y agregamos una Red Neuronal con 256 neuronas, que posteriormente conectaremos a la salida, la cual contendrá 10 neuronas y tendrá una función de activación softmax para clasificar cada una de las imágenes entrantes:
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('elu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
La implementación del modelo en Google Colab, es decir en la nube, ¡es idéntica a la que haríamos si lo estuviésemos implementando localmente en nuestros computadores!.
Antes del entrenamiento, compilamos el modelo, es decir que definimos el optimizador a usar (Adam), la función de error (la entropía cruzada) y la métrica de desempeño (la precisión):
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
Para finalizar vamos a entrenar nuestro modelo: como se trata de una Red Convolucional compleja, con más de 1’600 mil parámetros (para ver esto podemos usar model.summary()), y como estamos usando una CPU, el tiempo de procesamiento va a ser extremadamente lento, así que realizaremos sólo dos iteraciones de entrenamiento.
Para tener un punto de comparación con las otras dos arquitecturas (GPU y TPU), usaremos la función “timeit” de Python para almacenar en una variable el tiempo promedio de ejecución de cada iteración.
El entrenamiento lo realizamos de la forma convencional: usamos la función “fit” y especificamos: el set de entrenamiento, el set de validación, el tamaño del lote y el número de iteraciones:
import timeit
def entrenamiento_cpu():
with tf.device('/cpu:0'):
model.fit(X_train,Y_train,validation_data=(X_test,Y_test),batch_size=128,epochs=2,verbose=1)
return None
cpu_time = timeit.timeit('entrenamiento_cpu()', number=1, setup='from __main__ import entrenamiento_cpu')
Este entrenamiento tomará algo de tiempo (por tratarse de una CPU y de un modelo tan grande). Al culminar estas dos iteraciones veremos que, para esta configuración, el tiempo requerido (que se puede mostrar en pantalla imprimiento la variable cpu_time) es de ¡casi 26 minutos de entrenamiento!
Veamos ahora qué sucede si implementamos y entrenamos el mismo modelo pero usando una GPU.
Entrenamiento de la misma Red Convolucional usando una GPU
En este caso observaremos que el entrenamiento será decenas de veces más rápido que en el ejemplo anterior.
La lectura de los sets de entrenamiento y validación, el reajuste de los datos y la implementación del modelo es idéntica al caso de la CPU. Así que nos enfocaremos únicamente en los cambios que debemos hacer para poder entrenar el modelo con una GPU.
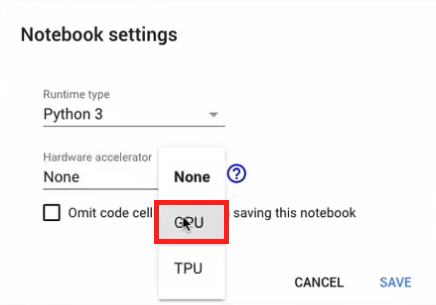
Al igual que en el caso de la CPU, en primer lugar debemos cambiar la arquitectura. Así que accedemos nuevamente al menú runtime – change runtime type y en el cuadro de diálogo emergente verificamos que la opción escogida sea “GPU”:
Ahora verificamos la disponiblidad de esta GPU usando el módulo test y en particular la función gpu_device_name de Tensorflow. Con esto nos aseguramos de que la GPU asignada por Google Colab esté disponible para realizar el entrenamiento:
nombre_gpu = tf.test.gpu_device_name()
if nombre_gpu != '/device:GPU:0':
raise SystemError('GPU no encontrada')
print('GPU encontrada: {}'.format(nombre_gpu))
Si la GPU fue encontrada, podemos realizar el entrenamiento usando exactamente la misma línea de código del ejemplo anterior: en el módulo fit especificamos los sets de entrenamiento y validación, el tamaño del lote y las dos iteraciones, y de nuevo almacenamos el tiempo requerido usando el módulo “timeit” de Python:
import timeit
def entrenamiento_gpu():
with tf.device('/device:GPU:0'):
model.fit(X_train,Y_train,validation_data=(X_test,Y_test),batch_size=128,epochs=2,verbose=1)
return None
gpu_time = timeit.timeit('entrenamiento_gpu()', number=1, setup='from __main__ import entrenamiento_gpu')
Al realizar el entrenamiento vemos una diferencia abismal en el desempeño, pues de hecho las dos iteraciones requieren tan sólo un poco más de 20 segundos, comparadas con los casi 26 minutos requeridos por la CPU. ¡Esto es 60 veces más rápido!
Por último, veamos qué ocurre con la TPU
Entrenamiento de la misma Red Convolucional usando una TPU
De nuevo, el código para la lectura y pre-procesamiento del set de datos no tendrá modificación alguna.
Al igual que en los dos ejemplos anteriores, en este caso lo primero que debemos hacer es especificar la TPU como hardware de entrenamiento. De nuevo, entramos a runtime, change runtime type y en el cuadro de diálogo hardware accelerator seleccionamos la opción “TPU”:
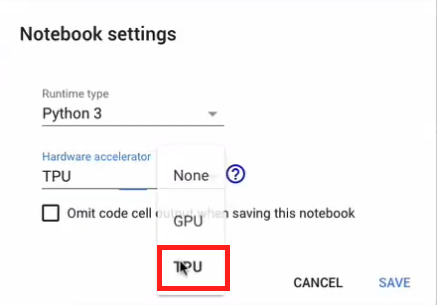
Ahora corremos el código para detectar la TPU usando el modulo distribute y la función cluster_resolver de Tensorflow:
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) # Detectar TPU
print('TPU encontrada ', tpu.cluster_spec().as_dict()['worker'])
except ValueError:
raise BaseException('ERROR: TPU no encontrada!')
Una vez realizado esto llevamos a cabo los siguientes pasos:
- Nos conectamos al cluster de Google Colab en el cual está la TPU, usando la función
experimental_connect_to_cluster - Inicializamos la TPU usando la función
initialize_tpu_system - Y finalmente creamos un objeto tipo
TPUStrategyque se requiere para poder crear el modelo.
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
Bien, habiendo llevado a cabo estos pasos copiamos exactamente las mismas líneas de código para crear y compilar el modelo, con la única diferencia de que estas líneas estarán ubicadas dentro de un bloque with en donde precisamente usaremos el objeto TPUstrategy para poder crear el modelo correctamente y que este pueda correr sobre la TPU de Google Colab:
with tpu_strategy.scope():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=X_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('elu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
Para el entrenamiento usamos de nuevo fit, con la única diferencia de que debemos convertir los datos de entrenamiento y validación al formato punto flotante con 32 bits, que es el formato de almacenamiento requerido por Google Colab para sus TPUs:
import timeit
x_train = X_train.astype(np.float32)
y_train = Y_train.astype(np.float32)
x_test = X_test.astype(np.float32)
y_test = Y_test.astype(np.float32)
def entrenamiento_tpu():
model.fit(x_train,y_train,validation_data=(x_test,y_test), batch_size=128, epochs=2, verbose=1)
return None
tpu_time = timeit.timeit('entrenamiento_tpu()', number=1, setup='from __main__ import entrenamiento_tpu')
Al hacer el entrenamiento vemos que el tiempo requerido para las dos iteraciones es de casi 21 segundos, ligeramente inferior al tiempo requerido en la GPU y, de nuevo, decenas de veces más rápido que el tiempo requerido por la CPU.
Pero un momento, ¿no habíamos dicho que la TPU es muuuucho más veloz que la GPU? Sin embargo al comparar los tiempos de entrenamiento vemos que en realidad la GPU ligeramente más veloz. ¿Qué ocurre en este caso?
Lo que sucede es que la TPU es una arquitectura pensada para desarrollar modelos mucho mas complejos que la red convolucional que estamos implementando, y a su vez para datos mucho más grandes que las imágenes de 28x28 de los sets de entrenamiento y validación. Así que en este ejemplo en particular no resultan tan evidentes estas diferencias con respecto a la GPU.
A medida que el modelo se hace cada vez más complejo (con más y más parámetros por entrenar), empezaremos a notar diferencias significativas entre la GPU y la TPU.
Otras herramientas útiles de Google Colab
En todo momento de la ejecución de nuestro Notebook, podemos dirigirnos a la esquina superior derecha de Google Colab, y allí observaremos un ícono que nos proporciona información sobre la memoria RAM y el espacio en disco duro que estamos usando en esta máquina virtual:

Allí podemos ver la memoria RAM destinada por Google Colab para esta máquina virtual así como el disco duro disponible.
También resulta útil tener en cuenta que el Notebook es almacenado no solo en la nube sino localmente en nuestro Google Drive, y que lo podemos encontrar dentro de la carpeta “Colab Notebooks”.
Set de datos y código fuente
En este enlace de Github podrás descargar el set de datos y el código fuente de este tutorial.
Conclusión
Bien, acabamos de ver un tutorial completo de Google Colab y a través de estos ejemplos aprendimos a utilizar Tensorflow y las máquinas virtuales ofrecidas por Google para de forma totalmente gratuita entrenar modelos Deep Learning en la nube.
Sin duda alguna Google Colab es una opción interesante para desarrollar este tipo de modelos, pues podemos tener acceso a arquitecturas de hardware muy potentes para el entrenamiento, como las GPUs o las TPUs. Aunque no todo es gratis: una limitación a tener en cuenta es que Google Colab ofrece 12 horas consecutivas de uso, lo que limitaría el tiempo disponible para entrenar algunos modelos muy complejos.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: