Tutorial: Recomendador musical con Spotify - Parte 2: filtrado basado en contenido
En esta segunda parte del tutorial veremos cómo usar el filtrado basado en contenido para construir una lista de reproducción en Spotify.
Al final de este tutorial se encuentra el enlace para descargar el código fuente.
Así que ¡listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este artículo:
Introducción
En esta segunda parte tomaremos la lista de pistas más escuchadas y de pistas candidatas obtenidas en la primera parte de este tutorial para construir una lista de reproducción con las pistas que mejor se ajustan a los gustos del usuario.
Para ello haremos uso de lo que se conoce como el filtrado basado en contenido, un enfoque propio de los sistemas de recomendación, así como de la API de Spotify.
En la tercera para de este tutorial veremos cómo combinar todos estos elementos en un aplicativo web para este sistema de recomendación.
Comencemos viendo las principales características de este sistema de recomendación y del filtrado basado en contenido.
Sistema de recomendación
El propósito de nuestro sistema de recomendación es generar una lista de reproducción en Spotify con las canciones que más se asemejen a los gustos del usuario:
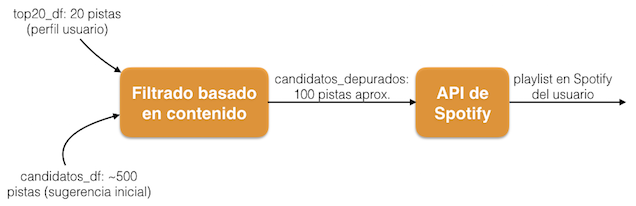
Para ello:
-
Tomaremos el listado de pistas candidatas (
candidatos_df) y las compararemos con cada una de las pistas más escuchadas por el usuario (top20_df). Estos dos listados fueron obtenidos en la parte 1 de este tutorial. Esta “comparación” nos permitirá descartar las pistas con menor grado de semejanza y preservar aquellas que más se parecen a las más escuchadas: ¡y esto es precisamente el filtrado basado en contenido! -
Tras realizar este filtrado pasaremos de un listado de un poco más de 500 pistas candidatas a un listado de pistas filtradas con aproximadamente 100 canciones.
-
El último paso será tomar este listado filtrado y crear la lista de reproducción en Spotify, para lo cual usaremos la librería spotipy junto con la API de Spotify (de las cuales hablamos en la primera parte de este tutorial).
El primer elemento de este sistema de filtrado basado en contenido es el cálculo de la similitud del coseno, de la que hablaremos precisamente a continuación.
La similitud del coseno
Para poder realizar el filtrado basado en contenido necesitamos en primer lugar comparar de forma cuantitativa cada pista en candidatos_df con cada canción en top20_df. Y una forma de realizar esta comparación es usando la similitud del coseno.
Para hacer esto recordemos que cada pista (tanto en candidatos_df como en top20_df) es simplemente un vector de 12 elementos, donde cada uno de ellos es una cantidad numérica que representa una característica sonora de la pista en cuestión (danceability, acousticness, valence, etc.):
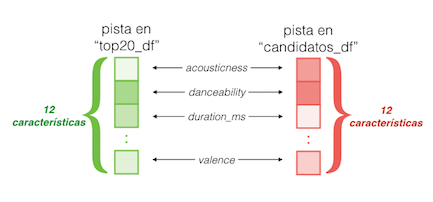
Así que la similitud del coseno toma como entrada dos de estos vectores (uno proveniente de top20_df y otro de candidatos_df) y realiza estas operaciones:
- Calcula primero el producto punto entre los dos vectores y
- Lo divide entre la magnitud de cada uno de ellos
El resultado de esta operación es equivalente a encontrar el coseno del ángulo entre estos dos vectores (que en este caso estaría en un espacio de ¡12 dimensiones), que es precisamente la similitud del coseno.
Esta similitud del coseno es simplemente una cantidad numérica (con valores entre -1 y 1) que permite medir el grado de similitud entre los dos vectores: cuando los vectores son similares la similitud del coseno será cercana a 1 mientras que vectores disímiles tendrán valores mucho menores a 1 (incluso cercanos a 0 o a -1):
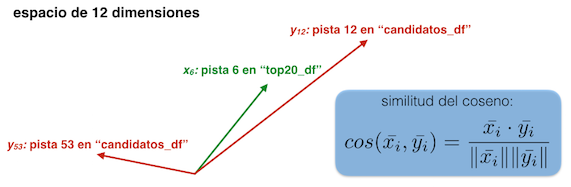
Veamos cómo implementar esta similitud del coseno en Python. En primer lugar extraeremos las características sonoras de cada pista en top20_df y candidatos_df y almacenaremos los resultados en arreglos de Numpy:
top20_mtx = top20_df.iloc[:,1:].values
candidatos_mtx = candidatos_df.iloc[:,1:].values
en donde en las líneas anteriores hemos usado el atributo values de cada DataFrame de Pandas para extraer únicamente los arreglos de interés.
Cada columna de los arreglos resultantes será precisamente una característica sonora. Sin embargo, los rangos de valores entre una característica y otra (es decir entre diferentes columnas) no son los mismos, por lo cual debemos hacer un “escalamiento” de estos datos para que resulten siendo comparables y poder así calcular correctamente la similitud del coseno.
Este “escalamiento” se conoce como estandarización y se debe aplicar a cada columna, para lo cual:
- Se calcula el promedio de la columna
- Se calcula la desviación estándar de la columna
- A cada elemento de la columna se resta el valor obtenido en (1) y se divide entre el valor obtenido en (2)
El resultado de este procedimiento es que cada columna tendrá un valor promedio de cero y una desviación estándar de 1, con lo cual los valores entre una y otra columna resultarán siendo comparables.
Para realizar esta estandarización usaremos la librería Scikit-learn y en particular el módulo StandardScaler():
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
t20_scaled = scaler.fit_transform(top20_mtx)
can_scaled = scaler.fit_transform(candidatos_mtx)
en donde en las dos últimas líneas hemos usado el método fit_transform para aplicar como tal la estandarización.
El siguiente paso es normalizar cada vector de características, es decir cada fila en los arreglos t20_scaled y can_scaled. Esta normalización consiste simplemente en dividir cada elemento del vector entre su magnitud, un paso intermedio requerido para el cálculo de la similitud del coseno, pues como vimos en la figura anterior este cálculo requiere dividir el resultado del producto punto entre la magnitud de cada vector que estamos comparando.
La magnitud de cada vector de características se calcula simplemente como la raíz cuadrada de la suma del cuadrado de cada uno de sus elementos ($magnitud = \sqrt{elemento_1^2 + elemento_2^2 + …}$), para lo cual usaremos la función sqrt de Numpy:
import numpy as np
t20_norm = np.sqrt((t20_scaled*t20_scaled).sum(axis=1))
can_norm = np.sqrt((can_scaled*can_scaled).sum(axis=1))
Con esto sólo resta tomar cada vector estandarizado (t20_scaled y can_scaled) y dividirlo entre su correspondiente magnitud para obtener los vectores normalizados:
nt20 = t20_scaled.shape[0]
ncan = can_scaled.shape[0]
t20 = t20_scaled/t20_norm.reshape(nt20,1)
can = can_scaled/can_norm.reshape(ncan,1)
en donde hemos usado el método reshape para redimensionar el denominador y garantizar que tenga el mismo tamaño del numerador durante el cálculo.
Y ahora sí finalmente teniendo estos vectores de características sonoras normalizados podemos calcular la similitud del coseno. De nuevo usaremos la librería Scikit-learn y el método linear_kernel para calcular, en una sola línea de código, las similitudes del coseno entre pares de pistas del top-20 y candidatas:
from sklearn.metrics.pairwise import linear_kernel
cos_sim = linear_kernel(t20,can)
cos_sim.shape
Con la última línea de código anterior lo que hacemos es imprimir en pantalla el tamaño de la matriz resultante:
(20, 543)
y en este caso verificamos que este tamaño es de 20 filas (equivalentes a las 20 pistas del top-20) y 543 columnas (equivalentes a las 543 pistas candidatas).
Cada elemento en la matriz cos_sim será una cantidad numérica que nos indica el grado de similitud entre una pista del top-20 y una pista candidata.
Por ejemplo:
print(cos_sim[6,270])
print(cos_sim[3,24])
nos arroja como resultado estos valores:
0.5215138618987606
0.007047208799871543
Lo cual nos indica que el grado de similitud entre la pista 5 del top-20 y la pista candidata 269 (cos_sim[6,270]) es de 0.52, mientras que entre la pista 2 del top-20 y la pista candidata 23 (cos_sim[3,24]) es de tan sólo 0.00704. Esto quiere decir que la pista candidata 269 se asemeja más a los gustos del usuario que la pista 23.
Con esto ya estamos listos para llevar a cabo el filtrado basado en contenido y elegir las pistas candidatas que más se asemejan a las pistas originales del top-20.
Filtrado basado en contenido
Teniendo el grado de similitud entre las pistas del top-20 y las candidatas resulta muy sencillo definir cuáles de estas últimas se incluirán en la lista de reproducción sugerida por este sistema de recomendación.
Para ello definiremos un umbral:
- Si la similitud del coseno es mayor o igual a dicho
umbralpodremos asumir que la pista se asemeja bastante a los gustos del usuario y la incluiremos en la lista de reproducción - De lo contrario el grado de similitud es bajo y no la incluiremos en la playlist a generar
Teniendo en cuenta que la similitud del coseno está en el rango de -1 a 1, donde 1 indica un alto grado de similitud, tomaremos un valor de 0.8 como umbral de decisión.
Así que crearemos la función obtener_candidatos que tomará como entrada el índice de una pista en el top-20 (pos), la matriz de similitudes del coseno (cos_sim), el número máximo de pistas candidatas a incluir tras este filtrado (ncands) y por supuesto el umbral (umbral = 0.8):
def obtener_candidatos(pos, cos_sim, ncands, umbral = 0.8):
# Obtener todas las pistas candidatas por encima de umbral
idx = np.where(cos_sim[pos,:]>=umbral)[0] # ejm. idx: [27, 82, 135]
# Y organizarlas de forma descendente (por similitudes de mayor a menor)
idx = idx[np.argsort(cos_sim[pos,idx])[::-1]] # [::-1] porque por defecto argsort organiza de manera ascendente
# Si hay más de "ncands", retornar máximo "ncands"
if len(idx) >= ncands:
cands = idx[0:ncands]
else:
cands = idx
return cands
donde la lista cands contendrá los índices de las pistas que han sido filtradas y que serán posteriormente incluidas en la playlist.
Veamos un ejemplo de uso: tomemos la función obtener_candidatos que acabamos de crear y obtengamos un listado de pistas filtradas que más se asemejen a las primeras 5 pistas del top-20:
for i in range(5):
cands = obtener_candidatos(i, cos_sim, 5)
print(f'{i}==> pistas filtradas: {cands}, similitudes: {cos_sim[i,cands]}')
obteniendo este resultado:
0==> pistas filtradas: [], similitudes: []
1==> pistas filtradas: [ 71 78 334], similitudes: [0.89542617 0.85824661 0.80710631]
2==> pistas filtradas: [58], similitudes: [0.85491718]
3==> pistas filtradas: [], similitudes: []
4==> pistas filtradas: [306 503 251 40 17], similitudes: [0.82675576 0.82611856 0.81411 0.8088681 0.80771745]
Podemos ver en este caso que por ejemplo ninguna de las pistas cantidatas se asemeja a la pista 0 del top-20, mientras que para el caso de la pista 4 tenemos un total de 5 pistas candidatas (306, 503, 251, 40 y 17) con un alto grado de semejanza (es decir con similitudes del coseno mayores o iguales a 0.8).
Así que ya tenemos el código para realizar este filtrado basado en contenido. Lo único que nos resta entonces es tomar los listados de pistas filtradas y con estos crear la lista de reproducción en Spotify.
Creación de la lista de reproducción en Spotify
Para crear esta lista usaremos la librería spotipy y la API de Spotify (de las cuales hablamos en la primera parte de este tutorial).
En esta lista de reproducción incluiremos únicamente el campo 'id' de cada pista filtrada, pues es el único elemento requerido por la API de Spotify.
Así que para determinar las pistas a incluir en esta lista seguiremos este procedimiento:
- Iteraremos sobre cada una de las pistas del top-20
- Realizaremos el filtrado basado en contenido con la función
obtener_candidatosdescrita hace un momento y extraeremos únicamente los campos'id'de cada pista filtrada - Añadiremos las pistas (ids) a la lista
- Repetiremos los pasos 1 a 3 para todas las 20 pistas del top-20
A continuación el código que implementa este procedimiento:
ids_t20 = []
ids_playlist = []
for i in range(top20_df.shape[0]):
print(top20_df.index[i]) # Nombre de la pista en el top-20
ids_t20.append(top20_df['id'][i])
# Obtener listado de candidatos para esta pista
cands = obtener_candidatos(i, cos_sim, 5, umbral=0.8)
# Si hay pistas relacionadas obtener los ids correspondientes
# e imprimir en pantalla
if len(cands)==0:
print(' ***No se encontraron pistas relacionadas***')
else:
# Obtener los ids correspondientes e imprimir en pantalla
for j in cands:
id_cand = candidatos_df['id'][j]
ids_playlist.append(id_cand)
# E imprimir en pantalla el candidato
print(f' {candidatos_df.index[j]}')
Acá un ejemplo de las pistas que obtenemos asociadas a las tres primeras canciones del top-20:
The Adults Are Talking
***No se encontraron pistas relacionadas***
ZITTI E BUONI
More-More-More
ZITTI E BUONI
20/20 Vision
Chosen
Oblivion
Es probable que algunas de las pistas sugeridas ya se encuentren incluidas en el top-20. De ser así debemos eliminarlas de nuestra playlist:
ids_playlist_dep = [x for x in ids_playlist if x not in ids_t20]
Y también es posible que existan pistas repetidas, por lo cual también debemos realizar una depuración adicional:
ids_playlist_dep = list(set(ids_playlist_dep))
¡Y listo, ya tenemos nuestro listado con las pistas sugeridas! En este caso particular este listado tendrá 35 identificadores correspondientes a pistas en el catálogo de Spotify:
['70ezKh3AXSA29EXbYZXvHM', '4eAy0nOh3g1fwGAb2OVQtD', '6PEQCw5UdjZDpsOxVV8AuG', '2Ye7dgHsrrb8Dw2d9SKHGJ', '3Ye5icBka8ODjcaEQakPvZ', '31RJ1xFMQCGfGniKY4IMdO', '0lgiMprywlwW4XlzrnZHCA', '3W3WNGmdYd0XkIDnCUA9P8', '52a1wWAZ206Ptr50JHaoex', '15m0MEyKTpuwwdEBGAghyL', '4t1rSpSMbGuiWUokubPtes', '3MFOpHTQc46TdIIILH9dAd', '51KMpn0p5Vb7XVdV7mWau5', '4joEqwMI7bdqunkVZ6zTqU', '5DlfBSLJiuoiWbP5WKocMI', '3MY5hKy9nT2D1gEdg3UFVv', '6lMPUipRF49L8AxLW3F40B', '6QonLH4JR5jpbLRKGAiTXc', '3dExW6DT0o338hTZA74hAl', '5IU4Ym8qNpQFIo0EXUceRr', '4VwXf1G5Is02g6pgBbYw9s', '1cnBCwceV5NhMkpzc9sdDF', '5hpyKjTtr5HsvdgLatWzJt', '3s9febMNqBjDT0o0q5hbWt', '507Z8HdRGcRExCKrc3jcp2', '5Ti7Suj14N5hmMOWdjpDrA', '3TtDUP3ijbAmWLmDAyrBe1', '16muBPcWmkHSl1uM4tE8WL', '0a70Tloqeldzv0Hp9CvgeT', '0SlVngDKKsbGjo1V0mOtG7', '7vBczWEtVRGXkI5HOISv7L', '77NmNVQxwbKwE1HqptcAKi', '3wKSnl3YTPTcyHY2hSxfde', '3oF1sqZpoarrfWGk2CGq19', '6Jg5VEDvoEtwgM2ZfkI2wS']
Lo único que nos resta es tomar este listado y crear la lista de reproducción en Spotify. Para ello usaremos la variable sp que contiene la información de acceso a la API (y de la cual hablamos en detalle en el artículo anterior) y en particular el método user_playlist_create, en donde especificaremos el nombre de usuario (user = username), el nombre que tendrá la lista en la aplicación (name = 'Spotipy Recommender Playlist') y una breve descripción (argumento description):
pl = sp.user_playlist_create(user = username,
name = 'Spotipy Recommender Playlist',
description = 'Playlist creada con el sistema de recomendación')
Una vez creada esta playlist simplemente la añadimos a nuestro usuario a través del método playlist_add_items:
sp.playlist_add_items(pl['id'],ids_playlist_dep)
¡Y listo, ya hemos creado la lista de reproducción con las recomendaciones! Para verificarlo simplemente podemos abrir la aplicación de Spotify y comenzar a disfrutar de esta playlist.
Conclusión
Muy bien, acabamos de ver cómo usar el concepto de similitud del coseno y las características sonoras de las pistas escuchadas por el usuario y las canciones candidatas para realizar un filtrado basado en contenido y generar una lista de reproducción directamente en la aplicación de Spotify.
En la tercera parte de este tutorial veremos como conectar este backend (el sistema de recomendación que acabamos de construir) con un frontend que será simplemente una página web y que facilitará nuestra interacción con el sistema de recomendación.
Así que en la última parte de este tutorial veremos cómo construir el aplicativo web para este sistema de recomendación usando lo implementado hasta el momento junto con la librería Flask.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Código fuente
En este enlace de Github está disponible el código fuente de este tutorial.