Tutorial: Reconocimiento Facial con Machine Learning en Python
En este tutorial veremos paso a paso cómo usar las redes MobileNet y FaceNet para implementar en Python un sistema de Reconocimiento Facial usando Machine Learning.
En los dos artículos anteriores vimos cómo funcionan los sistemas de detección de rostros y de reconocimiento facial, los cuales hacen uso de diferentes tipos de Redes Convolucionales. El primero de ellos permite encontrar las regiones de una imagen que contienen rostros humanos, mientras que el segundo permite determinar a qué sujeto pertenece cada uno de estos rostros.
En este tutorial combinaremos estas ideas para implementar en Python un sistema de reconocimiento facial, capaz de tomar una imagen con múltiples rostros y de determinar, para cada uno de ellos, si corresponden o no a un rostro de referencia.
Al final de este tutorial se encuentra el enlace para descargar el código fuente.
Así que, ¡listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción: el problema a resolver
La idea del tutorial será desarrollar un sistema que sea capaz de determinar si en una imagen, que puede contener uno o múltiples rostros, se encuentra el rostro de un sujeto en particular.
Es decir que en particular implementaremos un sistema de verificación. Para esto usaremos cuatro imágenes de referencia (a la izquierda en la figura de abajo) y una serie de imágenes de prueba (a la derecha en la figura de abajo):

La idea es que el sistema sea capaz de encontrar en cuáles de las imágenes de prueba se encuentra el sujeto de referencia. Y esto a pesar de que tanto en el set de referencia como en el de prueba no se encuentran rostros idénticos.
Por ejemplo, en la imagen anterior podemos ver que las imágenes de prueba contienen cuatro rostros que pertenecen al mismo sujeto (¡a mí más exactamente!) pero en donde los gestos o la pose son diferentes. De igual manera este mismo sujeto se encuentra en las imágenes de referencia pero con otros gestos o con otras poses, o incluso usando gafas oscuras.
Adicionalmente podemos ver que las imágenes de prueba pueden contener varios sujetos, y que en la mayoría de ellas no se encuentra únicamente el rostro sino también parte del cuerpo u otros objetos dentro de la escena.
La idea es lograr construir un sistema de Machine Learning lo suficientemente robusto como para que, en primer lugar, logre detectar con precisión todos y cada uno de los rostros presentes en la escena y, en segundo lugar, logre discriminar en las imágenes de prueba los rostros que no corresponden al sujeto de referencia.
Para ello resolveremos el problema en dos fases: primero implementaremos un sistema de detección de rostros, para lo cual usaremos la red MobileNet pre-entrenada para esta tarea. Esta primera etapa generará unas regiones de interés que contendrán las coordenadas de cada rostro presente en la imagen. Posteriormente, cada uno de estos rostros será llevado a un sistema de reconocimiento facial, que hará uso de la red FaceNet y que se encargará de realizar el proceso de verificación, es decir de determinar si el rostro en cuestión pertenece o no al sujeto de referencia:
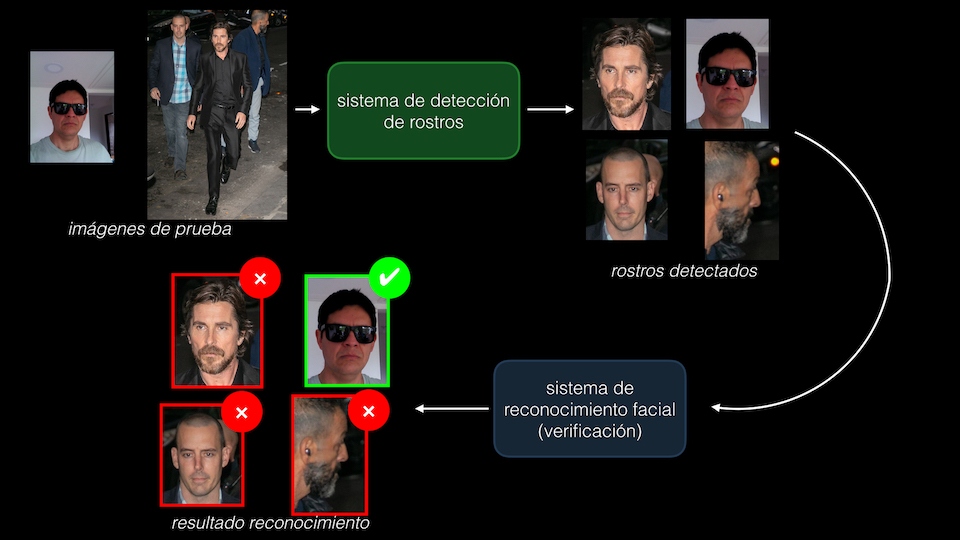
Veamos entonces cómo implementar paso a paso este sistema de reconocimiento facial.
Inicialización y funciones de utilidad
En primer lugar definiremos algunas variables de inicialización y crearemos algunas funciones que resultarán útiles para la lectura y visualización de los resultados en las diferentes etapas de implementación del sistema.
Las variables DIR_KNOWNS y DIR_UNKNOWNS permitirán acceder a los directorios que contienen las imágenes de referencia y las de prueba, respectivamente, mientras que DIR_RESULTS corresponde al directorio en donde almacenaremos el resultado del reconocimiento facial. En todos los casos estos directorios se encuentran en la misma carpeta del código fuente de este tutorial:
DIR_KNOWNS = 'knowns'
DIR_UNKNOWNS = 'unknowns'
DIR_RESULTS = 'results'
Creemos ahora dos funciones. La primera de ellas nos permitirá realizar la lectura de las imágenes tanto de referencia como de prueba. Para esto haremos uso de la librería OpenCV, específicamente diseñada para el procesamiento de imágenes:
import cv2
def load_image(DIR, NAME):
return cv2.cvtColor(cv2.imread(f'{DIR}/{name}'), cv2.COLOR_BGR2RGB)
La segunda función nos permitirá dibujar, sobre la imagen, el resultado de la detección de rostros:
def draw_box(image,box,color,line_width=6):
if box==[]:
return image
else:
cv2.rectangle(image,(box[0],box[2]),(box[1],box[3]),color,line_width)
return image
Si no se detecta ningún rostro en la imagen (if box==[]) la función retornará la imagen original, mientras que en caso contrario dibujará un rectángulo (cv2.rectangle) en las coordenadas específicas de la imagen y con el color definido por el usuario.
Bien, con estos elementos ya definidos podemos comenzar a implementar la primera fase del sistema: la detección de rostros.
Detección de rostros con MobileNet
Lectura del modelo pre-entrenado
Como lo mencioné anteriormente, para esta tarea haremos uso de MobileNet, una Red Convolucional especializada en la detección de objetos y optimizada para ejecución en dispositivos móviles, y que en este caso ha sido entrenada específicamente para la detección de rostros. Al final del artículo se encuentra el enlace para descargar este modelo.
Este modelo pre-entrenado está almacenado en un formato de grafo de TensorFlow. Para realizar la lectura usaremos las funciones io.gfile y import_graph_def de TensorFlow, y el modelo será almacenado en la variable mobilenet:
import tensorflow as tf
with tf.io.gfile.GFile('mobilenet_graph.pb','rb') as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as mobilenet:
tf.import_graph_def(graph_def,name='')
En el código anterior mobilenet_graph.pb hace referencia precisamente al archivo que contiene el modelo pre-entrenado.
Función para la detección de rostros
Ahora implementaremos la función encargada de realizar la detección. Esta función tendrá como entradas la imagen original y un umbral (score_threshold). Este umbral se requiere pues, como lo vimos en el artículo sobre detección de rostros, MobileNet detecta múltiples regiones de interés para el mismo rostro, algunas de las cuales probablemente no corresponden a un rostro. Cada una de estas regiones de interés tendrá un puntaje entre 0 y 1 que nos indicará la probabilidad de que la región pertenezca o no a un rostro: 0 indica una baja probabilidad y 1 total certeza de que la región contiene un rostro.
Así que las regiones de interés y los puntajes correspondientes serán almacenados en las variables boxes y scores respectivamente, y tomaremos las regiones de interés con un umbral mayor o igual a 0.7 (es decir con un 70% de probabilidad de que contengan un rostro). Estas regiones seleccionadas serán almacenadas en la variable bboxes que contendrá las coordenadas dentro de la imagen de la esquina superior izquierda (left, top) y de la esquina inferior derecha (right, bottom) de cada region detectada:
import numpy as np
def detect_faces(image, score_threshold=0.7):
global boxes, scores
(imh, imw) = image.shape[:-1]
img = np.expand_dims(image,axis=0)
# Inicializar mobilenet
sess = tf.compat.v1.Session(graph=mobilenet)
image_tensor = mobilenet.get_tensor_by_name('image_tensor:0')
boxes = mobilenet.get_tensor_by_name('detection_boxes:0')
scores = mobilenet.get_tensor_by_name('detection_scores:0')
# Predicción (detección)
(boxes, scores) = sess.run([boxes, scores], feed_dict={image_tensor:img})
# Reajustar tamaños boxes, scores
boxes = np.squeeze(boxes,axis=0)
scores = np.squeeze(scores,axis=0)
# Depurar bounding boxes
idx = np.where(scores>=score_threshold)[0]
# Crear bounding boxes
bboxes = []
for index in idx:
ymin, xmin, ymax, xmax = boxes[index,:]
(left, right, top, bottom) = (xmin*imw, xmax*imw, ymin*imh, ymax*imh)
left, right, top, bottom = int(left), int(right), int(top), int(bottom)
bboxes.append([left,right,top,bottom])
return bboxes
### Prueba de la etapa de detección de rostros
Veamos qué tan bien lo hace MobileNet. Tomemos la imagen de prueba christian_bale_01.jpgque es una de las más complicadas, pues contiene tres rostros con diferentes poses.
Primero leemos la imagen usando la función creada anteriormente (load_image) y luego aplicamos el bloque de detección de rostros usando la función recien creada (detect_faces). Finalmente dibujamos las regiones detectadas (usando draw_box) y visualizamos el resultado usando la librería Matplotlib:
import matplotlib.pyplot as plt
name = 'christian_bale_01.jpg'
image = load_image(DIR_UNKNOWNS,name)
bboxes = detect_faces(image)
for box in bboxes:
detected_faces = draw_box(image,box,(0,255,0))
fig = plt.figure(figsize=(10,10))
plt.imshow(detected_faces)
El resultado es el esperado: ¡la totalidad de los rostros ha sido detectada correctamente!

Bien, con esto ya estamos listos para implementar el reconocimiento facial.
Reconocimiento facial
Recordemos que el reconocimiento facial se implementa en dos fases:
-
En primer lugar debemos usar una Red Convolucional (que en este caso será FaceNet) para obtener un embedding del rostro. Este embedding es simplemente una representación compacta: en lugar de usar todos los pixeles correspondientes al rostro, FaceNet obtiene un vector de 128 elementos que es prácticamente único para cada sujeto, independientemente de su pose, de sus gestos o incluso (y en la mayoría de los casos) de los accesorios que esté utilizando.
-
En segundo lugar, para realizar el reconocimiento como tal, se compara este embedding calculado por FaceNet con los embeddings de las imágenes de referencia. Esta comparación se realiza simplemente calculando la distancia entre el embedding desconocido y los de referencia: si dicha distancia es menor a cierto umbral el embedding desconocido será similar a los de referencia, y por tanto el sujeto será “verificado”. De lo contrario será etiquetado como “no verificado”.
Veamos en detalle como implementar estos dos pasos.
Cálculo de embeddings usando FaceNet
En primer lugar hagamos la lectura del modelo pre-entrenado (al final del artículo se encuentra el enlace de descarga correspondiente). Para ello haremos uso de la función load_model de Keras:
from tensorflow.keras.models import load_model
facenet = load_model('facenet_keras.h5')
print(facenet.input_shape)
print(facenet.output_shape)
Al imprimir en pantalla las variables input_shape y output_shape del modelo, podemos verificar que el tamaño de la entrada es una imagen RGB de 160x160 pixeles, mientras que a la salida se generará un embedding correspondiente a un vector de 128 elementos:
(None, 160, 160, 3)
(None, 128)
Pero el bloque de detección de rostros no necesariamente nos entregará imágenes del tamaño requerido por FaceNet. Así que antes de usar FaceNet debemos implementar una función que se encargará de: (1) extraer la porción de la imagen que contiene el rostro (detectada por detect_faces) y luego redimensionarla a una imagen de 160x160 para satisfacer los requerimientos de FaceNet. Llamaremos a esta función extract_faces:
def extract_faces(image,bboxes,new_size=(160,160)):
cropped_faces = []
for box in bboxes:
left, right, top, bottom = box
face = image[top:bottom,left:right]
cropped_faces.append(cv2.resize(face,dsize=new_size))
return cropped_faces
Como podemos ver, la función tendrá como entrada la imagen original (image), las regiones de interés detectadas (bboxes) y desde luego el nuevo tamaño de la imagen (new_size=(160,160)). A la salida generará una lista que contendrá únicamente los rostros detectados y con el tamaño requerido por FaceNet.
Verifiquemos qué tan bien lo hace esta función. Tomemos la imagen original usada para la detección de rostros (image) así como las regiones de interés correspondientes a cada rostro detectado (bboxes), y dibujemos por ejemplo la última región de interés:
faces = extract_faces(image,bboxes)
plt.imshow(faces[2])

Podemos ver que funciona correctamente, pues ha extraido el rostro de interés y este además tiene el tamaño deseado (160x160 pixeles).
¡Listo!, con esto ya podemos usar FaceNet para obtener el embedding del rostro. Para ello implementaremos la función compute_embedding que tomará como entradas el modelo FaceNet (model) y el rostro de tamaño 160x160 (face) y entregará a la salida el embedding (vector de 128 elementos) correspondiente a este rostro (embedding):
def compute_embedding(model,face):
face = face.astype('float32')
mean, std = face.mean(), face.std()
face = (face-mean) / std
face = np.expand_dims(face,axis=0)
embedding = model.predict(face)
return embedding
En las líneas de código anteriores podemos ver que ha sido necesario normalizar la imagen, restando a cada pixel el valor promedio y dividiéndolo entre la desviación estándar (face = (face-mean) / std). Este es un procedimiento que usualmente se requiere al momento de usar las Redes Neuronales o Convolucionales, pues esta normalización garantiza la convergencia del algoritmo de entrenamiento.
Además, podemos ver que el cálculo del embedding se obtiene simplemente realizando una predicción con FaceNet, usando precisamente el método predict.
Bien, veamos qué tan bien funcionan la función que acabamos de crear. Tomemos uno de los rostros ya extraídos por la función extract_faces y calculemos su embedding:
embedding = compute_embedding(facenet,faces[0])
print(embedding)
Al imprimir este resultado en pantalla podemos verificar que se trata de un vector de 128 elementos. Para nosotros los humanos no son muy representativos estos valores, pero veremos que al momento de realizar la verificación cada uno de estos valores resultará relevante al momento de decidir si el rostro pertenece o no al sujeto de referencia:
[[-4.26647753e-01 -6.41013622e-01 -2.31208354e-01 -4.84840944e-02
-1.18542290e+00 6.22719169e-01 8.59655559e-01 -1.36113837e-01
-3.05095345e-01 -5.40957093e-01 1.38940156e+00 -1.73634934e+00
1.20331556e-01 -7.43273973e-01 -8.80437255e-01 4.83072340e-01
-1.64128751e-01 -1.42947769e+00 -1.41717303e+00 -2.97024757e-01
6.54603362e-01 1.38104296e+00 4.55870986e-01 8.94368947e-01
-6.26556039e-01 -2.65926182e-01 9.29332733e-01 -1.93000925e+00
6.46763146e-01 1.80726960e-01 -6.88571334e-01 6.32463753e-01
1.22548342e+00 -3.41159165e-01 1.19012344e+00 5.02296269e-01
8.42343986e-01 1.84032238e+00 6.60475314e-01 8.45298529e-01
2.33549759e-01 5.60377181e-01 -2.93602705e-01 -1.22998762e+00
-2.54769862e-01 -2.92127430e-01 1.54830384e+00 5.01721025e-01
-6.65640235e-01 5.69216967e-01 -6.68590248e-01 -3.59147787e-01
5.50906003e-01 -4.02338505e-01 2.43037522e-01 7.39932477e-01
-6.98154986e-01 4.04463679e-01 6.82466507e-01 -7.65415490e-01
1.40775651e-01 -3.38924348e-01 -1.76146734e+00 -9.21169460e-01
-4.35902804e-01 8.70810688e-01 2.05776393e-01 2.15476251e+00
-1.24707913e+00 -1.33041155e+00 -1.02686596e+00 -1.48285329e-02
6.12026572e-01 -8.53855789e-01 -7.95695186e-02 8.68223548e-01
-8.90613437e-01 6.68394446e-01 -8.97859037e-01 -9.03339446e-01
-7.47245431e-01 -8.04160118e-01 -2.36600542e+00 9.65993524e-01
1.23790503e+00 8.28291357e-01 1.22251332e+00 4.05592144e-01
4.08705473e-01 -6.36915922e-01 8.58528972e-01 2.04116154e+00
2.09857702e+00 -2.72989035e-01 3.67820263e-04 2.11588883e+00
1.18281484e-01 -9.36303958e-02 -6.93383396e-01 -1.10270917e+00
6.35311529e-02 -1.33765423e+00 -1.22276559e-01 -1.48749614e+00
4.92041230e-01 -1.36694705e+00 8.22300196e-01 2.70185530e-01
1.35119343e+00 5.65619409e-01 7.91297376e-01 -1.74741006e+00
1.46956277e+00 3.14830750e-01 -2.50152731e+00 8.99935365e-02
-1.31997585e+00 2.05640927e-01 -2.16436833e-01 1.76476681e+00
-1.82925713e+00 -3.79676580e-01 -4.68316495e-01 1.39297128e-01
9.58558321e-01 1.54516292e+00 1.24202631e-01 -4.80782241e-01]]
Bien, veamos ahora cómo implementar la última fase el reconocimiento facial: la comparación.
Reconocimiento facial: comparando los embeddings
En primer lugar debemos calcular los embeddings de referencia, es decir que tomaremos los rostros de referencia (que se encuentran en el directorio DIR_KNOWNS) y para cada uno de ellos calcularemos el embedding usando la función que acabamos de crear. Como tenemos cuatro rostros de referencia almacenaremos en una lista (known_embeddings) los cuatro embeddings obtenidos:
known_embeddings = []
print('Procesando rostros conocidos...')
for name in os.listdir(DIR_KNOWNS):
if name.endswith('.jpg'):
print(f' {name}')
image = load_image(DIR_KNOWNS,name)
bboxes = detect_faces(image)
face = extract_faces(image,bboxes)
known_embeddings.append(compute_embedding(facenet,face[0]))
Podemos ver que hemos ejecutado cada uno de los bloques implementados anteriormente: (1) lectura de la imagen (load_image), (2) detección de rostros (detect_faces), (3) extracción de regiones de interés (extract_faces) y cálculo de embeddings (compute_embedding).
Ahora crearemos la función encargada de realizar la verificación del rostro. Recordemos que esta verificación consiste simplemente en comparar el embedding del rostro desconocido con cada uno de los cuatro embeddings de referencia. Esta comparación será simplemente la distancia entre vectores.
Como en total se calcularán cuatro distancias (pues tenemos cuatro rostros de referencia), a cada una de ellas aplicaremos un umbral (igual a 11). A la salida de la función se retornará tanto el arreglo con cada una de las cuatro distancias calculadas, así como una lista indicando cuáles de ellas son menores o iguales al umbral:
def compare_faces(embs_ref, emb_desc, umbral=11):
distancias = []
for emb_ref in embs_ref:
distancias.append(np.linalg.norm(emb_ref-emb_desc))
distancias = np.array(distancias)
return distancias, list(distancias<=umbral)
Perfecto. Lo único que resta ahora es aplicar esta función a cada una de las imágenes de prueba. Para determinar si la imagen de prueba contiene o no el rostro de referencia será suficiente con que al menos una de las cuatro distancias calculadas (realizadas por compare_faces) sea inferior al umbral establecido anteriormente:
print('Procesando imágenes desconocidas...')
for name in os.listdir(DIR_UNKNOWNS):
if name.endswith('.jpg'):
print(f' {name}')
image = load_image(DIR_UNKNOWNS,name)
bboxes = detect_faces(image)
faces = extract_faces(image,bboxes)
# Por cada rostro calcular embedding
img_with_boxes = image.copy()
for face, box in zip(faces,bboxes):
emb = compute_embedding(facenet,face)
_, reconocimiento = compare_faces(known_embeddings,emb)
if any(reconocimiento):
print(' match!')
img_with_boxes = draw_box(img_with_boxes,box,(0,255,0))
else:
img_with_boxes = draw_box(img_with_boxes,box,(255,0,0))
cv2.imwrite(f'{DIR_RESULTS}/{name}',cv2.cvtColor(img_with_boxes,cv2.COLOR_RGB2BGR))
print('¡Fin!')
En el código anterior vemos que se procesarán una a una las imágenes con rostros desconocidos (almacenadas en el directorio DIR_UNKNOWNS) y se aplicará la misma secuencia de procesamiento definida anteriormente (lectura de la imagen, detección y extracción de rostros, cálculo de embedding).
Luego, para cada rostro detectado (for face, box in zip(faces,bboxes):) se realizará la comparación (_, reconocimiento = compare_faces(known_embeddings,emb)). Y por último, si cualquiera de las cuatro distancias es inferior al umbral (if any(reconocimiento):), entonces se dibujará la región de interés en color verde (draw_box(img_with_boxes,box,(0,255,0))), de lo contrario (else) se dibujará en color rojo.
Finalmente las imágenes resultantes serán almacenadas en el directorio correspondiente (DIR_RESULTS).
Al ejecutar el código anterior podemos verificar que ¡nuestro sistema de reconocimiento facial funciona a la perfección!:
Procesando imágenes desconocidas...
christian_bale_01.jpg
christian_bale_03.jpg
christian_bale_02.jpg
miguel_08.jpg
match!
miguel_09.jpg
match!
jerry_seinfeld_03.jpg
miguel_07.jpg
match!
miguel_06.jpg
match!
jerry_seinfeld_02.jpg
jack_nicholson_01.jpg
jack_nicholson_03.jpg
miguel_10.jpg
match!
miguel_05.jpg
match!
jerry_seinfeld_01.jpg
jack_nicholson_02.jpg
¡Fin!
Esto quiere decir que sólo en las imágenes que contienen mi rostro (miguel_05.jpg a miguel_10.jpg) se ha impreso la palabra match!. Para verificar esto podemos incluso ver el resultado en algunas imágenes de prueba:
Conclusión
Bien, en este post vimos un tutorial paso a paso de cómo implementar un sistema de reconocimiento facial en Python. Para ello usamos dos de las arquitecturas más usadas en la actualidad: MobileNet, que permite realizar la detección de rostros, y FaceNet, encargada de la obtención de los embeddings de cada rostro, para posteriormente realizar su verificación usando un simple algoritmo de programación.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Código fuente
En este enlace de Github podrás descargar el código fuente de este tutorial.