Underfitting y Overfitting en las Redes Neuronales
En este post veremos dos conceptos muy importantes del Machine Learning: el Underfitting y el Overfitting, y cómo afectan el entrenamiento de las Redes Neuronales.
Al final de este artículo habrás aprendido:
- Qué son los sets de entrenamiento y validación en un modelo de Machine Learning
- En qué consisten los conceptos de Underfitting y overfitting, y su importancia en el desarrollo de modelos de Machine Learning.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
La representación de los datos en las Redes Neuronales
Las Redes Neuronales resuelven un problema de representación. Esto quiere decir que permiten tomar unos datos de entrada y representarlos de forma adecuada para generar los datos de salida.
Un ejemplo sería un modelo de clasificación. En este caso la representación consiste en tomar los datos de entrada y entrenar la Red Neuronal para extraer patrones característicos que permitan clasificarlos a la salida.
Otro ejemplo podría ser una Red Neuronal Recurrente. Así, en un sistema de conversión voz a texto, la representación consiste en determinar los patrones característicos de la voz para posteriormente representarlos como secuencias de texto.
En todo caso, sin importar el modelo que estemos implementando, es necesario llevar a cabo dos pasos esenciales durante su desarrollo: el entrenamiento y la validación.
El entrenamiento y la validación
Teniendo en cuenta lo anterior, podemos decir que el entrenamiento consiste en presentar a la red una gran cantidad de ejemplos de manera tal que esta pueda “aprender” las características más relevantes del set de datos de entrada. Este aprendizaje consiste en determinar una serie de coeficientes que permiten encontrar la mejor representación posible que relacione los datos de entrada con los de salida.
Por otra parte, la validación consiste en poner a prueba el modelo entrenado. En este caso debemos verificar qué también funciona dicho modelo con datos que no ha visto previamente. En este caso no se modifica ningún coeficiente del modelo, y únicamente se evalúa su desempeño (usando métricas como el error o la precisión).
Pues bien, para lograr llevar a cabo estos dos procedimientos se usan dos set de datos diferentes. El set de entrenamiento generalmente contiene aproximadamente entre el 70% y el 80% de los datos disponibles, mientras que el set de validación usa el 20-30% restante.
Un ejemplo del uso de estos sets se puede ver en el tutorial para la clasificación de los datos MNIST que analizamos en un artículo anterior.
Veamos a continuación tres tipos de modelo y sus posibles ventajas y desventajas en términos del error que generan al usar los sets de entrenamiento y validación.
Tres posibles modelos de clasificación
Caso 1: un modelo demasiado general
Supongamos que estamos desarrollando un clasificador y que el set de entrenamiento es como el mostrado en la figura:

Asumamos dos categorías para la clasificación: “frutas” y “no frutas”. Teniendo en cuenta estas dos categorías, la clasificación inicial obtenida sobre el set de entrenamiento sería la siguiente:

Hasta acá parece que todo funciona bien. La totalidad de las manzanas fueron efectivamente clasificadas como “frutas”. ¿Qué sucederá cuando pongamos a prueba el modelo usando el set de validación?
Supongamos que dentro del set de validación se encuentra una piña. ¿Cómo será clasificada? En realidad este dato será clasificado en la categoría “no frutas”, pues el modelo determinará que la piña no se asemeja a las manzanas de la categoría “frutas”:

Así, en este caso el modelo habrá cometido un error en la clasificación con este set de validación.
Esto se debe a que el modelo diseñado es demasiado simple, hemos simplificado el problema a tan sólo dos categorías (“frutas” y “no frutas”).
Así, podemos resumir este comportamiento usando el término underfitting. En este caso sucede que el modelo no es capaz de encontrar una representación adecuada de los datos durante la clasificación.
Veamos un segundo modelo, que busca resolver este inconveniente.
Caso 2: un modelo demasiado específico
Si revisamos nuevamente el set de datos de entrenamiento podríamos redefinir las categorías. Una de ellas sería “manzanas verdes” y la otra podría ser “cualquier cosa excepto manzanas verdes”.
Al usar estas categorías obtenemos el siguiente resultado con el set de entrenamiento:

Al parecer es una clasificación perfecta. Sin embargo, ¿qué ocurriría si en el set de validación hay una manzana roja? ¿Cómo sería clasificada por el modelo?
En realidad esperaríamos que fuese clasificada del lado derecho, pues en últimas se trata de una manzana. Sin embargo, por tratarse de un modelo tan específico, tendremos un error y el dato será clasificado en la otra categoría:

Así, en este caso hemos ido al extremo opuesto del Underfitting. Hemos pasado de un modelo muy general a uno demasiado específico.
De nuevo, el modelo entrenado no captura la esencia de las características que permiten obtener una clasificación adecuada.
Podemos entonces decir que el modelo está realizando overfitting. Bajo estas condiciones, el modelo memoriza los datos de entrenamiento (manzanas verdes), perdiendo la capacidad de clasificar datos que no cumplan exactamente con estas características.
¿Y entonces cuál es el modelo ideal?
Siguiendo la lógica anterior, podemos decir que el modelo ideal será aquel que esté en un punto medio. Es decir, que será un modelo capaz de generalizar adecuadamente, y que no exhiba los problemas de underfitting y overfitting descritos anteriorrmente.
Veamos un ejemplo de este modelo.
Caso 3: un modelo ideal
¿Qué pasa si ahora las categorías son “no manzanas” y “manzanas” como se muestra en la figura?

Entonces veremos que tanto la piña como la manzana roja (usadas en los sets de validación anteriores) serán clasificadas correctamente:

Podemos comprobar que este modelo tiene un comportamiento perfecto: clasifica correctamente tanto los datos de entrenamiento como los de validación.
En este caso decimos que el modelo es capaz de generalizar adecuadamente. Esto hace referencia a que es logra capturar la esencia de los datos de entrenamiento y de replicar estos resultados en datos nunca vistos (los de validación).
Con estos tres ejemplos introductorios, ya podemos definir de forma más rigurosa los conceptos de underfitting y overfitting.
Definición de underfitting y overfitting
Consideremos un problema de clasificación en dos categorías: círculos rojos y azules. En la figura de abajo se observan los correspondientes sets de entrenamiento (círculos rellenos) y de validación (círculos vacíos):
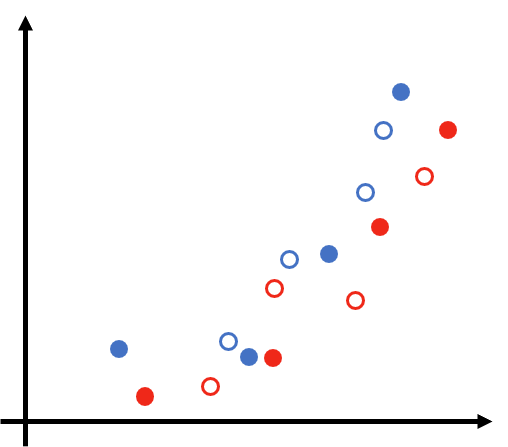
Ahora, consideremos tres modelos con las siguientes fronteras de decisión obtenidas con el set de entrenamiento:
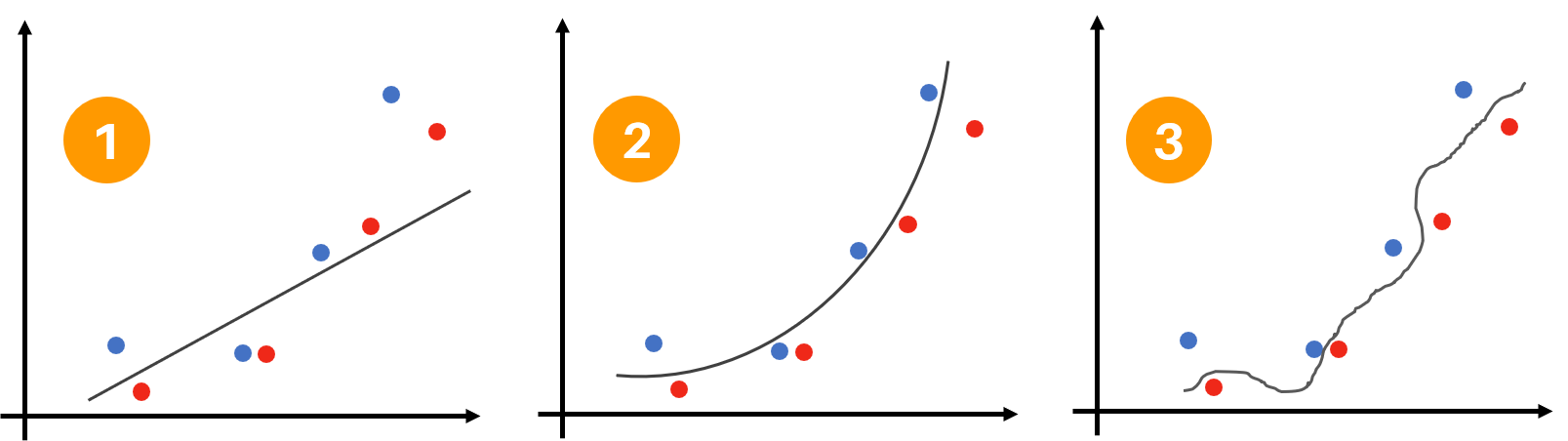
¿Cuál de estos modelos tiene un mejor desempeño frente a los datos de validación?
Para responder a la pregunta debemos verificar el resultado de la clasificación obtenido en cada caso. Así, en la figura de abajo podemos ver la cantidad de errores generados por cada uno de los modelos al usar los sets de entrenamiento y validación:
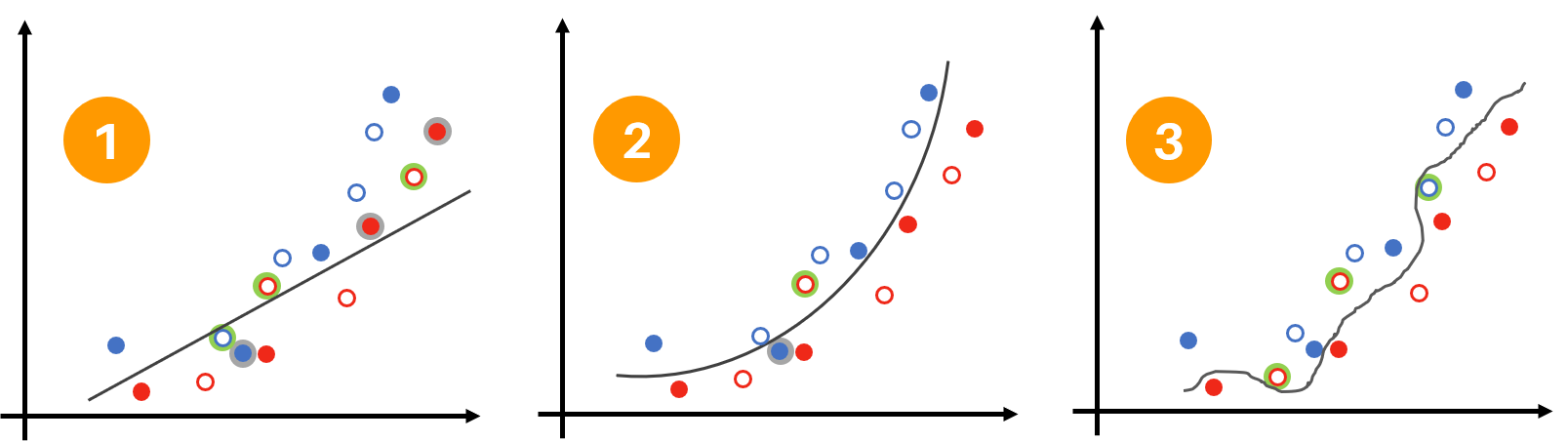
En primer lugar, podemos observar que el primer modelo es demasiado general y en ambos sets el error obtenido es relativamente alto. En total se han obtenido 3 errores en el entrenamiento y 3 en la validación. Este es un ejemplo de un modelo con underfitting.
Por otra parte, en el caso 3 vemos el extremo opuesto: un modelo que memoriza los datos de entrenamiento (0 errores) pero que no tiene un buen desempeño con los datos de validación (3 errores). En este caso el modelo está realizando overfitting.
Finalmente, podemos ver que el modelo de la mitad tiene un desempeño adecuado: el error en la clasificación es bajo tanto para el set de entrenamiento como para el de validación. En total se obtuvo 1 error en el entrenamiento y 1 en la validación. Éste es precisamente el comportamiento ideal.
El desempeño de estos tres modelos se puede resumir en la figura de abajo, en donde se comparan los errores en los sets de entrenamiento y validación para cada caso:
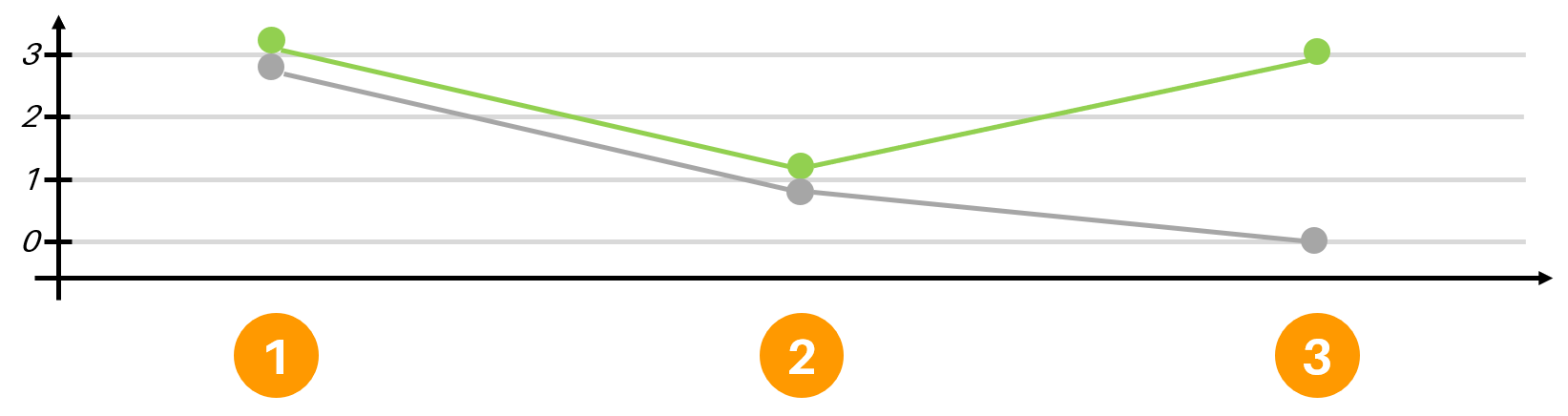
Así, podemos decir que el modelo ideal es aquel que representa el mejor compromiso entre el underfitting y el overfitting, siendo el error en la clasificación la métrica de referencia para determinar este comportamiento.
Conclusión
Los ejemplos vistos anteriormente nos han permitido tener una idea precisa de los conceptos de underfitting y overfitting. Estos son los aspectos más importantes a tener en cuenta:
- El proceso de diseño de un modelo de Machine Learning implica el uso de dos sets de datos: entrenamiento y validación.
- Generalmente el set de entrenamiento usa aproximadamente el 80% de los datos disponibles, mientras que el de validación usa el 20% restante.
- Un modelo con underfitting es aquel en donde los errores tanto de entrenamiento como de validación son similares y relativamente altos.
- Por otra parte, en un modelo con overfitting se obtiene un error de entrenamiento relativamente bajo y uno de validación relativamente alto.
- Al desarrollar un modelo de Machine Learning se debe evitar cualquiera de los dos extremos anteriores (underfitting u overfitting).
- Lo anterior implica que el modelo ideal será aquel que permita obtener un error bajo en ambos sets (entrenamiento y validación).
En los próximos artículos veremos cuáles son las estrategias para combatir el overfitting y el underfitting en las Redes Neuronales.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: