¿Por qué Git es esencial en el Machine Learning?
En este post veremos qué es y por qué Git resulta esencial en el Machine Learning, y hablaremos de los principales comandos de Git que considero tod@ aprendiz o Ingenier@ de Machine Learning debería conocer.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
Si queremos dar el salto del Machine Learning “académico” a un empleo en Machine Learning, desarrollando modelos que luego se conviertan en productos, necesitamos contar con varias habilidades en nuestra caja de herramientas, y Git es precisamente una de ellas.
Pero antes de comenzar a hablar de Git es importante que entendamos qué es esto del Machine Learning “académico” y la Ingeniería de Machine Learning.
¿Cómo dar el salto del Machine Learning Académico a la Ingeniería de Machine Learning?
Esencialmente el Machine Learning académico es el proceso de aprender los algoritmos y arquitecturas básicas del Machine Learning, así como algunas librerías de programación, que nos permitan desarrollar modelos para resolver un problema en particular:

Pero usualmente esta fase de aprendizaje, aunque es importante, es sólo una pequeña parte de lo que es todo el panorama del Machine Learning como una disciplina que puede brindar soluciones a empresas o usuarios finales:
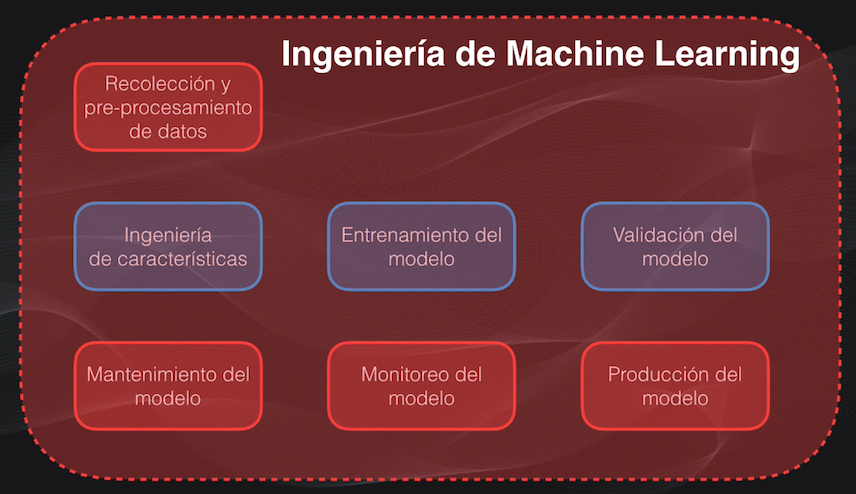
Si queremos conseguir un empleo en Machine Learning, necesitamos pasar de modelos desarrollados en Python a implementaciones reales y utilizables de estos modelos.
Es decir que debemos ser capaces de desarrollar sistemas de Machine Learning, lo que implica que además debemos saber llevar el modelo a producción, es decir tomar el modelo entrenado y ponerlo a disposición de la empresa en una plataforma adecuada para la toma de decisiones o para su acceso por parte del usuario final.
Y esto se conoce precisamente como la Ingeniería de Machine Learning, que en últimas busca que los algoritmos de Machine Learning puedan ser implementados de manera efectiva como parte de un sistema de producción.
Y para poder dar este salto del Machine Learning “académico” a la Ingeniería de Machine Learning se requieren muchas habilidades, entre las que se incluyen algunas de tipo técnico que a veces toman cosas prestadas de otras disciplinas como la Ingeniería de Software.

En próximos artículos hablaremos en detalle de lo que es y lo que se requiere para ser Ingenier@s de Machine Learning, pero de momento nos vamos a enfocar en una herramienta esencial que nos permitirá llenar parte de ese vacío que existe entre el Machine Learning Académico y la Ingeniería de Machine Learning: el control de versiones.
¿Qué es el control de versiones?
Empecemos entonces con un ejemplo práctico que nos permitirá entender porqué es necesario que el futuro Ingeniero de Machine Learning sepa manejar una herramienta para el control de versiones.
Supongamos primero el caso más sencillo: estamos hasta ahora aprendiendo Machine Learning por nuestra cuenta y vamos a escribir el código para resolver un problema en particular.
Tenemos listo el código para leer el set de datos, para hacer el pre-procesamiento, ya escogimos nuestro primer modelo, lo implementamos y lo entrenamos. Y todo esto lo almacenamos en un archivo de Python:

Pero luego comenzamos a refinar este modelo, le comenzamos a agregar más capas ocultas o más neuronas a cada capa, re-entrenamos y miramos su desempeño. Y esto lo repetimos una y otra vez.
Para evitar conflictos con el archivo original comenzamos a crear varios archivos Python, cada uno con un nombre diferente, para poder de esta manera hacer un seguimiento a las diferentes versiones e identificar cuál de ellas es la que en últimas vamos a escoger:
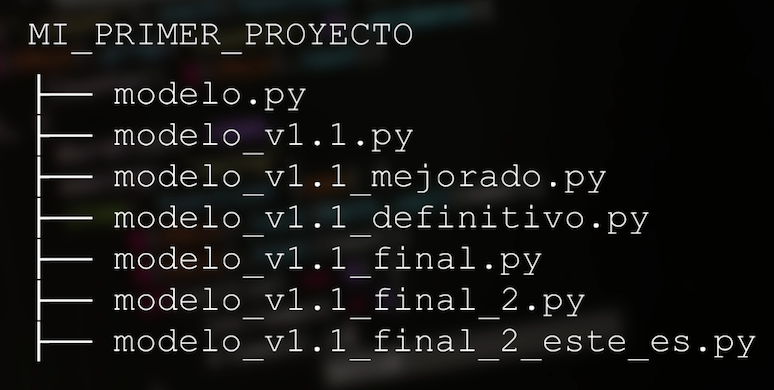
Creo que a todos nos ha sucedido esto, y comenzamos a ver que esta forma de hacer el control y seguimiento a estas versiones no es la más adecuada, pues si el modelo se hace más complejo o si comenzamos a modificar otras partes del código al final resultará muy difícil saber cuáles fueron los cambios que realizamos y cuál es la versión que en últimas nos interesa mantener.
Bien, ahora veamos un segundo caso. Supongamos que conseguimos un empleo en Machine Learning y que en la empresa tenemos que comenzar a interactuar con otros miembros del equipo: está un ingeniero de software que se encarga de implementar módulos que permiten por ejemplo recolectar los datos, está un analista de datos que por ejemplo realiza el pre-procesamiento, estoy yo como Ingeniero de Machine Learning, está un desarrollador web que se encarga de llevar el modelo a un servidor y a una página web para que los clientes interactúen con dicho modelo.
Y todo este equipo debe desarrollar un proyecto que implica la implementación de código para cada una de estas áreas:
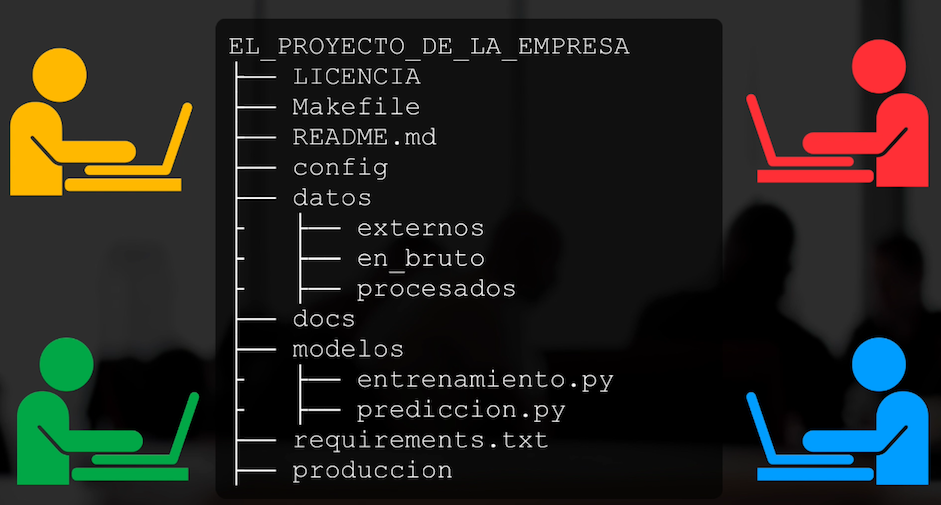
En este caso es evidente que el sistema convencional de generar varias copias de un archivo con diferentes nombres no resulta para nada adecuado. En primer lugar porque el código fuente no estará en un sólo archivo sino que todo estará probablemente integrado en un directorio con múltiples archivos, así que será aún más difícil seguir los cambios que cada miembro hace al código fuente.
Y en segundo lugar porque si alguien modifica uno o varios archivos debe haber una manera eficiente de informar a los demás sobre estos cambios, y todo esto se debe llevar a cabo de forma armónica, sin el riesgo de que se pueda perder el trabajo realizado a medida que avanzamos en el desarrollo del proyecto.
Así que en resumen, bien sea para el caso personal o del trabajo en equipo, se necesita contar con un sistema de control de versiones, que facilite el desarrollo del código y que se encargue de mantener un registro eficiente de los cambios y las diferentes versiones que tengamos para los archivos que hacen parte del proyecto.
Git: el sistema de control de versiones recomendado
Y aquí es donde entra Git, el sistema de control de versiones más usado en la actualidad y que fue creado en el año 2005 por Linus Torvalds, el mismo creador de Linux.
Esencialmente “Git es un sistema gratuito y de código abierto para el control de versiones de manera distribuida” (sitio web oficial de Git).
Esto quiere decir que permite realizar el control de versiones, que es el problema que veníamos viendo en los ejemplos anteriores. Así que en esencia es un programa que nos permite de forma muy sencilla hacer el rastreo de los cambios en los archivos del proyecto.
Y es distribuido en el sentido de que está pensado para el trabajo en equipo, lo que permite coordinar el desarrollo entre diferentes programadores para que de forma colaborativa se pueda elaborar el código fuente del proyecto sin riesgo de pérdida de información.
Y en este punto es importante que desde ya hagamos una diferenciación importante: ¡Git no es lo mismo que GitHub!
Git como tal es el sistema de control de versiones, mientras que GitHub (y otras alternativas como Bitbucket o GitLab) son proveedores de servicios en la nube, que usan como base a Git para el control de versiones y en donde podemos almacenar nuestros archivos.
¿Cómo usar Git en Machine Learning?
Bien, con esto ya tenemos una idea general de qué es Git. Ahora sí presten mucha atención, porque en esta parte les voy a explicar los comandos esenciales de Git para poder comenzar a usarlo fácilmente en nuestros proyectos de Machine Learning.
Git está dividido en tres áreas: el directorio de trabajo, el área de preparación y el repositorio (que tendrá una parte local y una parte remota):

Los comandos básicos de Git
Para entender cómo funciona veamos un ejemplo. Supongamos que estamos desarrollando un proyecto de Machine Learning y que el código lo separamos en diferentes archivos que almacenamos en un directorio local (es decir en nuestro computador). Vamos a llamar a este el directorio de trabajo:
directorio_de_trabajo
├── datos.py
├── modelo.py
├── entrenamiento.py
├── validacion.py
├── ideas.txt
Para comenzar a usar Git debemos movernos a este directorio e inicializarlo, es decir, debemos decirle a Git que queremos comenzar a hacer el rastreo de los cambios que haya en el directorio. Para eso usamos git init, que crea un directorio oculto (.git) que contiene toda la información necesaria para comenzar a hacer este seguimiento:
$ cd directorio_de_trabajo
$ git init
Initialized empty Git repository in ~/directorio_de_trabajo
El siguiente paso es mover estos archivos al área de preparación. Supongamos que uno de los archivos del directorio de trabajo es un simple archivo de texto con ideas que hemos venido anotando para el desarrollo del proyecto, pero que es un archivo temporal y no nos interesa hacerle seguimiento.
Entonces, usando git status podemos ver cuáles archivo estamos siguiendo o no, y con git add podemos decidir cuáles de ellos se quedarán en nuestro directorio local y cuáles vamos a preparar (de ahí el nombre de área de preparación) para enviar posteriormente al repositorio:
$ git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
datos.py
entrenamiento.py
ideas.txt
modelo.py
validacion.py
nothing added to commit but untracked files present (use "git add" to track)
$ git add datos.py modelo.py entrenamiento.py validacion.py
Ahora debemos mover los archivos del área de preparación al repositorio. Para esto debemos agregar un comentario que permita fácilmente identificar los cambios que hemos hecho en nuestros archivos. Esto facilitará el seguimiento del proyecto y, si otra persona accede a nuestro código, podrá fácilmente entender cuáles han sido esas modificaciones.
Para hacer esto usamos git commit, con lo que ya habremos movido los archivos a un repositorio local. En este caso Git modificará la carpeta oculta que creó al inicio (.git) almacenando los cambios en los archivos del proyecto junto con los comentarios correspondientes:
$ git commit -m "Initial commit"
[master (root-commit) 68d14c7] Initial commit
4 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 datos.py
create mode 100644 entrenamiento.py
create mode 100644 modelo.py
create mode 100644 validacion.py
El último paso es mover el contenido de nuestro repositorio local a un repositorio remoto, no sólo para que, si nos interesa, otras personas puedan apoyar el desarrollo del proyecto sino para tener un backup del mismo.
Para esto podemos usar, por ejemplo GitHub. Allí creamos un repositorio con el nombre que queramos:
Luego regresamos a nuestro repositorio local y le indicamos a Git el nombre del repositorio remoto recién creado, y luego enviamos nuestro repositorio local al remoto usando el comando git push. Y listo, ya están sincronizados nuestro repositorio local y el remoto:
$ git remote add origin https://github.com/codificandobits/mi_proyecto.git
$ git branch -M main
$ git push -u origin main
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 249 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/codificandobits/mi_proyecto.git
* [new branch] main -> main
Branch main set up to track remote branch main from origin.
Así que en resumen el flujo de trabajo que les sugiero es:
- Realizar modificaciones en el directorio de trabajo local
- Mover los archivos modificados al área de preparación, usando
git add - Mover los archivos al repositorio local, usando
git commit - Y finalmente enviar los cambios al repositorio remoto, usando
git push
Otros comandos útiles en Git
También podemos usar comandos avanzados de Git para por ejemplo crear ramas: esto resulta útil cuando queremos experimentar por ejemplo con un nuevo modelo para el problema que estamos resolviendo.
Para no modificar el desarrollo inicial se crea una rama, que es como un puntero a la versión experimental del repositorio, realizamos todas las pruebas necesarias, si este código funciona y queremos que el nuevo modelo reemplace al anterior, simplemente movemos este puntero a la rama principal:
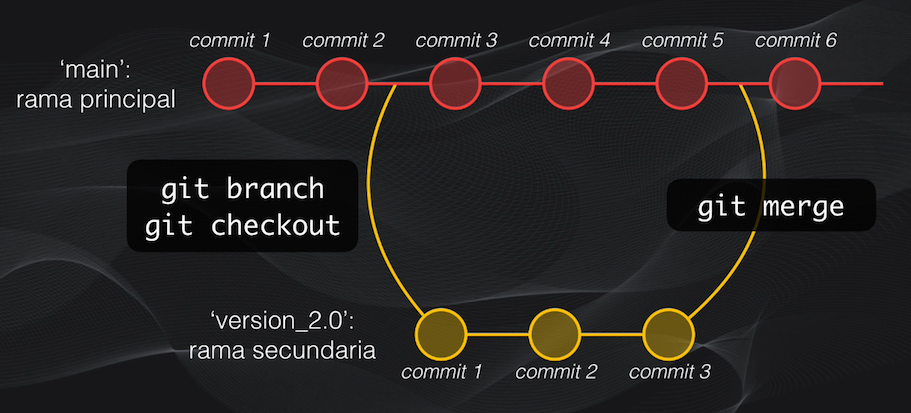
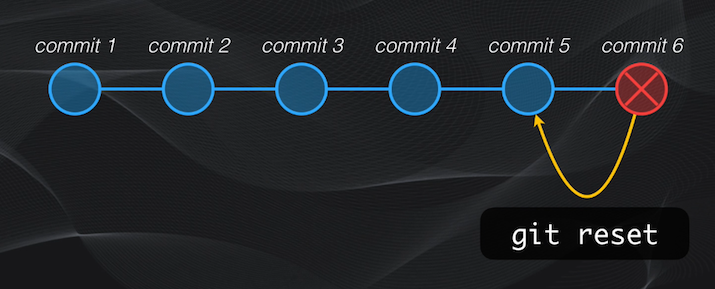
También está la posibilidad de deshacer los cambios, y esto es muy común cuando por ejemplo eliminamos por error algunas líneas de código, o el modelo experimental no funciona, fácilmente con Git podemos regresar a un punto determinado de desarrollo dentro del proyecto:
Conclusión
Aunque hay más comandos avanzados de Git, el flujo de trabajo que vimos hace un momento les permitirá facilmente poder comenzar a incorporar Git en sus proyectos de Machine Learning sin tantos traumas.
En resumen Git resulta muy útil para gestionar y mantener un historial de nuestros proyectos individuales o colaborativos de Machine Learning, y es sin duda alguna una habilidad necesaria en nuestra caja de herramientas, especialmente si queremos no sólo implementar proyectos de tipo académico sino igualmente en un momento dado conseguir un empleo en Machine Learning.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: