Los Bosques Aleatorios: Clasificación y Regresión
En este artículo hablaremos en detalle de los Bosques Aleatorios, uno de los algoritmos más importantes y más usados en el Machine Learning. Veremos cómo entrenarlos y validarlos y cómo realizar la predicción, cómo elegir los parámetros para su entrenamiento y de las cosas en común y las ventajas que tienen frente a los árboles de decisión.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
En artículos anteriores hablamos de cómo usar los Árboles de Regresión y los Árboles de Clasificación.
El entrenamiento de estos árboles se hace generando de forma recurrente particiones sobre el espacio de características, para obtener agrupaciones de datos cada vez más uniformes.
Y esta uniformidad se mide con el índice Gini en el caso de la Clasificación y con el error cuadrático medio en el caso de la Regresión.
Y para clasificar un dato nuevo o para realizar la regresión, simplemente verificamos las condiciones para ese dato en cada nodo del árbol hasta que sea asignado a una hoja en particular.
Pues a pesar de que los árboles de decisión son arquitecturas muy poderosas, tienen una gran desventaja: el overfitting. Esto quiere decir que en general funcionan muy bien durante el entrenamiento, pero no tanto cuando introducimos datos nuevos (es decir cuando queremos hacer predicciones).
Y es esta limitación la que precisamente dio origen a los Bosques Aleatorios (o Random Forests), uno de los algoritmos más poderosos y más usados del Machine Learning. En este artículo hablaremos en detalle de estos Bosques Aleatorios, de cómo entrenarlos y validarlos y cómo realizar la predicción, de cómo elegir los parámetros para su entrenamiento y de las cosas en común y las ventajas que tienen frente a los Árboles de Decisión.
Para entender todos los detalles te recomiendo ver los dos árticulos anteriores, en donde explico cómo es que funcionan los Árboles de Clasificación y los Árboles de Regresión.
¿Y por qué no usamos Árboles de Decisión?
Bien, hablemos primero del gran problema de los árboles de decisión: el compromiso entre el bias (o sesgo) y la varianza.
Los Árboles de Decisión se caracterizan por ser capaces de ajustarse bastante bien a los datos de entrenamiento, es decir que tienen lo que se conoce como bias bajo. Pero desafortunadamente el error al momento de realizar la predicción (lo que se conoce como varianza) es generalmente alto.
Y esto se debe a que son muy sensibles a los datos de entrenamiento: un ligero cambio en tan sólo algunos de ellos puede dar origen a un árbol totalmente diferente, lo que dificulta aún más hacer predicciones con datos nuevos:
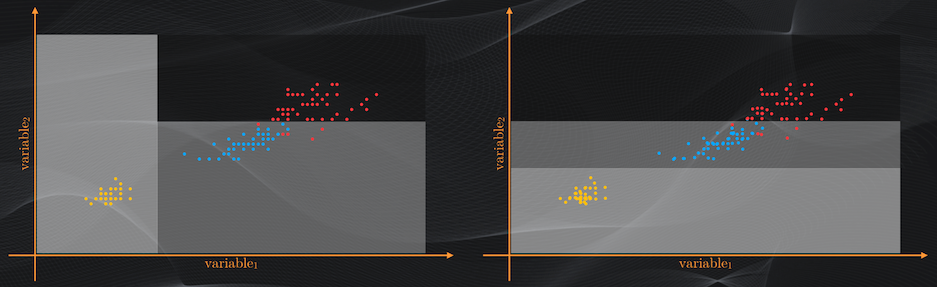
Y cuando tenemos un bias bajo y una varianza alta estamos precisamente ante un problema de overfitting.
El principio básico de los Bosques Aleatorios
Pues los bosques aleatorios permiten resolver este problema, preservando lo positivo de los Árboles de Decisión (es decir un bias bajo) pero a su vez logrando reducir su varianza.
¿Y cómo se logra esto? Pues introduciendo dos variantes a estos árboles de decisión:
La primera es que en lugar de entrenar un único árbol se entrenan varios, usualmente decenas o cientos… De ahí precisamente el término “bosques”:
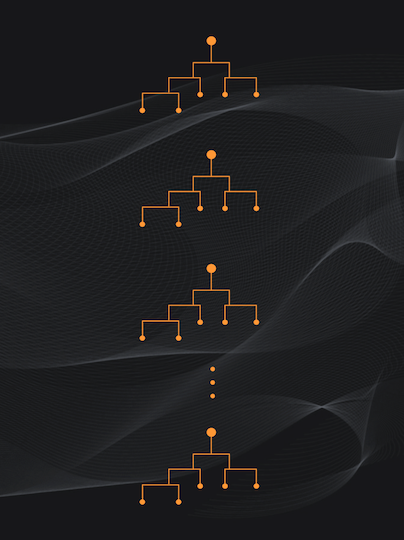
Pero esto no es suficiente, por que si entrenamos cada árbol del Bosque con el mismo set de datos seguiríamos teniendo el mismo problema de la varianza alta.
Así que la segunda parte de la solución es entrenar cada árbol del bosque con una parte distinta del set de datos original. Y acá es donde viene una característica importantísima: este subset de entrenamiento se selecciona aleatoriamente. De ahí precisamente el nombre “Bosques Aleatorios”:
Con el bosque aleatorio ya entrenado, se puede hacer la predicción para un dato nuevo, y para esto debemos agregar los resultados individuales de los árboles. Es decir que si vamos a clasificar, la categoría asignada al dato será simplemente la categoría votada por la mayoría de los árboles, mientras que si la tarea es de regresión el valor asignado al dato será simplemente el promedio de las predicciones hechas por cada árbol:
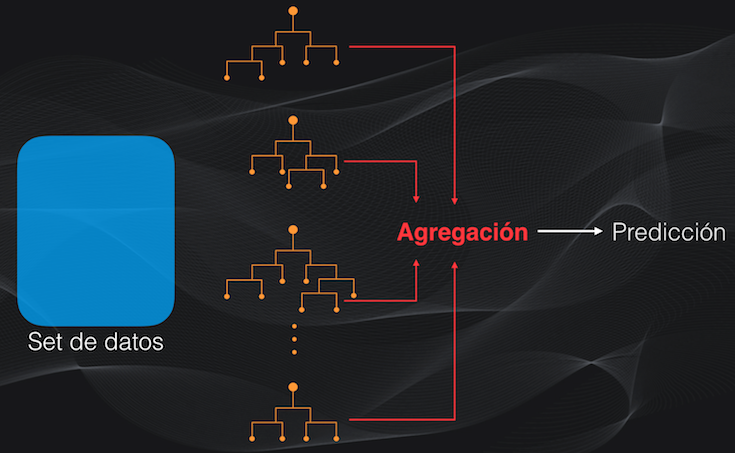
Con la aleatoriedad cada árbol será entrenado con un subset diferente, y por tanto, si el set de entrenamiento tiene ruido este afectará probablemente sólo a unos cuantos árboles, pero no a la totalidad del bosque. Además, al agregar los resultados para generar la predicción, los árboles que no funcionan tan bien no tendrán un impacto significativo en el resultado final.
Así que al combinar estos dos elementos (la aleatoriedad y la agregación) se logra reducir la varianza de los árboles individuales.
Entonces un bosque aleatorio es como el equipo de jueces que evalúa a los clavadistas en los juegos olímpicos. Habrá jueces poco exigentes o demasiado estrictos (es decir que generarán una alta varianza) que asignarán puntajes o muy altos o muy bajos a los participantes. Pero al tener 7 u 8 jueces y obtener la puntuación de forma conjunta (es decir agregando los resultados) evitamos tener puntajes excesivamente altos o demasiado bajos.
¿Cómo entrenamos un Bosque Aleatorio?
Bien, ya tenemos una idea general de cómo funcionan estos bosques aleatorios. Ahora sí veamos cómo realizar el entrenamiento. Para esto supongamos que entrenaremos un bosque para clasificar datos, aunque si la tarea es de regresión el procedimiento será equivalente.
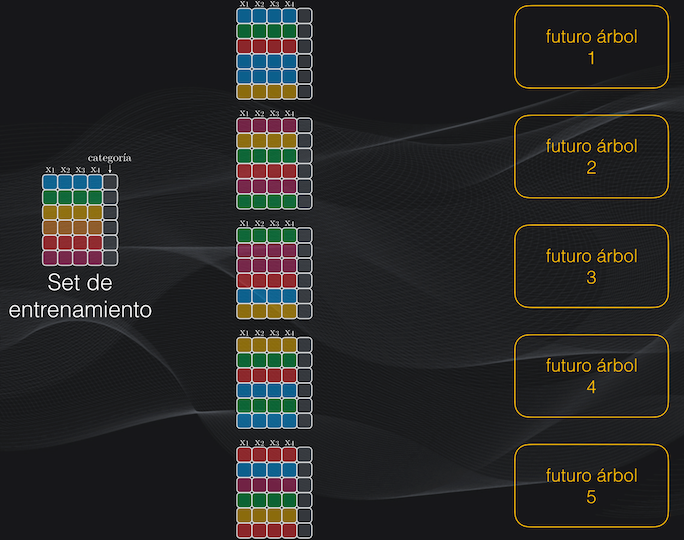
Partamos de un set de datos con 6 ejemplos de entrenamiento (es decir 6 filas), cada una con 4 características (es decir 4 columnas):

El Bootstrapping
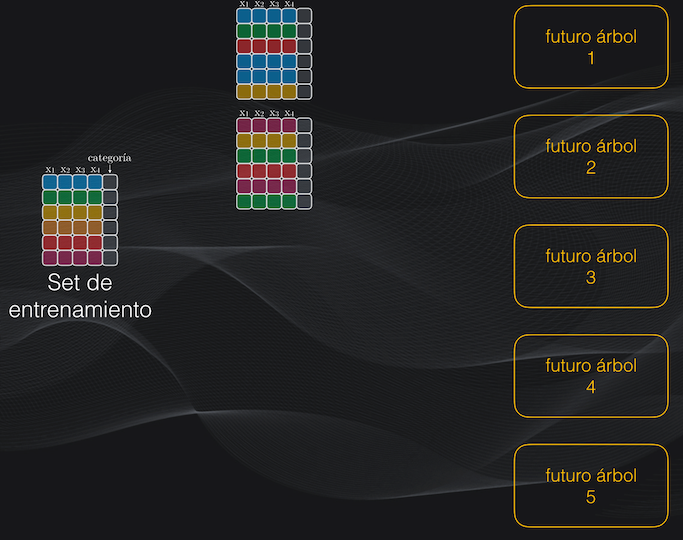
El primer paso es definir el número de árboles que tendrá el Bosque. Para facilitar la explicación supongamos que este número es 5, aunque en realidad se usan decenas o cientos de árboles, pero de esto hablaremos más adelante:

El segundo paso es crear el subset de entrenamiento de cada árbol, introduciendo precisamente un componente aleatorio.
Como tenemos 5 árboles la idea es crear 5 subsets de entrenamiento a partir del set original. Para lograr esto debemos hacer algo que se llama el muestreo con reemplazo o bootstrapping: en cada caso vamos a tomar al azar observaciones (es decir filas) del set original hasta completar un total de 6. El término “reemplazo” hace referencia a que una misma fila podrá aparecer varias veces en el subset que estamos creando.
Por ejemplo, digamos que para crear el primer subset se toman aleatoriamente las observaciones 1, 2, 5, 1, 1 y 3. Acá el reemplazo implica que la primera observación se repite tres veces:

Para el segundo subset tomaremos al azar y con reemplazo otro grupo de observaciones, por ejemplo las filas 6, 3, 2, 5, 6 y 2. De nuevo, el reemplazo implica que las filas 6 y 2 aparecerán repetidas en el subset:
Y así repetimos este procedimiento hasta obtener los cinco subsets de entrenamiento:
Más aleatoriedad: seleccionando al azar algunas características
Después de esto viene el entrenamiento, que consiste en tomar cada subset y realizar de forma recurrente las particiones del espacio de características para así crear cada árbol.
Y es acá donde introducimos un segundo elemento de aleatoriedad: en lugar de usar la totalidad de las características, seleccionaremos aleatoriamente una parte.
Así que para obtener cada nodo de cada árbol (es decir las particiones) en lugar de tomar las cuatro columnas escogeremos, al azar, sólo dos o tres. Supongamos que en nuestro ejemplo fijamos este parámetro en dos, aunque más adelante veremos cómo determinar el número de características más adecuado.
Si vamos al primer árbol, para determinar su primer nodo seleccionamos entonces de forma aleatoria dos de las características, supongamos que la 1 y la 4 y obtenemos la mejor partición:

Para el segundo nodo nuevamente escogemos de forma aleatoria otras dos características, supongamos que la 2 y la 3, y calculamos la mejor partición:
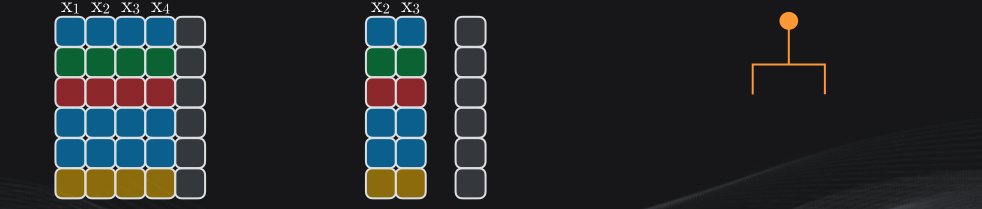
Y repetimos este procedimiento una y otra vez hasta construir el árbol completo y alcanzar el criterio de parada. Y esto lo repetimos para cada uno de los árboles que conforman el Bosque:
Y con esto tenemos listo el entrenamiento, que es similar al que se hace con los árboles de decisión convencionales, con la única diferencia de que para cada nodo se tomará aleatoriamente sólo una parte de las características.
¿Y cómo realizamos predicción con el Bosque entrenado?
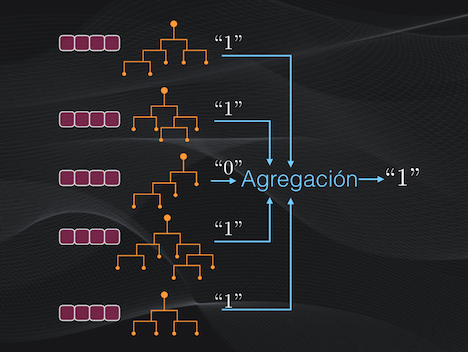
Con el Bosque Aleatorio ya entrenado es fácil realizar la predicción. Simplemente se introduce el nuevo dato a cada árbol, se realiza la clasificación individual y se escoge la categoría asignada por la mayoría de los árboles.
Por ejemplo, los árboles 1, 2, 4 y 5 clasificarán el dato como perteneciente a la categoría “1”, mientras que el árbol 3 lo clasificará como perteneciente a la categoría “0”. Así que la categoría final entregada por el bosque será “1”:
Si la tarea fuese de regresión el procedimiento sería muy similar: se realiza la regresión individual y el valor final sería simplemente el promedio de la predicción hecha por cada árbol:

Bagging y out-of-bag samples
En este punto es importante que resumamos los dos mecanismos esenciales en el funcionamiento de los Bosques aleatorios: el bootstrapping durante el entrenamiento y la agregación de los resultados para realizar la predicción. La combinación de estos dos términos se conoce como bagging, que es precisamente el nombre genérico con que se conoce a los algoritmos como los Bosques Aleatorios y otros similares.
Si miramos en detalle el bootstrapping veremos que en esta selección aleatoria de observaciones al final no todas quedarán incluidas en los subsets de entrenamiento. En realidad, aproximadamente una tercera parte de los ejemplos originales quedará por fuera y no será usada durante ese entrenamiento.
Así que, a diferencia de otros algoritmos de Machine Learning en donde al inicio se divide el set de datos en entrenamiento y validación, en el caso de los bosques aleatorios los datos de validación serán precisamente aquellos que no fueron seleccionados durante el muestreo aleatorio. Estos ejemplos de entrenamiento se conocen como muestras por fuera de la bolsa, o out-of-bag-samples.
La selección de hiperparámetros
Pero si nos devolvemos al ejemplo que acabamos de ver nos quedan tres preguntas por resolver: ¿cómo sabemos cuántos árboles usar?, ¿cómo sabemos hasta dónde hacer crecer los árboles? y ¿cómo sabemos cuántas características seleccionar aleatoriamente durante el entrenamiento?
Para ajustar estos hiperparámetros podemos introducir las muestras fuera de la bolsa al bosque aleatorio, y mirar cómo se comporta el error de la predicción cuando cambiamos alguno de estos parámetros.
Podemos primero fijar el número de características y el criterio de parada, y entrenar múltiples bosques cambiando progresivamente el número de árboles que lo conforman. En este caso veremos que a medida que se tienen más y más árboles el error irá disminuyendo. Usualmente, en aplicaciones prácticas, se usan entre 100 y 200 árboles:
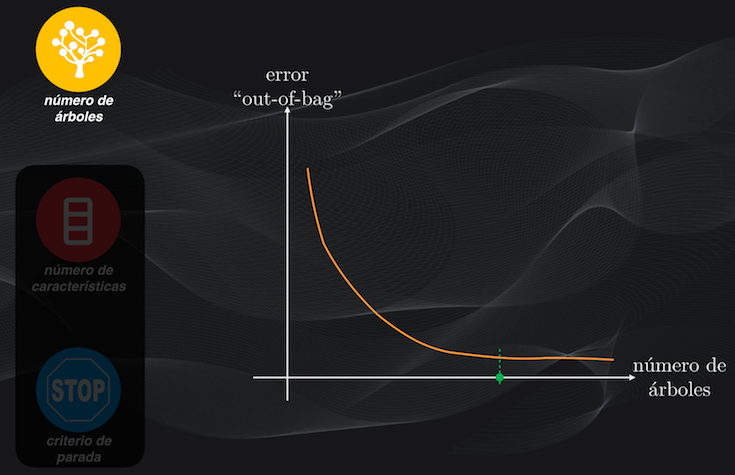
Con el número de árboles ya determinado, fijamos el criterio de parada y repetimos el procedimiento cambiando el número de características, y escogemos aquel que genere el menor error:
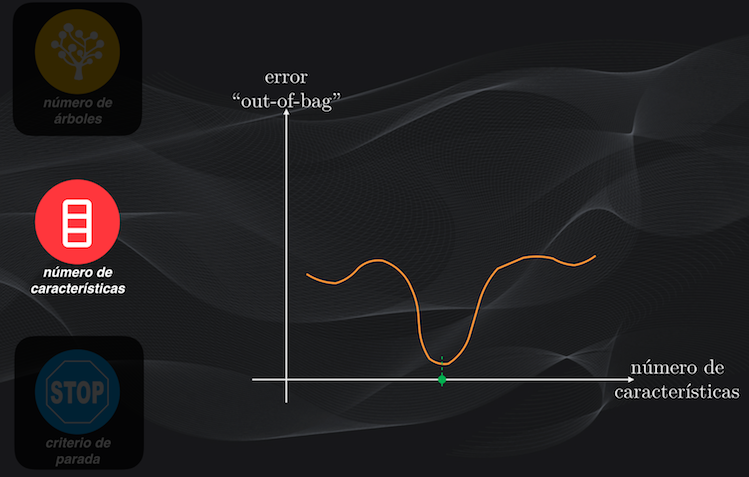
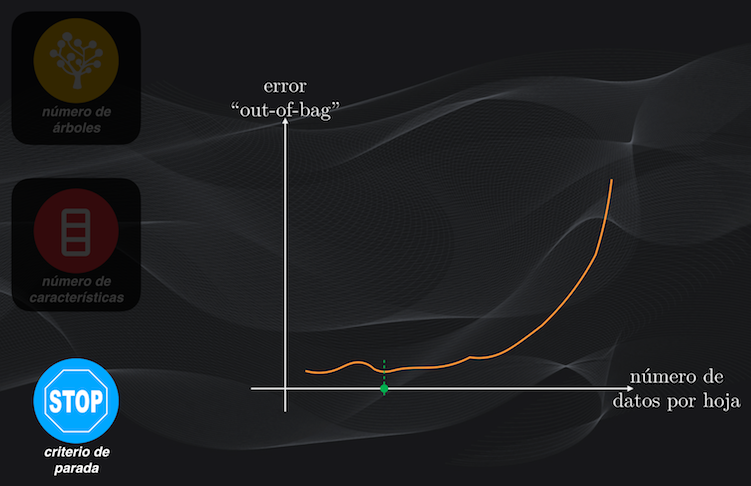
Finalmente, con el número de árboles y de características fijo, variamos el criterio de parada y escogemos el que arroje el menor error. Recuerda que el criterio de parada puede ser, por ejemplo, el mínimo número de datos de una hoja, como lo vimos al entrenar los Árboles de Clasificación:
Las características más importantes (feature importance)
Otra de las ventajas interesantes de los Bosques Aleatorios está en que, al igual que con los Árboles de Decisión, podemos establecer el orden de importancia de las características, usando como punto de partida el índice Gini (para el caso de la clasificación) o el error cuadrático medio (para el caso de la regresión), que permiten medir precisamente qué tan buena es la partición hecha en cada nodo.
Así que si durante el entrenamiento del Bosque Aleatorio mantenemos un registro de todas estas puntuaciones, al final podremos obtener el puntaje individual de cada característica, y podremos determinar cuáles de ellas generan las mejores particiones y cuáles no:
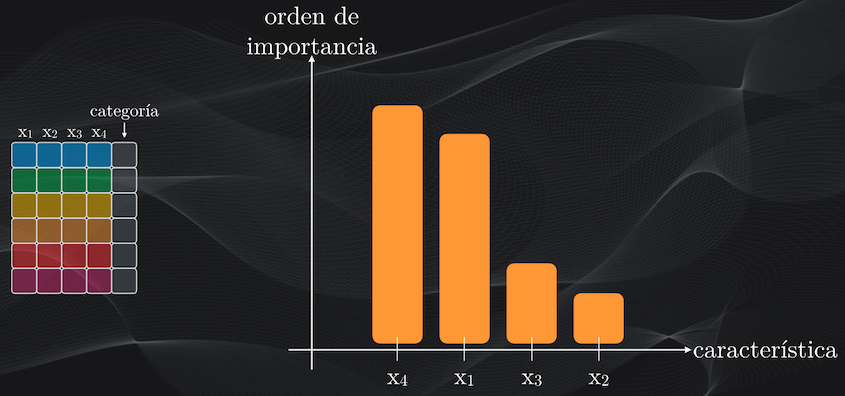
Esta información puede resultar súper útil al momento de desarrollar un modelo de Machine Learning, porque podemos precisamente seleccionar las características más relevantes y descartar otras de menor importancia.
Conclusión
Bien, y con esto tenemos un panorama completo y detallado de lo que son los Bosques Aleatorios, uno de los algoritmos más importantes del Machine Learning y que en la práctica es uno de los más usados para resolver una gran variedad de problemas.
En resumen lo que hace este método es usar el bagging (bootstrapping y agregación) para entrenar múltiples árboles y luego combinar sus resultados individuales, logrando así tener un Bosque Aleatorio con un bias y una varianza relativamente bajas.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: