Clasificación con Árboles de Decisión: el algoritmo CART
En este post veremos todos los detalles de funcionamiento de los Árboles de Decisión para la clasificación, uno de los algoritmos más sencillos pero a la vez más poderosos del Machine Learning.
Veremos la explicación completa del algoritmo CART, hablaremos de cómo controlar el “overfitting” en un Árbol (pre-poda y post-poda), y veremos sus principales ventajas y desventajas.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción: la clasificación
Los árboles de decisión son tal vez el algoritmo más sencillo pero a la vez uno de los más poderosos del Machine Learning, y son muy usados cuando tenemos sets de datos relativamente complejos.
En este post veremos el algoritmo CART (por sus siglas en Inglés Classification and Regression Trees o árboles de clasificación y regresión), el más usado en la actualidad para implementar árboles de decisión.
En el caso particular de la clasificación lo que buscamos es entrenar un modelo que sea capaz de determinar la categoría a la que pertenece un dato en particular.
La idea es que el modelo aprenda a calcular una frontera de decisión que permita asignar una u otra categoría al dato de interés:

Un ejemplo típico de este tipo de tarea es la clasificación de correos electrónicos entre normales y spam:
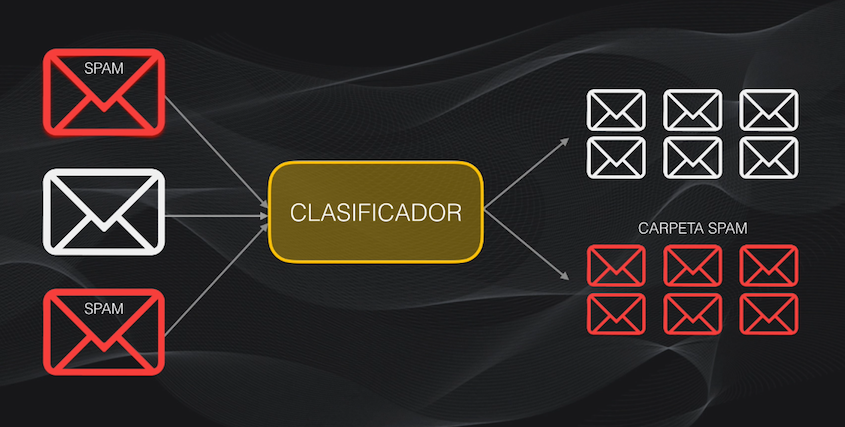
Clasificación con Perceptrones y Redes Neuronales
En posts anteriores vimos cómo por ejemplo la Regresión Logística o las Redes Neuronales podían ser usadas para clasificar sets de datos relativamente complejos.
Sin embargo, el problema de la Regresión Logística es que nos permite clasificar datos linealmente separables (es decir donde la frontera de decisión es una simple línea recta):
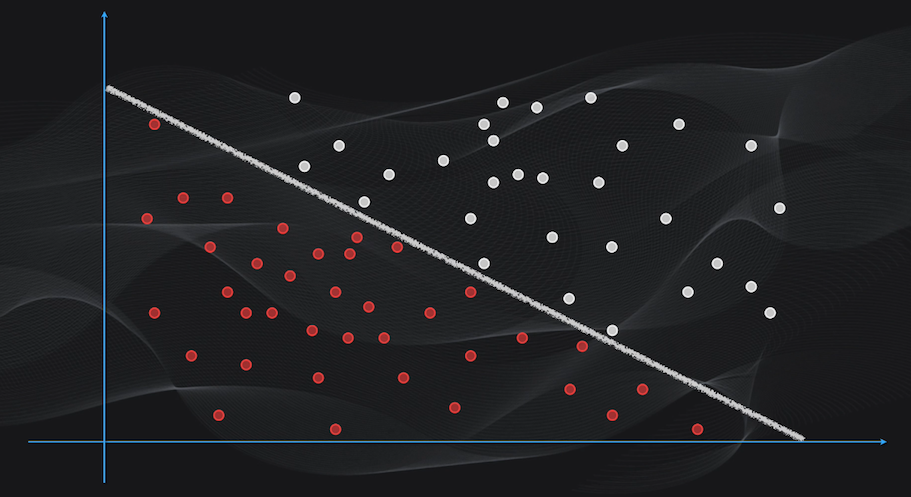
Mientras que el gran inconveniente de las Redes Neuronales es que son generalmente modelos de “caja negra” que son excelentes clasificadores pero no son fáciles de interpretar. Es decir que usualmente resulta difícil explicar en términos simples porque la red clasificó un dato de una forma o de otra. Por ejemplo, si hacemos uso de una Red Neuronal para nuestro problema de clasificar correos electrónicos, muy probablemente alcanzaremos una precisión alta pero surgirán preguntas difíciles de responder como: ¿Por qué un correo fue clasificado como spam y no como normal? ¿qué elementos del contenido del correo influyeron en esta decisión? ¿se puede confiar en los resultados de esta clasificación con Redes Neuronales?
Precisamente los Árboles de Decisión son una alternativa a estos inconvenientes, pues permiten clasificar datos relativamente complejos y a la vez generan modelos que son fáciles de interpretar.
Árboles de decisión: una idea intuitiva
El algoritmo más usado en la actualidad para el entrenamiento de árboles de decisión se conoce como CART, o Árbol de Clasificación y Regresión por sus siglas en Inglés, y a continuación vamos a ver en detalle el funcionamiento de este algoritmo para la clasificación. En el próximo post hablaremos de cómo usarlo para implementar árboles de regresión.
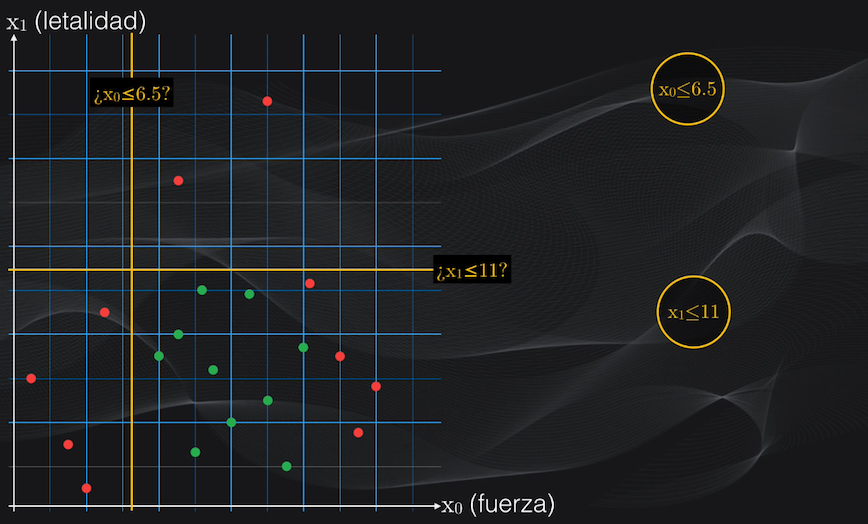
Partamos de un ejemplo sencillo para entender cómo funciona el algoritmo. Supongamos que somos fanáticos del Anime, y que queremos diferenciar demonios de asesinos de demonios. Cada uno de estos personajes posee ciertas características, como el nivel de fuerza, o el nivel de letalidad, cada una en una escala de 0 a 20:

Para representar esto gráficamente dibujaremos un plano en dos dimensiones, con el eje horizontal igual al nivel de fuerza y el eje vertical igual al nivel de letalidad. Los demonios estarán representados con puntos rojos y los asesinos de demonios con puntos verdes, y en total tendremos 20 personajes:
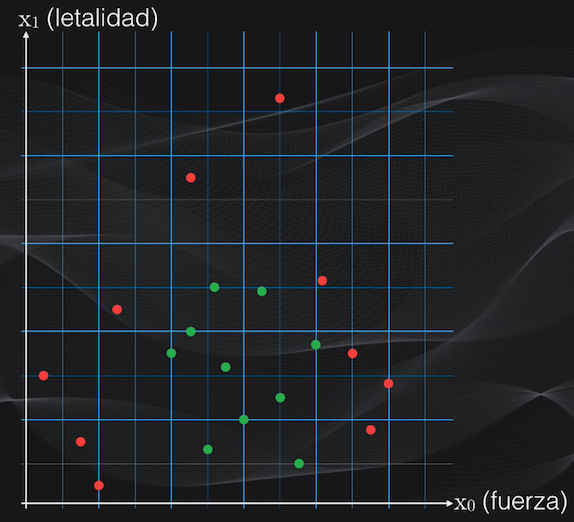
A los niveles de fuerza y de letalidad los llamaremos características y aunque por simplicidad estamos considerando únicamente dos características es importante tener en cuenta que los Árboles de Decisión funcionan igualmente con sets de datos mucho más complejos, con tres o más características.
La idea es encontrar una forma de separar los demonios de los asesinos, es decir de calcular unas fronteras de decisión que permitan posteriormente clasificar nuevos personajes en una de estas dos categorías.
La idea de la clasificación con árboles de decisión es simple: iterativamente se irán generando particiones binarias (es decir de a dos agrupaciones) sobre la región de interés, buscando que cada nueva partición genere un subgrupo de datos lo más homogéneo posible:
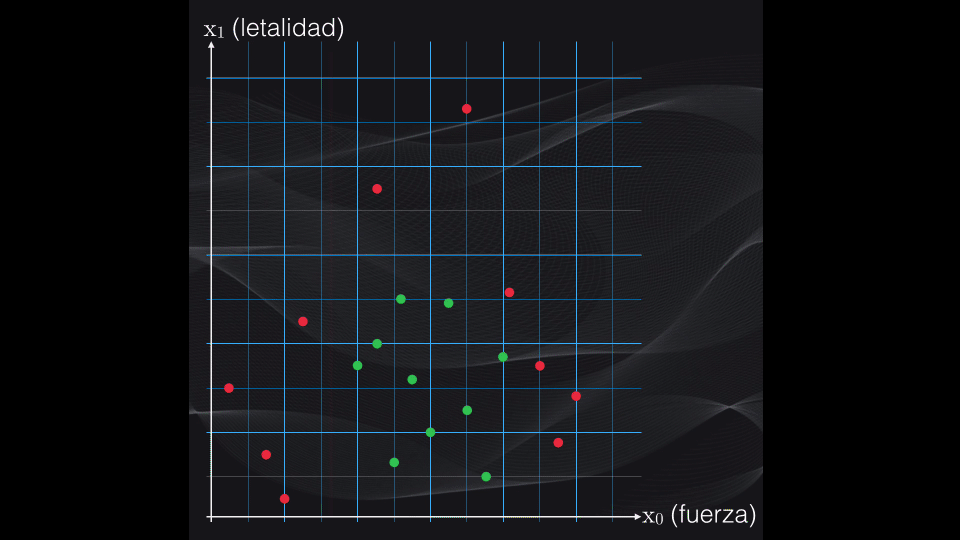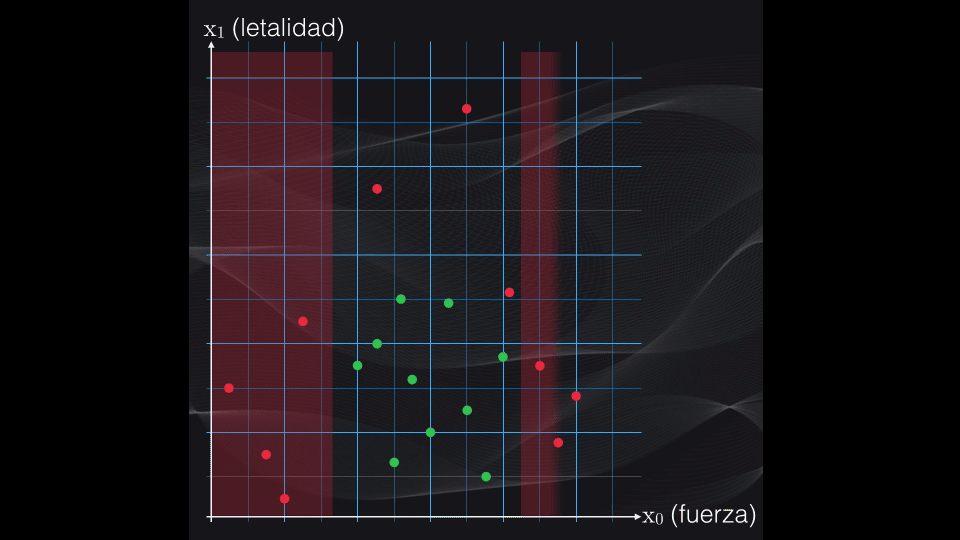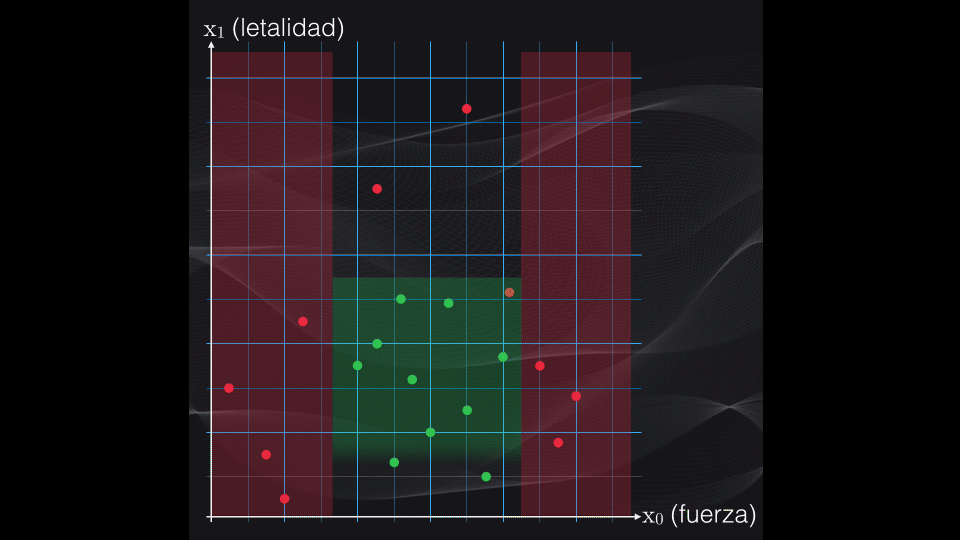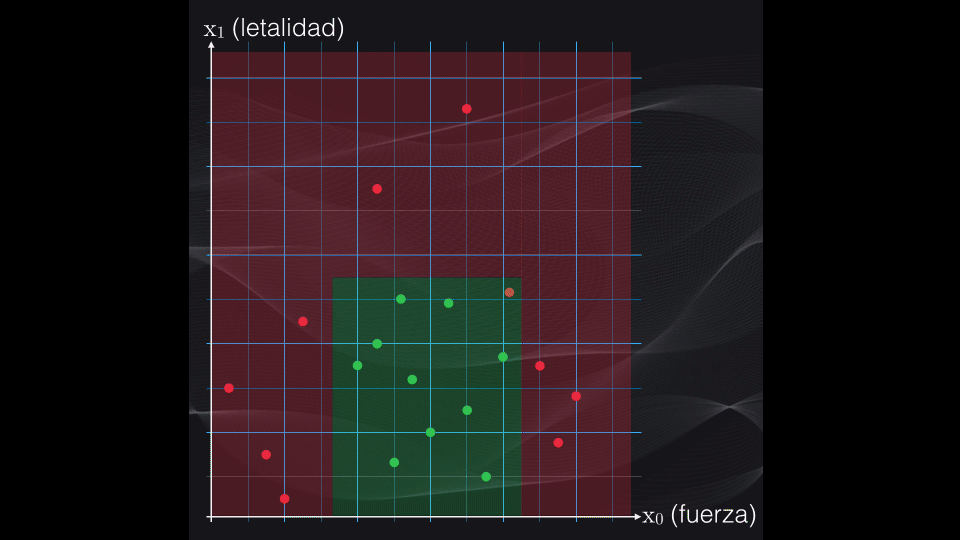
Así, primero se establece una condición. Dependiendo de si los datos cumplen o no la condición tendremos una primera partición en dos subregiones (de ahí el término particiones binarias):
Y luego se repite el procedimiento anterior, una y otra vez, hasta que al final se obtengan agrupaciones lo más homogéneas posible, es decir con puntos que pertenezcan en lo posible a una sola categoría:
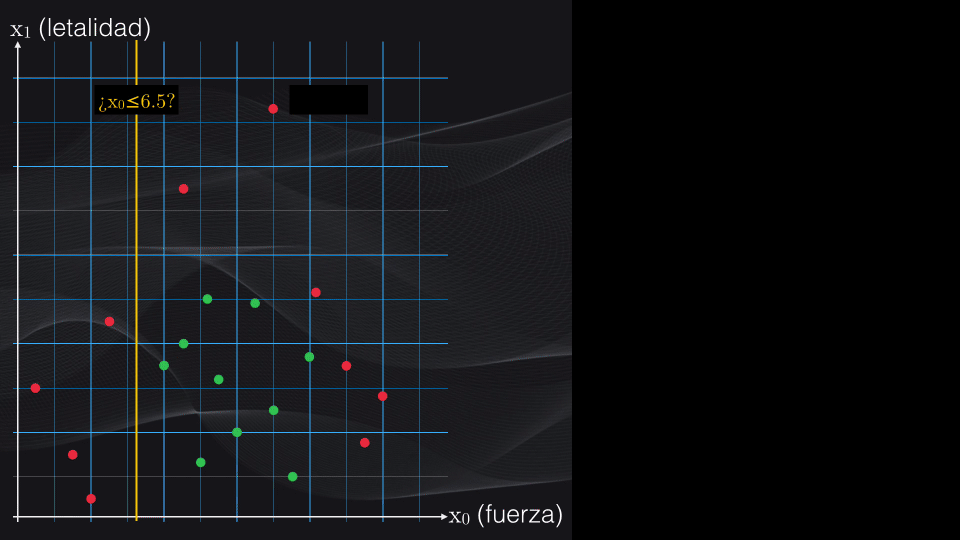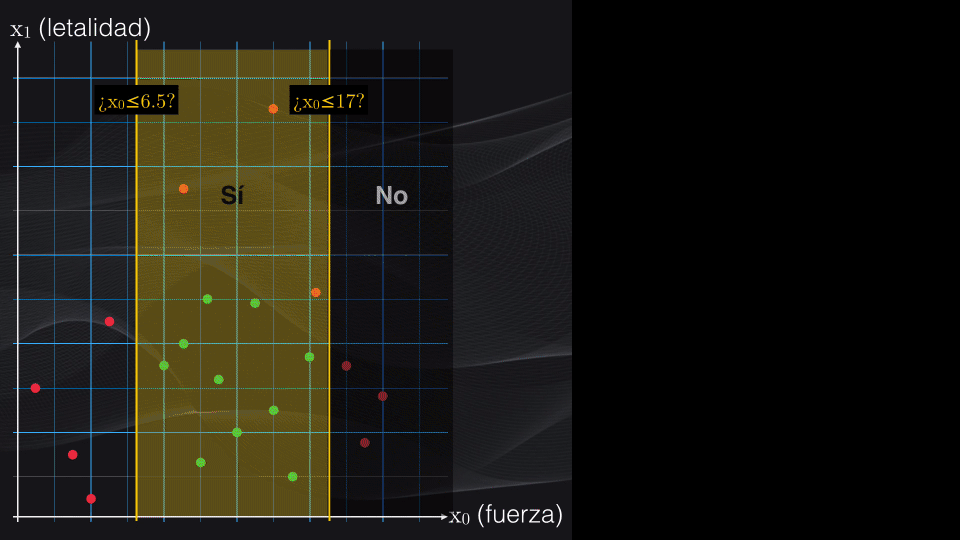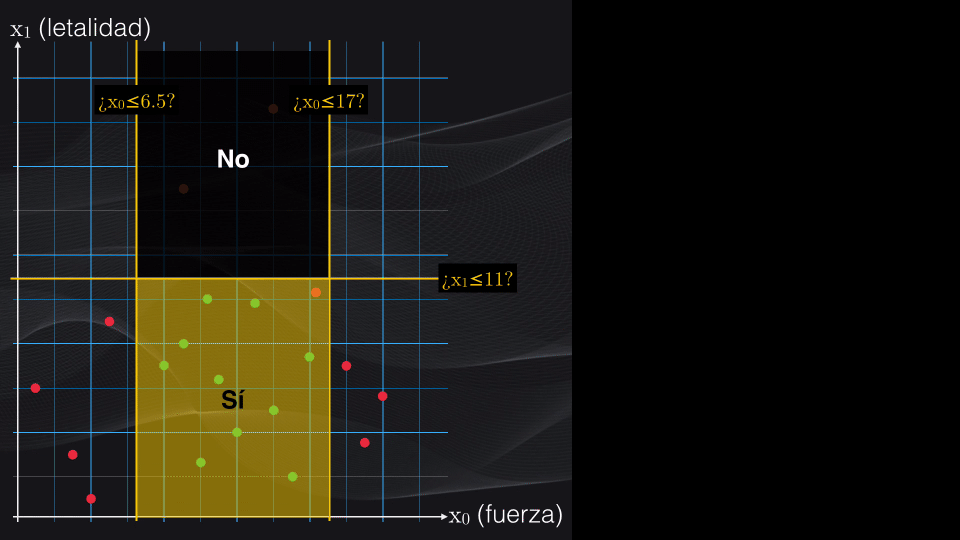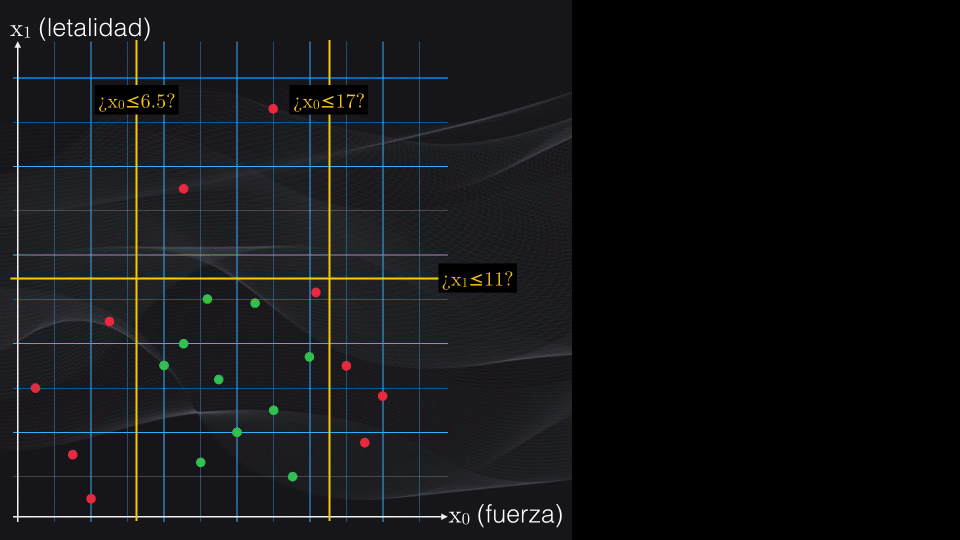
Esta serie de particiones la podemos representar gráficamente precisamente a través de un árbol de decisión!
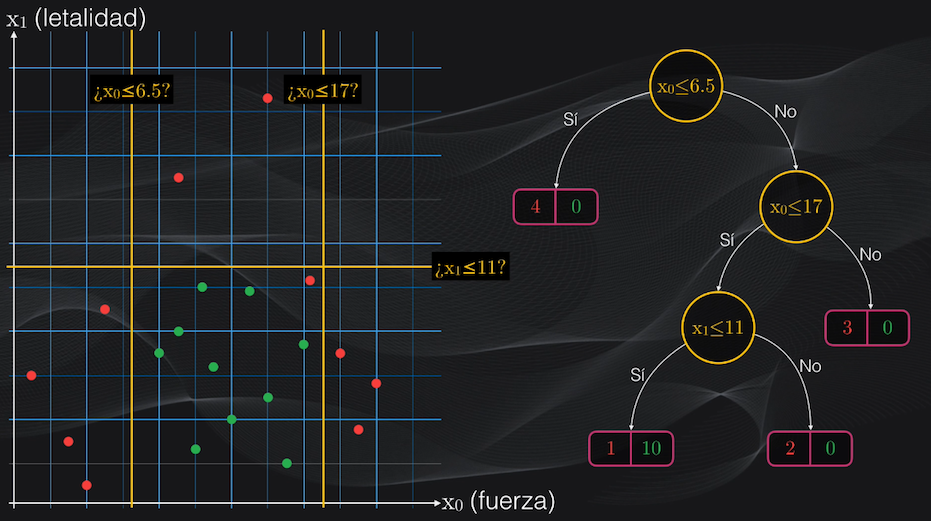
El punto de partida del árbol se conoce como la “raíz” y contiene la primera condición. Este nodo genera la primera partición binaria, lo que se representa gráficamente como dos flechas indicando si se cumple o no la condición:
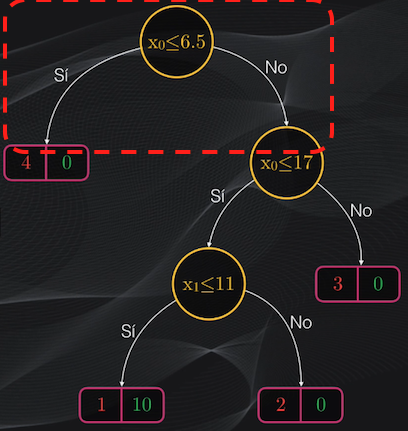
Luego estarán los nodos internos, que corresponden a condiciones adicionales para continuar realizando la partición:
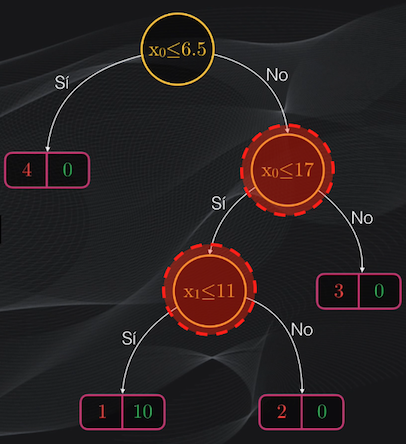
y también los nodos hoja (o simplemente “hojas”) que corresponden a las subregiones más allá de las cuales no realizaremos más particiones:
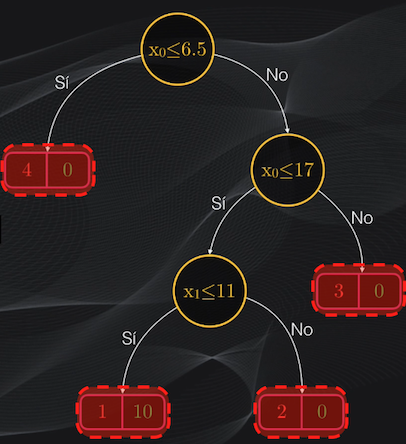
La profundidad del árbol es simplemente la trayectoria más larga entre la raíz y una de las hojas, y en nuestro caso tendremos un árbol de profundidad tres:
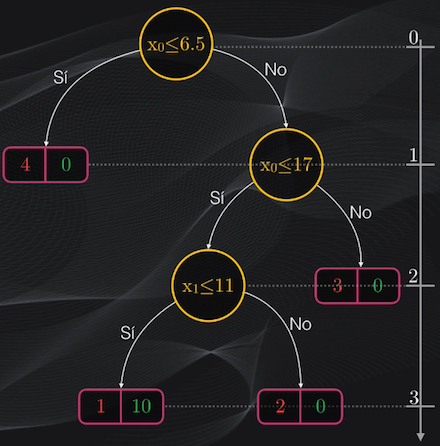
Árboles de decisión: el algoritmo CART
Ok, hasta acá tenemos una idea general de lo que es un árbol de decisión. Pero nos quedan varias preguntas de fondo por responder: ¿cómo se construye de forma automática este árbol? ¿cómo lograr que en esta construcción se generen los subgrupos más homogéneos posibles? ¿cómo se determinaron los valores para cada una de las condiciones que definen los nodos del árbol?
Acá es donde entra el algoritmo CART, que es capaz de generar automáticamente las particiones cada una con las agrupaciones más homogéneas posible.
El índice Gini: una medida de homogeneidad
Para medir esta homogeneidad se usa el índice Gini, que mide el grado de “impureza” de un nodo: índices Gini iguales a cero indican nodos puros (es decir con datos que pertenecen a una sola categoría), mientras que índices mayores que cero y con valores hasta de uno indican nodos con impurezas (es decir con datos de más de una categoría):

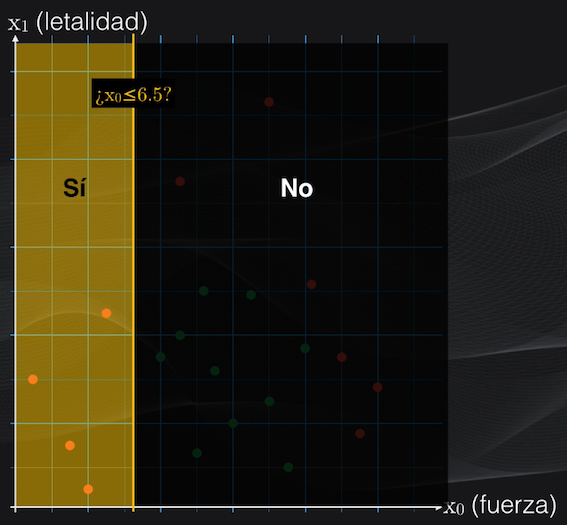
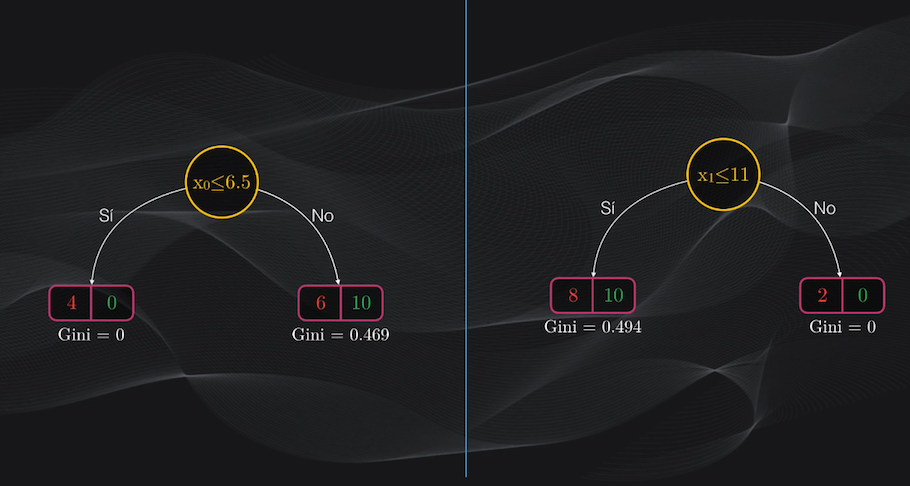
Por ejemplo, volviendo a nuestro set de datos, analicemos dos posibles particiones iniciales: $x_0$ menor o igual que 6.5 y $x_1$ menor o igual que 11:
Para el primer umbral veremos que la partición del lado izquierdo contendrá únicamente cuatro puntos rojos, y ningún punto verde, mientras que la partición del lado derecho tendrá 6 puntos rojos y 10 verdes:
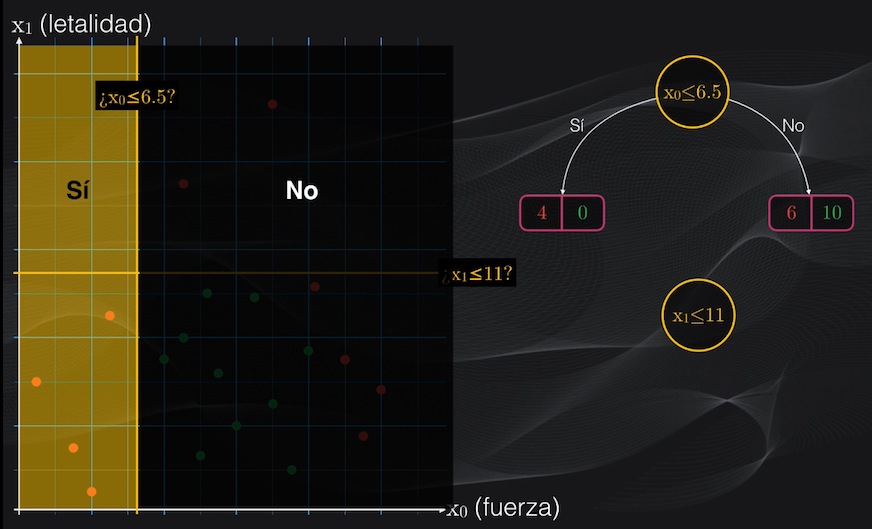
Esto corresponde a un nodo izquierdo totalmente puro (es decir un nodo hoja) con un índice Gini igual a cero, y a un nodo derecho con impurezas con un índice Gini de 0.469:
$$Gini_{izquierdo} = 1 - (4/4)^2 - (0/4)^2 = 0$$ $$Gini_{derecho} = 1 - (6/16)^2 - (10/16)^2 = 0.469$$
Para el segundo umbral veremos que el nodo izquierdo será puro, pues contendrá 2 puntos rojos y ninguno verde, mientras que el nodo derecho contendrá impurezas: 8 puntos rojos y 10 verdes:
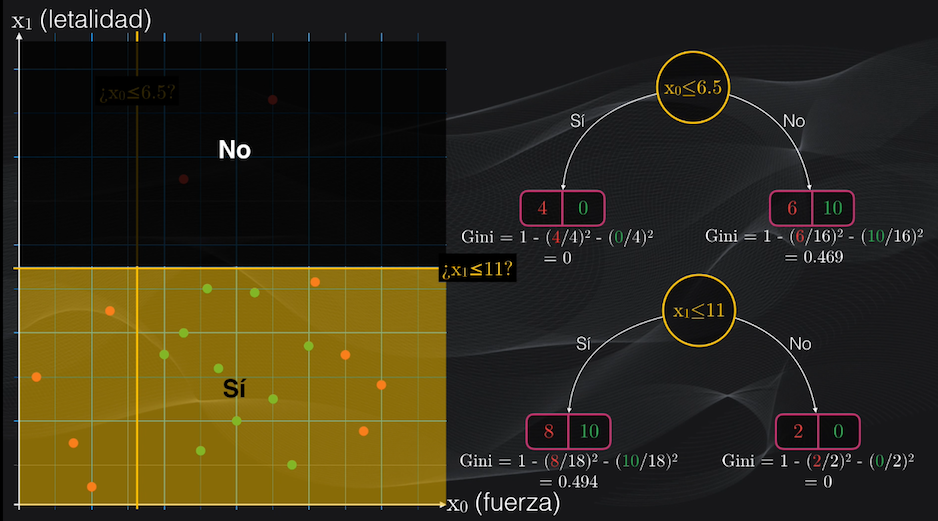
Esta segunda partición equivale a tener un nodo derecho con un índice Gini igual a 0 y un nodo izquierdo con índice Gini igual a 0.494.
La función de costo: ¿cuál es la mejor partición?
Para saber cuál de estas dos particiones es la mejor el algoritmo CART define una función de costo que asigna un puntaje al nodo padre, usando el promedio ponderado de los índices Gini individuales de sus nodos hijos.
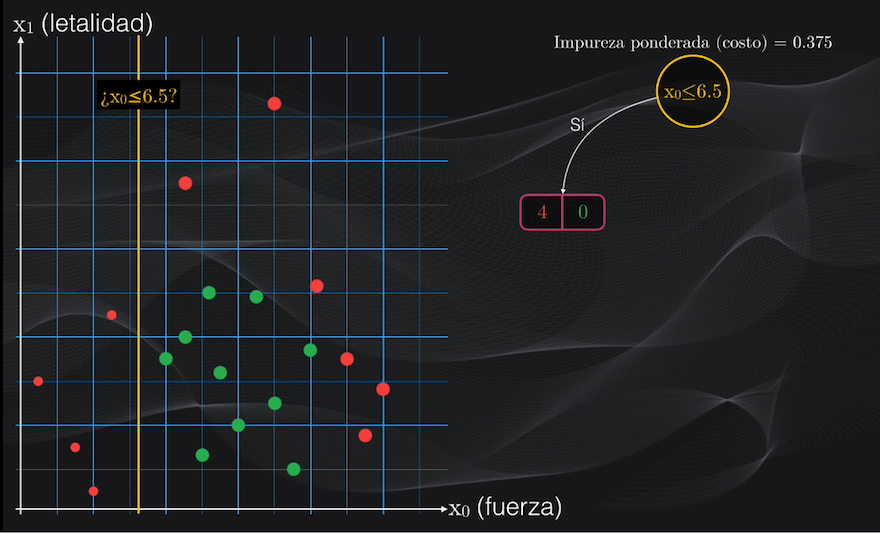
Para entender esto veamos nuevamente las dos posibles particiones. Para calcular la función de costo en cada caso debemos obtener el valor promedio ponderado de la impureza de los nodos hijo, a izquierda y derecha:
Esto se calcula tomando el índice Gini correspondiente a cada nodo y multiplicándolo por el resultado de dividir el número de datos pertenecen a la nueva agrupación entre el número total de datos antes de la partición.
Así, para la primera partición, el nodo hijo del lado izquierdo tiene un índice Gini igual a cero, el número de datos resultantes de la partición es 4 puntos rojos y cero verdes, y el número total de datos antes de la partición es simplemente el set de datos original: 20 puntos. Así que para este nodo hijo se tiene una impureza ponderada igual a cero:
$$Impureza_{izquierda_{ponderada}} = 0 \cdot{\frac{4+0}{20}} = 0$$
Para el nodo del lado derecho el índice Gini era 0.469, tras la partición se obtuvieron 6 puntos rojos y 10 verdes, y el número total de puntos antes de la partición sigue siendo 20, lo que nos arroja una impureza ponderada de 0.375:
$$Impureza_{derecha_{ponderada}} = 0.469 \cdot{\frac{6+10}{20}} = 0.375$$
Al sumar estos valores ponderados de las impurezas de cada uno de estos nodos obtenemos el valor de la función de costo del nodo padre, que es igual a 0.375:
$$Costo_{partición_1} = 0 + 0.375 = 0.375$$
Si repetimos el mismo procedimiento para la segunda opción, es decir, si calculamos las impurezas ponderadas individuales de los nodos hijos, y las sumamos, obtenemos un valor para la función de costo igual a 0.446:
$$Impureza_{izquierda_{ponderada}} = 0.494 \cdot{\frac{8+10}{20}} = 0.446$$ $$Impureza_{izquierda_{ponderada}} = 0 \cdot{\frac{2+0}{20}} = 0$$ $$Costo_{partición_2} = 0.446 + 0 = 0.446$$
El funcionamiento en detalle del algoritmo CART
Y ahora sí tenemos un criterio para definir cuál de las dos particiones es mejor: ¡tomamos simplemente la que tenga el menor valor posible para la función de costo, lo que indica un menor nivel de impureza y por tanto una mejor clasificación!
Y con esto ya tenemos la base del algoritmo CART para la clasificación con Árboles de Decisión. Y este mismo procedimiento se aplica iterativamente hasta lograr separar adecuadamente los datos, es decir hasta generar las agrupaciones lo más homogéneas posible.
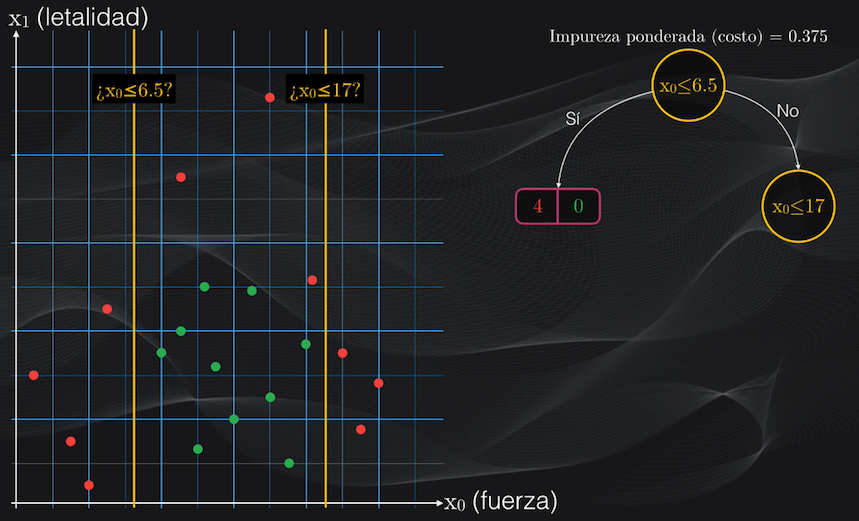
Así que si volvemos al nodo raíz seleccionado, vemos que el nodo hijo de la izquierda es una hoja, y por tanto no haremos más particiones. Sin embargo el nodo de la derecha aún contiene impurezas y podemos intentar hacer más particiones:
Si repetimos el procedimiento anterior, y analizamos todos los umbrales posibles, veremos que la condición $x_0$ menor o igual a 17 es la que generará el menor costo posible:
Al aplicar esta condición se generará un nodo izquierdo impuro, con tres puntos rojos y 10 puntos verdes, y un nodo derecho totalmente puro con tres puntos rojos y ningún punto verde. El costo promedio de este nuevo nodo padre será de 0.288 y vemos que es inferior al costo del nodo raíz, con lo cual podemos verificar que progresivamente estamos logrando obtener agrupaciones cada vez más homogéneas:
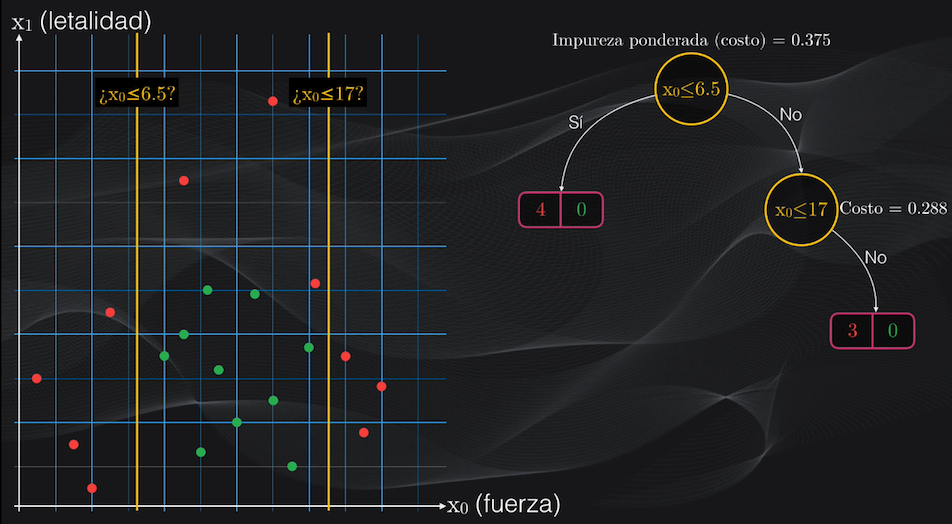
Como el nodo izquierdo recién obtenido es impuro, podemos continuar dividiéndolo. Si repetimos el mismo procedimiento, veremos que la condición $x_1$ menor o igual a 11 generará un nodo padre con el menor costo posible:
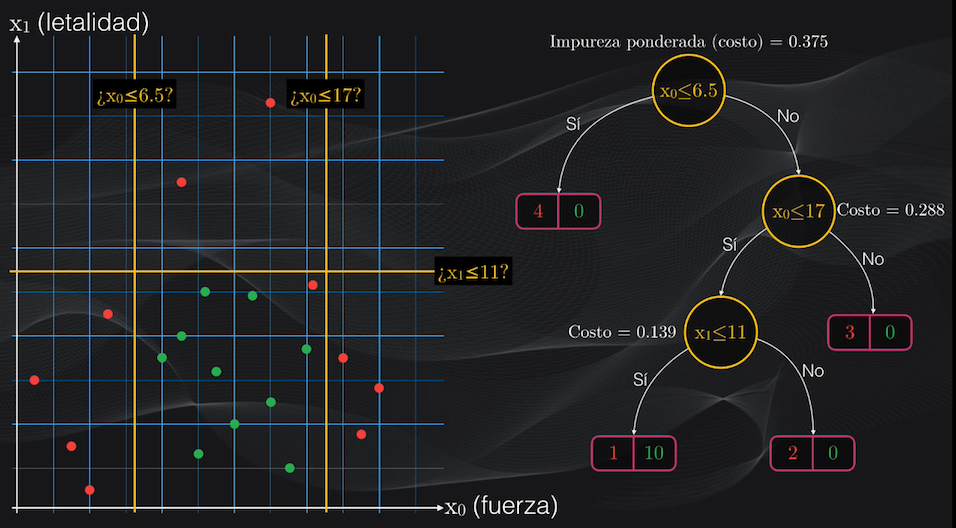
Esta nueva partición generará un nodo hijo izquierdo impuro, con 1 punto rojo y 10 puntos verdes, y un nodo derecho totalmente puro, con tres puntos rojos y 0 puntos verdes. Al obtener la función de costo para el nodo padre recién obtenido, tendremos un valor de 0.139, que de nuevo es inferior a la de los nodos anteriores.
Y podríamos continuar subdividiendo el nuevo nodo izquierdo obtenido, pero si lo hacemos podrían aparecer problemas de overfitting en nuestro árbol de decisión. Pero de esto hablaremos en un momento.
En resumen: así funciona el algoritmo CART para la clasificación
Por ahora podemos resumir el algoritmo CART para realizar la clasificación con árboles de decisión de la siguiente manera:
- Para crear la raíz del árbol, es decir la primera partición, se toman todas las características y, para cada una de ellas, se definen todos los posibles umbrales a que haya lugar. Cada umbral será simplemente el punto intermedio entre dos valores consecutivos de cada característica.
Por ejemplo, en el caso particular de nuestro set de datos tenemos dos características, $x_0$ y $x_1$ Como en total tendremos 20 datos, por cada característica existirán 19 umbrales, así que en total tendremos 38 umbrales por evaluar.
-
Para cada uno de estos umbrales se calcula la partición (nodo izquierdo y nodo derecho) y para cada nodo hijo se calcula el índice Gini. Con estos nodos hijos se calcula la función de costo del nodo padre, que es el promedio ponderado de los índices Gini de sus hijos.
-
Se toma el umbral (o nodo padre resultante) que tenga la función de costo con el menor valor posible, indicando que la partición obtenida es la más homogénea de todas las analizadas.
-
Una vez se haya realizado esta partición, se repite el mismo procedimiento de forma iterativa para los nodos resultantes, exceptuando los que sean nodos hoja
¿Cómo realizar la predicción?
Bien, en la sección anterior vimos cómo usar el algoritmo CART para entrenar nuestro Árbol de Decisión, lo que equivale a encontrar las condiciones para cada nodo padre con el fin de lograr las particiones lo más homogéneas posible.
Una vez entrenado nuestro árbol de decisión podemos realizar la clasificación de un nuevo personaje, lo que se conoce como predicción.
Supongamos que tenemos uno con un nivel de fuerza igual a 13 y un nivel de letalidad igual a 17:
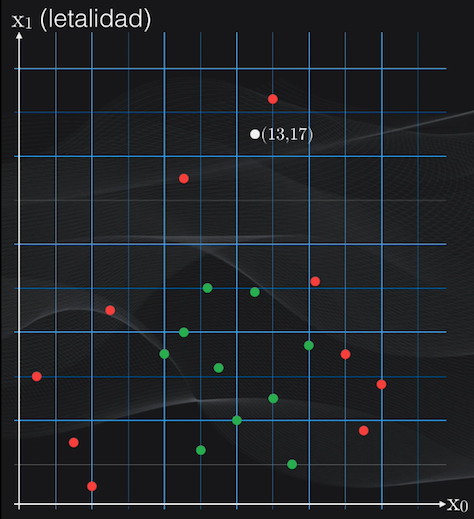
Para clasificarlo con el árbol ya entrenado simplemente llevamos estas dos características al modelo y comenzamos a evaluar una a una las condiciones en cada uno de los nodos: ¡la categoría a la que pertenece el personaje será simplemente el nodo en el cual resulte ubicado después de evaluar estas condiciones!
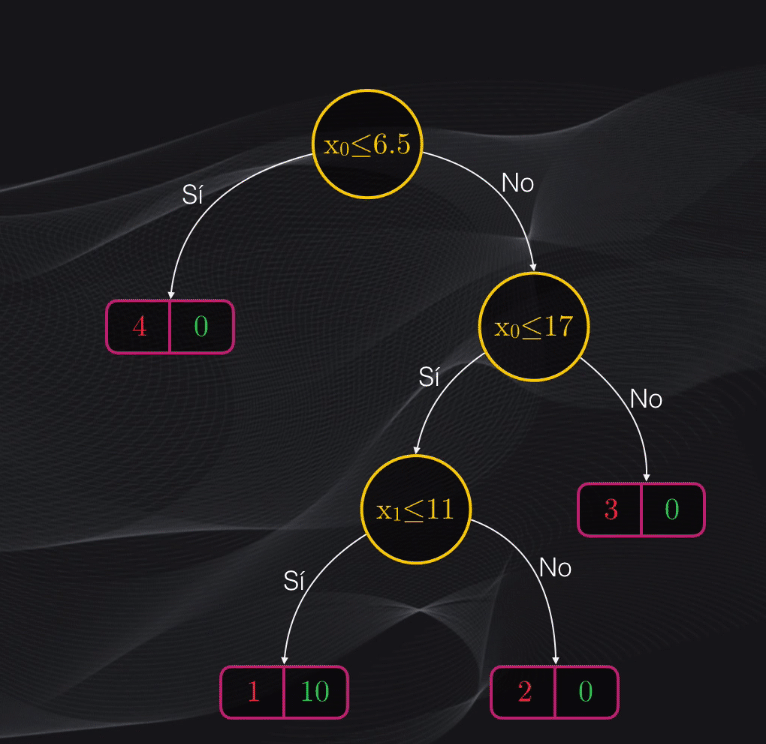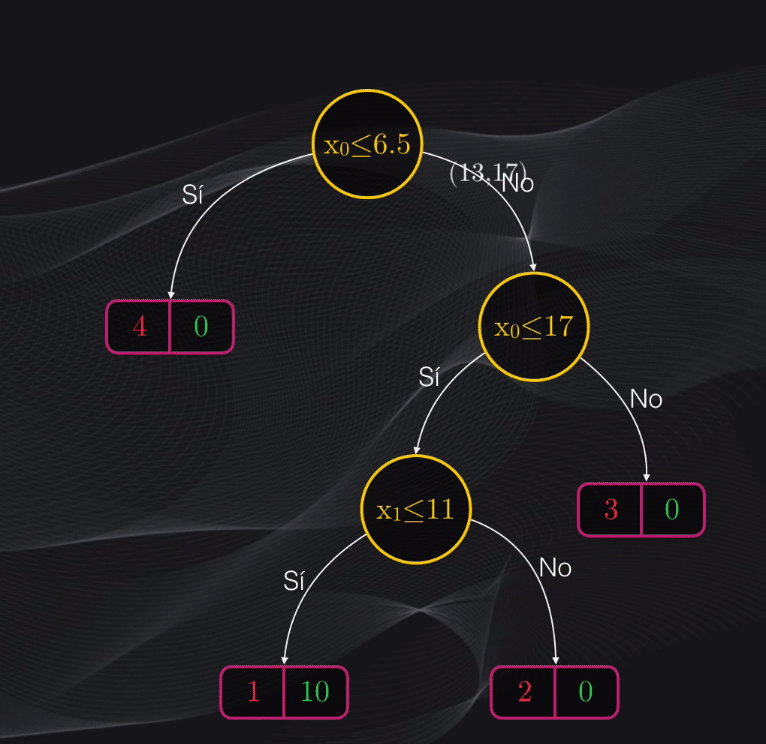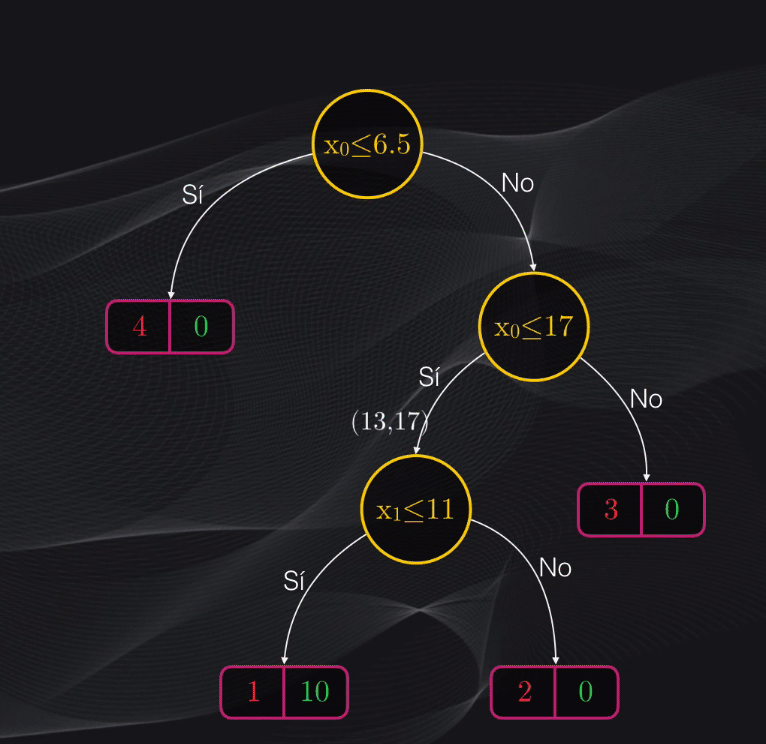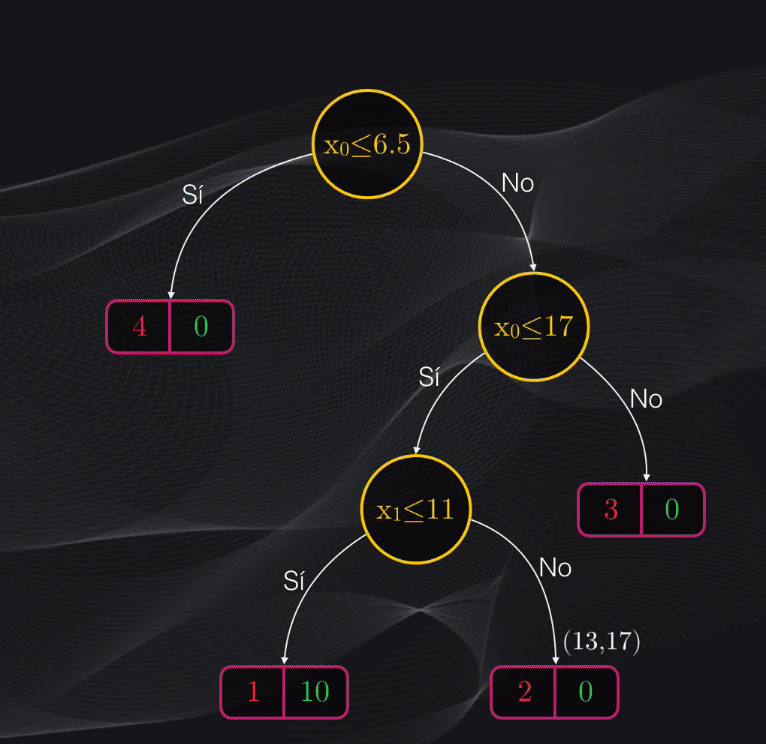
En el caso anterior, el nuevo dato será clasificado en la categoría demonio, pues el nodo hoja en el cual estará ubicado contiene más puntos rojos (demonios, 2) que puntos verdes (asesinos de demonios, 1)
Ventajas y desventajas de los árboles de decisión para clasificación
El Árbol de Decisión que acabamos de entrenar tenía un nodo impuro al final. ¿Porqué en este caso no seguimos generando más particiones?
Pues perfectamente podríamos hacerlo, pero el problema es que esto nos llevaría al overfitting. Es decir, en caso de dividir este nodo estaríamos obteniendo dos nuevos nodos hoja que mejorarían la clasificación:
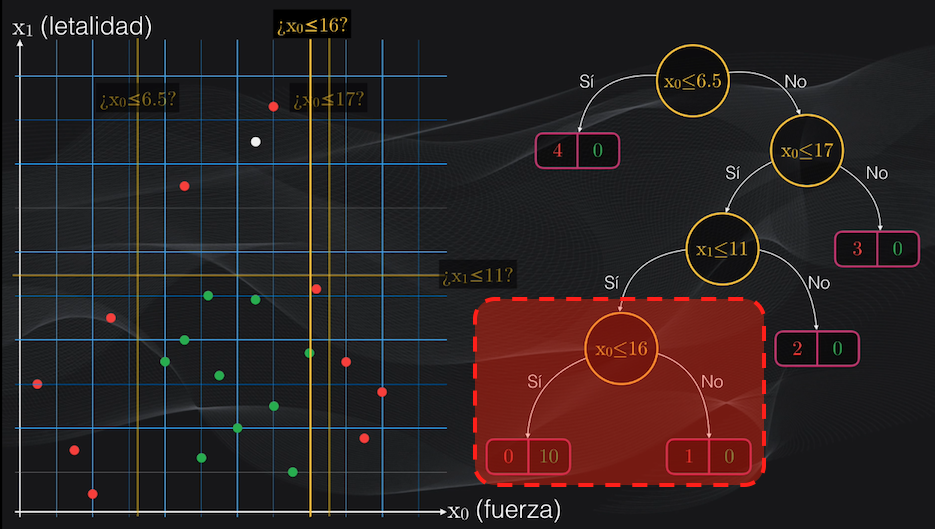
Pero las regiones obtenidas serían muy pequeñas, y es muy probable que al introducir un nuevo dato para ser analizado por el modelo, este resulte clasificado incorrectamente:
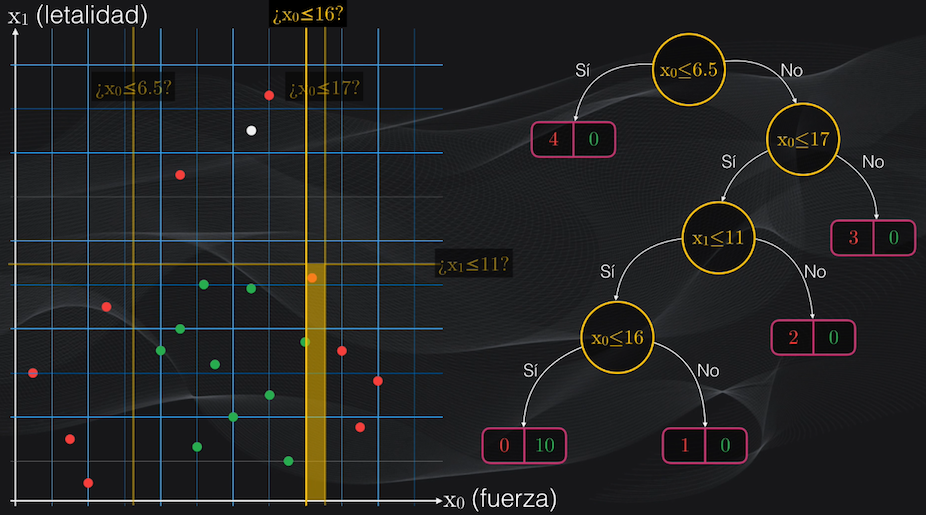
Es decir que el Árbol de Decisión se ajustará perfectamente al set de entrenamiento pero al momento de hacer predicciones no lo hará tan bien, y esto se conoce precisamente como overfitting.
Poda (o pruning): una solución al overfitting
Para evitar este overfitting tenemos dos opciones: restringir la libertad de crecimiento del árbol de decisión durante el entrenamiento (lo que se conoce como pre-poda), o quitarle algunos nodos (es decir “podar” el árbol) después del entrenamiento (lo que se conoce como post-poda).
Para restringir el crecimiento del árbol durante el entrenamiento, podemos usar hiperparámetros, que son variables numéricas que controlamos y que introducimos al momento de programar el árbol.
Podemos por ejemplo definir la profundidad máxima, o el mínimo número de datos que debe tener un nodo, o el mínimo número de datos de una hoja. Con estos hiperparámetros podemos evitar la aparición descontrolada de nodos en el árbol:
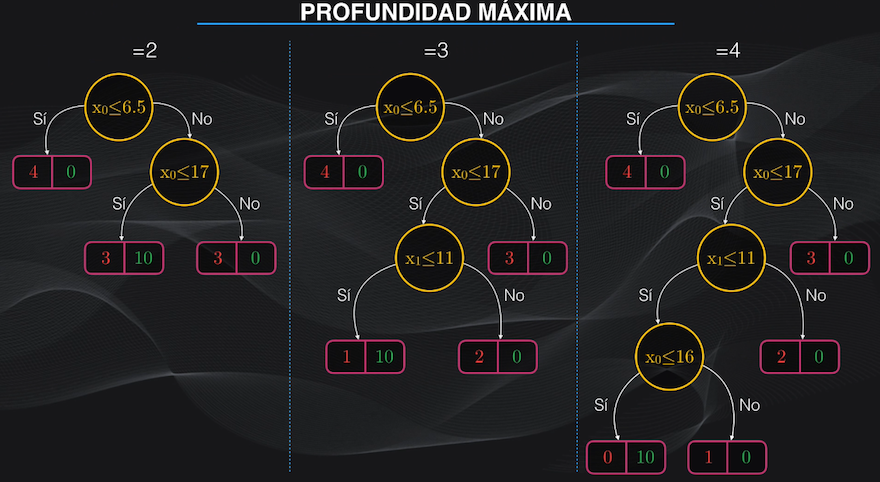
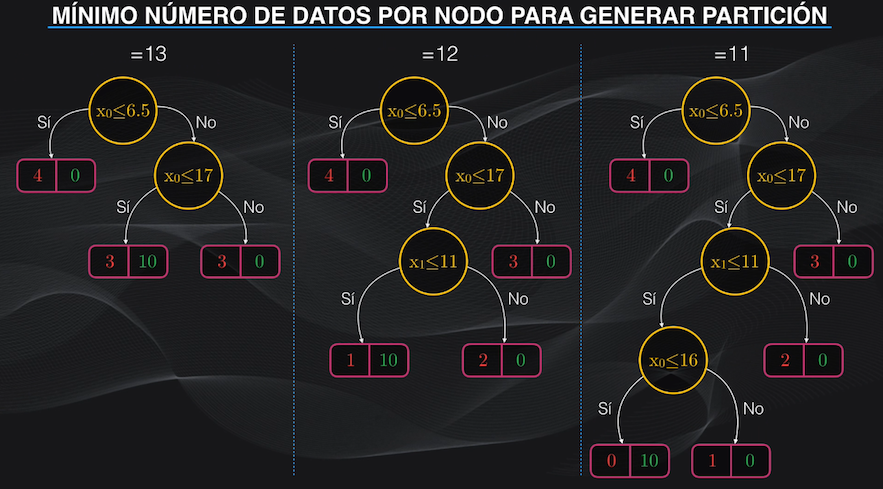
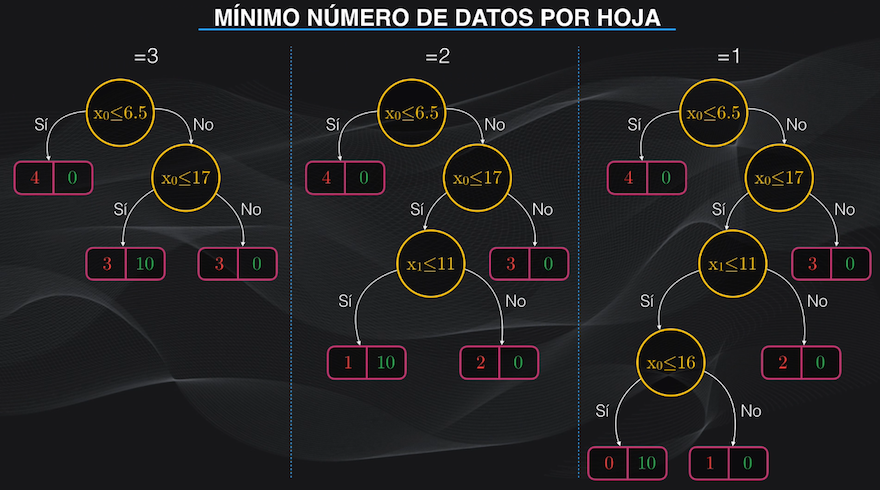
La otra forma de reducir el overfitting en nuestro Árbol de Decisión se hace después del entrenamiento, y consiste en “podar” o eliminar algunos nodos.
Uno de los métodos más usados es el de poda de complejidad de costos, que consiste en definir un hiperparámetro alpha que controla el nivel de overfitting: con un alpha igual a cero tendremos el árbol de decisión sin ningún recorte, y por tanto con un alto overfitting, mientras que a medida que aumenta alpha se eliminarán algunos nodos del árbol hasta lograr un balance adecuado entre la precisión con el set de entrenamiento y la que se logra con el de validación:
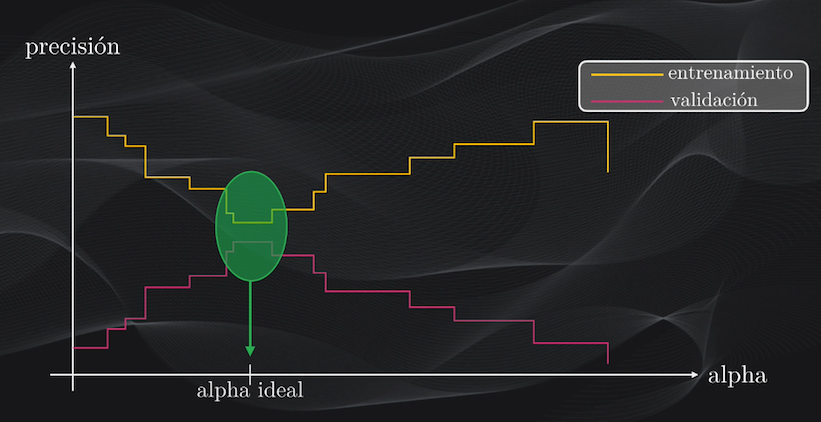
La interpretabilidad y la importancia de las características: dos ventajas de los Árboles de Decisión
Además de tener la posibilidad de clasificar datos con distribuciones relativamente complejas, una de las grandes ventajas de los Árboles de Decisión, comparados por ejemplo con la Regresión Logística o las Redes Neuronales, es la facilidad con la que pueden ser interpretados los resultados.
Volviendo a nuestro ejemplo, resulta muy sencillo entender la serie de reglas que hacen que un dato sea clasificado en una categoría o en otra: basta simplemente con mirar en detalle cada una de las condiciones en los nodos del árbol de decisión. Claro, esto resulta sencillo siempre y cuando el árbol y el número de características sea relativamente pequeño:
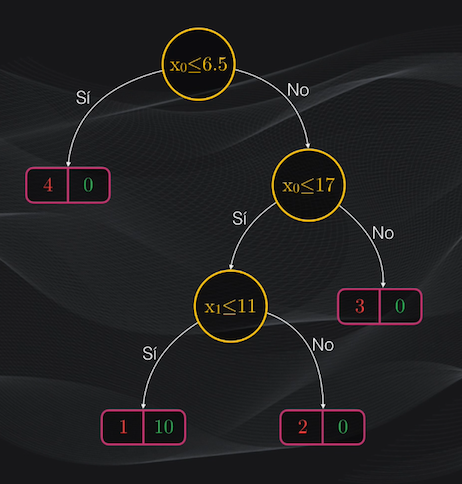
Y otra gran ventaja es que una vez entrenado el árbol podemos fácilmente determinar cuál (o cuáles) son las características que resultan más relevantes al momento de la clasificación.
De nuevo, si miramos el árbol de decisión obtenido podremos ver que 2 de sus tres nodos usan $x_0$ (el nivel de fuerza del demonio o del asesino) mientras que sólo uno usa $x_1$ (el nivel de letalidad).
Así que podemos decir que la primera característica es más relevante que la segunda al momento de la clasificación. De hecho existen métricas que permiten cuantificar estos niveles de importancia, pero esto lo veremos en detalle en el tutorial sobre cómo programar árboles de decisión para clasificación en Python.
Algoritmo greedy: la gran desventaja de CART
La gran desventaja es que CART es un algoritmo codicioso: para calcular el umbral óptimo en cada partición evalúa todas las posibles opciones. Para nuestro caso fue sencillo porque sólo teníamos dos características y 20 datos, pero entre más características y más datos tengamos el algoritmo requerirá más tiempo de entrenamiento.
Conclusión
Bien, espero que con esta explicación hayas podido entender todos los detalles de cómo funcionan los árboles de decisión usando el algoritmo CART para la clasificación de datos.
Estos árboles de decisión, junto con los árboles de regresión son la base de algoritmos más poderosos del Machine Learning, como los bosques aleatorios o los métodos de gradient boosting, que veremos en próximos posts.
También en un próximo post veremos un tutorial en Python sobre cómo implementar estos árboles de decisión para clasificar un set de datos.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: