¿Qué es una Red Neuronal?
En este post veremos en detalle qué es y cómo funciona una Red Neuronal, una de las principales arquitecturas del Machine Learning.
Al final de este post habremos aprendido:
- Qué es una neurona artificial
- En qué consiste una red neuronal artificial
- Cómo funciona una Deep Neural Network (DNN)
¡Así que listo, comencemos!
Tabla de contenido
Video tutorial
Como siempre, en el canal de YouTube encontrarán el video de este post:
Introducción: la neurona artificial
Las neuronas de nuestro cerebro se agrupan y se especializan para de esta forma lograr ejecutar tareas complejas. Una red neuronal artificial intenta emular este mismo principio, y es el resultado de agrupar neuronas artificiales que posteriormente son entrenadas. De esta manera, logran llevar a cabo diferentes funciones, como la regresión o la clasificación.
La figura de abajo muestra el diagrama de una neurona artificial. Podemos ver que esta neurona tiene una entrada x y una salida a, también llamada activación.
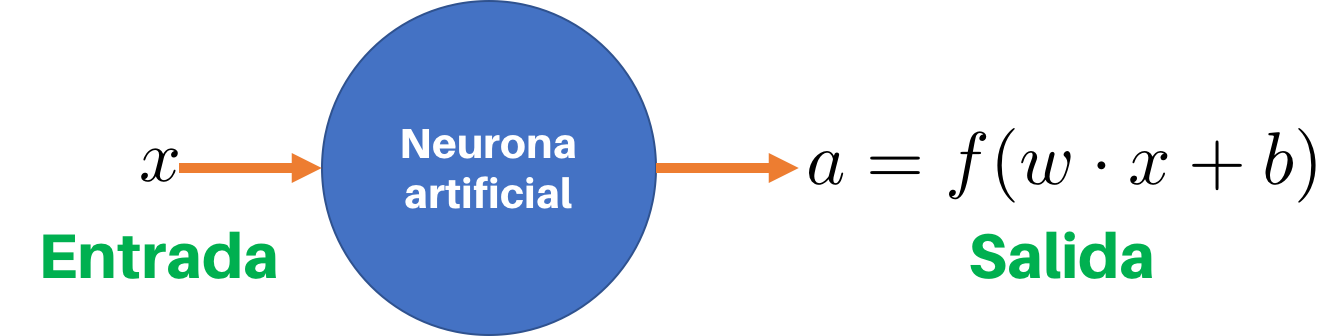
Para obtener la activación, la neurona ejecuta dos operaciones matemáticas:
- Transformación: es el resultado de tomar el dato de entrada (x) y aplicar la operación wx + b. Los parámetros w y b se calculan de forma automática durante el entrenamiento, generalmente usando el algoritmo del Gradiente Descendente
- Función de activación: es una función matemática no lineal que transforma el valor obtenido de la operación wx + b. Así, en la Regresión Logística esta función mapea wx+b al rango de valores 0 a 1, usando la función sigmoidal. De forma similar, en la regresión multiclase, la función softmax permite transformar wx+b en una probabilidad entre 0 y 1. El artículo la función de activación explica en detalle este elemento.
Podemos decir entonces que una neurona artificial se encarga de ponderar los datos de entrada y de posteriormente modificar este resultado usando una función de activación no lineal. Esta neurona es el bloque fundamental de toda red neuronal.
Veamos ahora cuál es la utilidad de las neuronas y cuáles son sus limitaciones.
¿Para qué se usan y cuáles son las limitaciones de las neuronas artificiales?
Las principales aplicaciones de las neuronas artificiales son la Regresión Logística y la Regresión Multiclase, y por supuesto las Redes Neuronales de las cuales hablaremos en detalle más adelante. En estos casos se busca clasificar una serie de datos en dos o más categorías.
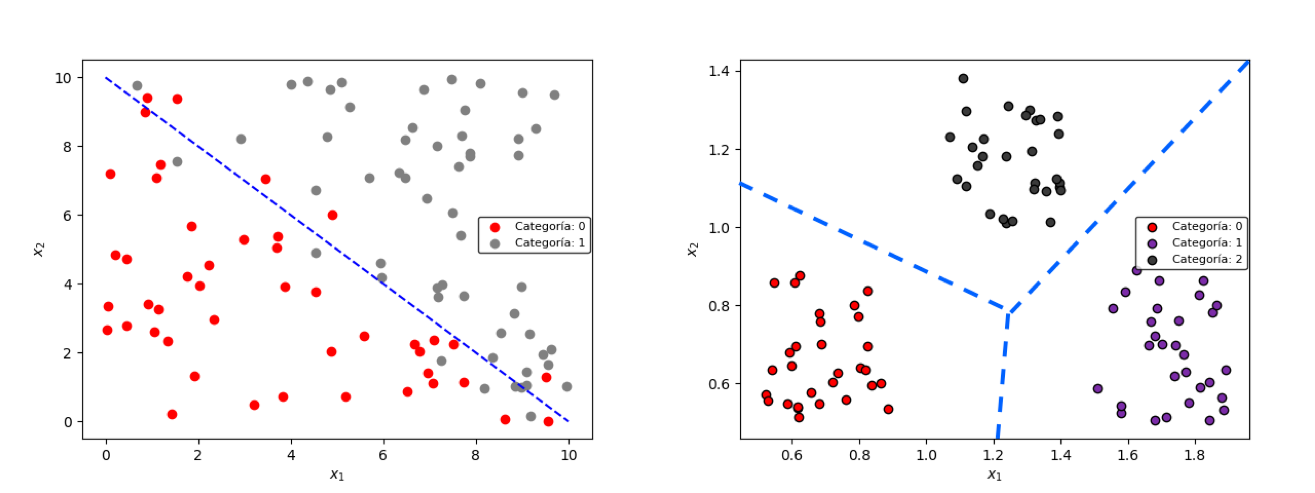
Esta clasificación será adecuada cuando las categorías se puedan separar fácilmente a través de una línea recta. Si los datos no son linealmente separables, como en la figura de abajo, la clasificación con una simple neurona no resulta adecuada:
Para lograr clasificar datos como los de la figura anterior, se requiere la interconexión de múltiples neuronas.
A continuación veremos en qué consiste esta interconexión.
La Red Neuronal Artificial
Una Red Neuronal Artificial es el resultado de interconectar múltiples neuronas, como se muestra en la figura:
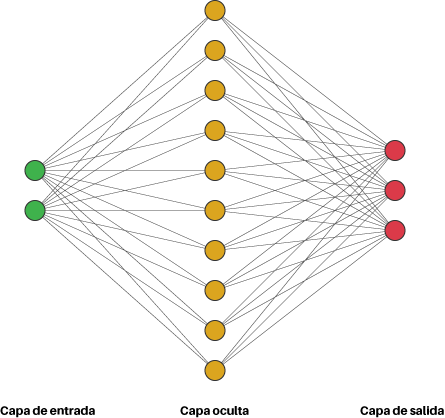
Vemos que esta Red Neuronal simple tiene una capa de entrada, una capa de salida y en medio una capa oculta.
La ventaja de realizar esta interconexión de neuronas es que permite la clasificación de datos que no son linealmente separables. Esto se muestra a continuación:
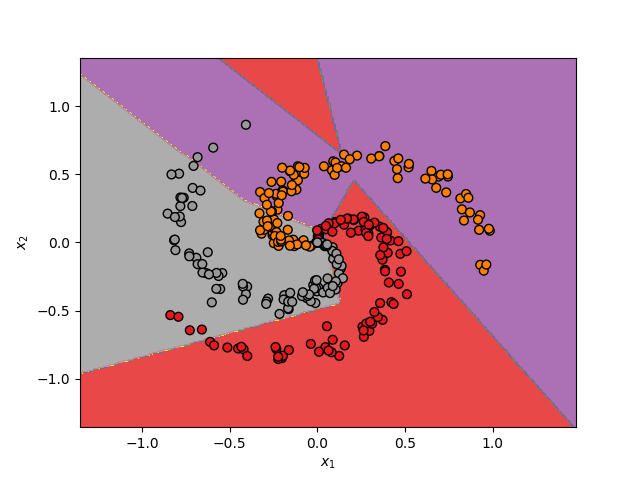
Sin embargo, podemos observar en la figura anterior que la clasificación ha mejorado (pasando de 55 % con una sola neurona a 70% con la red neuronal) pero aún no es muy buena.
La pregunta es entonces: ¿cómo mejorar la clasificación de estos datos? La respuesta está dada por las Redes Neuronales Profundas, discutidas a continuación.
La Red Neuronal Profunda
En la sección anterior vimos cómo si en lugar de tener una neurona usábamos una Red Neuronal con una capa oculta, entonces lográbamos tener mejores resultados en la clasificación.
Siguiendo la misma lógica, podemos decir que para lograr mejores resultados en la clasificación lo que debemos hacer es agregar más neuronas y capas ocultas a la red.
Al agregar más capas ocultas a la red podemos decir que la estamos haciendo más profunda, y de allí es de donde nace el término Red Neuronal Profunda.
Así, una Red Neuronal Profunda es simplemente una red neuronal con múltiples capas ocultas (generalmente más de tres), donde cada una de ellas tiene múltiples neuronas. En la figura de abajo se ilustra esta idea:
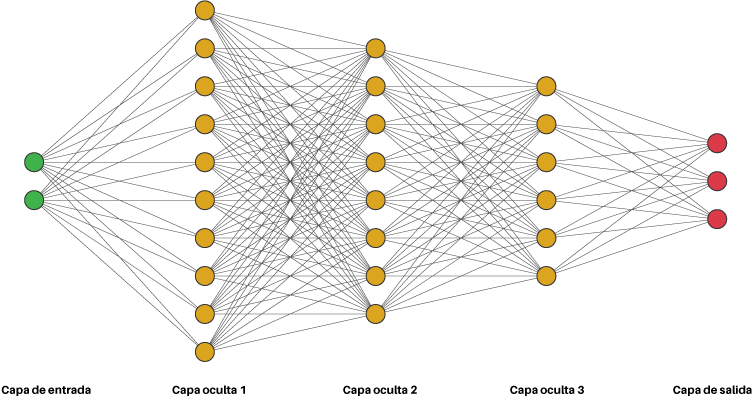
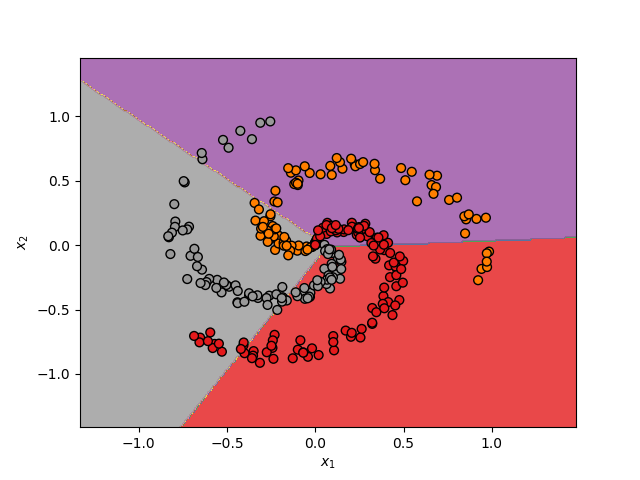
Así, al hacer más profunda la red logramos clasificar de una mejor forma los datos. Esto se muestra a continuación para el set de datos analizado anteriormente:
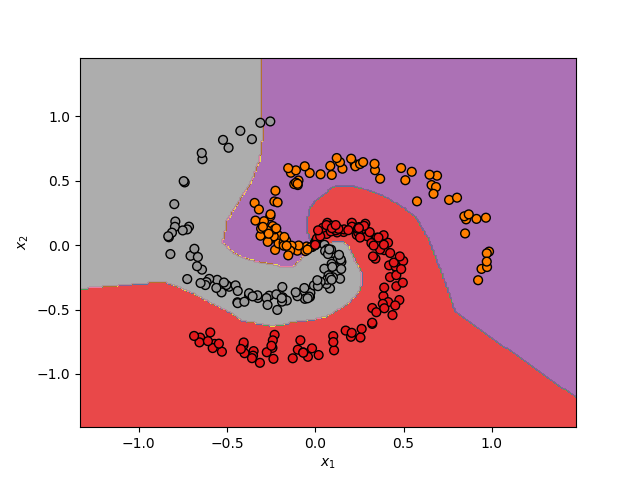
En este caso las fronteras de decisión se ajustan mucho mejor a los datos, logrando una precisión del 99%.
Hemos visto cómo hemos pasado de una precisión del 55% con una neurona, a una precisión del 70% con una red neuronal de una capa, y a un 99% con tres capas.
Es evidente que el hecho de agregar más neuronas y más capas ocultas a la red permite mejorar las prestaciones del clasificador. Pero, ¿por qué ocurre esto?
A continuación discutimos este comportamiento en detalle.
La Red Neuronal como aproximador universal de funciones
Recordemos que una neurona individual contiene una transformación y una función de activación no lineal. Al usar una neurona sencilla para realizar la regresión de una función o para clasificar, tendremos a disposición sólo un tipo de función: aquella definida por la función de activación.
Sin embargo, al conectar varias neuronas en una red y realizar el entrenamiento, cada una de las capas será el resultado de una combinación no lineal de las capas anteriores. Esto hace que a la salida de la red se tenga una función resultante de combinar los múltiples parámetros (w, b) de cada neurona individual junto con sus funciones de activación.
A esto se debe que en la práctica una red neuronal sea capaz de aproximar cualquier tipo de función matemática o de clasificar cualquier set de datos independientemente de su distribución. De hecho existe un teorema (conocido como el Teorema de la Aproximación Universal) que establece precisamente este principio.
Conclusiones
Hemos visto cómo la combinación de múltiples neuronas permite crear Redes Neuronales Profundas capaces de resolver complejos problemas de regresión o clasificación. Acá resumo los aspectos más importantes a tener en cuenta:
- Una neurona artificial lleva a cabo dos operaciones sobre los datos de entrada: transformación y aplicación de una función de activación.
- La característica más importante de la función de activación es su comportamiento no lineal.
- Una Red Neuronal el resultado de interconectar múltiples neuronas.
- Una Red Neuronal tiene tres tipos de capa: capa de entrada, capa(s) oculta(s) y capa de salida.
- Cuando la Red Neuronal tiene varias capas ocultas (generalmente más de tres) se conoce como Red Neuronal Profunda.
- La gran ventaja de una Red Neuronal Profunda frente a la Red Neuronal convencional o a la simple neurona artificial, es su capacidad de ajustarse a los datos de entrada independientemente de su comportamiento o distribución.
- Lo anterior se debe a la interconexión de neuronas individuales, al proceso de entrenamiento y al uso de funciones de activación no lineales.
- Es por esto que las redes neuronales funcionan como funciones de aproximación universal.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: