La Matriz de Confusión
En este artículo veremos qué es, cómo construir y cómo interpretar la matriz de confusión, una herramienta muy útil en la medición del desempeño de modelos de Machine Learning.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
Cuando resolvemos un problema de clasificación con Machine Learning muchas veces nos enfrentamos a la decisión de determinar cuál de los múltiples modelos entrenados es el más adecuado.
Y comúnmente la métrica más usada es la exactitud (o accuracy en Inglés), que es la proporción entre los datos clasificados correctamente y la cantidad total de datos. Sin embargo en muchas ocasiones esta métrica no es un fiel reflejo del desempeño del modelo.
Así que en este artículo hablaremos de la Matriz de Confusión, una herramienta muy útil en la medición del desempeño de modelos de Machine Learning.
¿Para qué medir el desempeño de un modelo?
Supongamos que queremos crear un modelo capaz de determinar si un sujeto tiene o no una enfermedad cardiaca a partir del análisis de su electrocardiograma. Así, el modelo clasificará el dato como “Normal” o “Anormal”.
Y supongamos que para resolver este problema entrenamos varios modelos: una Red Neuronal, un Bosque Aleatorio, una Red Convolucional y una Máquina de Soporte Vectorial.
Pero entonces ¿Cómo sabemos cuál es el mejor clasificador?
Para responder a esta pregunta necesitamos alguna herramienta que nos permita cuantificar este desempeño. Así, podemos aplicar esta herramienta a cada modelo y luego realizar una comparación objetiva para escoger el mejor clasificador.
Una de las métricas más usadas en estos casos es la exactitud que es simplemente la proporción entre el número de aciertos del clasificador y la cantidad total de datos.
Si por ejemplo entrenamos la Red Neuronal y luego la validamos con un set de 10 pacientes y encontramos que 8 de ellos han sido clasificados correctamente, podemos decir que el modelo tiene una exactitud del 80%.
Y si repetimos este procedimiento con los otros 3 modelos y encontramos que, por ejemplo, tienen exactitudes del 90% (para el Bosque Aleatorio), 70% (para la Máquina de Soporte Vectorial) y 60% (para la Red Convolucional), podríamos entonces concluir que el Bosque Aleatorio es el más adecuado para este problema, porque simplemente tiene un mayor número de aciertos (es decir una mayor exactitud).
Hasta acá no hay ningún inconveniente. La exactitud parece ser la métrica adecuada, pero tiene una gran limitación.
Limitaciones de la exactitud
En el ejemplo anterior hemos asumido una condición ideal: los sets de entrenamiento y prueba estaban balanceados, es decir que tenían prácticamente la misma proporción de “normales” y “anormales”.
Pero en la práctica no siempre podremos tener sets de datos balanceados. Por ejemplo en un sistema anti-spam generalmente habrá más correos “normales” que “spam” o en un sistema de detección de fraudes en transacciones bancarias, generalmente habrá más transacciones normales que fraudulentas.
Así que muchas veces los sets de datos estarán desbalanceados, es decir con más datos de una categoría que de otra.
Y si entrenamos nuestro modelo con este set de datos tendrá un sesgo, es decir que muy probablemente clasificará mejor la categoría con más datos y no lo hará tan bien con la otra categoría. Y si luego validamos este modelo y calculamos su exactitud no tendremos una estimación precisa de su desempeño.
Para entender esto volvamos al caso de los cuatro modelos y supongamos que ahora los entrenamos y validamos con sets desbalanceados. En el caso del set de prueba tendremos 100 datos: 90 “normales” y tan sólo 10 “anormales”.
Al clasificar estos datos con, por ejemplo el bosque aleatorio, encontramos que 89 de los 90 normales fueron clasificados correctamente, mientras que en el caso de los anormales tan sólo hubo un acierto.
Si calculamos el desempeño obtendremos una exactitud del 90%, lo que nos llevaría a concluir de manera errónea que en el 90% de los casos nuestro modelo realiza una clasificación correcta.
Pero si miramos con detalle este resultado encontraremos que la exactitud está enmascarando el comportamiento real del modelo, pues la proporción de “normales” y “anormales” clasificados correctamente no es la misma: en el primer caso tendremos 89 de 90 aciertos, mientras que en el ¡segundo tan sólo 1 de 10!. Así que en realidad el modelo lo está haciendo muy bien con los normales pero tremendamente mal con los anormales.
En conclusión podemos decir que la exactitud no es la forma más adecuada de medir el desempeño cuando tenemos sets de datos desbalanceados, así que tenemos que buscar otra alternativa. Y una manera de hacerlo es precisamente usando la matriz de confusión.
¿Qué es la Matriz de Confusión?
Como vimos en el ejemplo anterior no basta con estimar simplemente el número de aciertos, pues debemos ser capaces de diferenciar el desempeño entre una categoría y la otra. Y la matriz de confusión nos permite precisamente lograr esto.
Esta matriz de confusión es simplemente una tabla que nos permite ver qué tan “confundido” está nuestro modelo al momento de la clasificación, mostrándonos tanto los aciertos como desaciertos cometidos para cada una de las categorías:
¿Cómo construir la Matriz de Confusión?
Para entender cómo construir esta matriz debemos tener claros cuatro conceptos básicos: los verdaderos y falsos positivos y los verdaderos y falsos negativos.
Volvamos al caso del clasificador de enfermedades cardiacas y supongamos que nos interesa usarlo para detectar casos “normales”. A estos casos les asignaremos la etiqueta “positivo” y a los “anormales” la etiqueta “negativo”. Entonces al momento de la clasificación se podrán presentar estas situaciones:
- Un dato “normal” es clasificado correctamente como “normal”. A esto lo llamaremos verdadero positivo
- Un dato “normal” es clasificado incorrectamente como “anormal”. A esto lo llamaremos un falso negativo (porque realmente no es un caso negativo)
- Un dato “anormal” es clasificado correctamente como “anormal”. A esto lo llamaremos un verdadero negativo
- Y un dato “anormal” es clasificado incorrectamente como “normal”. A esto lo llamaremos un falso positivo (porque realmente no es un caso positivo).
Es decir que los verdaderos positivos y los verdaderos negativos serán simplemente los aciertos, mientras que los falsos positivos y los falsos negativos serán los desaciertos.
Y con estas definiciones ya estamos listos para construir nuestra matriz de confusión.
Para construir la matriz de confusión seguimos estos pasos:
Primero tomamos el set de prueba y lo clasificamos con el modelo entrenado y realizamos el conteo de los aciertos y desaciertos por cada categoría.
Luego organizamos este conteo de aciertos y desaciertos en una tabla donde:
- Las columnas representan las categorías a las que realmente pertenece cada dato
- Y las filas representan las categorías predichas por el modelo
Y por último ubicamos los aciertos y desaciertos en la celda correspondiente. Así, la primera celda contendrá la cantidad de “normales” que fueron clasificados como “normales”, la segunda la cantidad de “normales” clasificados como “anormales, la tercera la cantidad de “anormales” clasificados como “normales” y la cuarta la cantidad de “anormales” clasificados como “anormales”:

Y podemos ver que esta matriz de confusión será de 2x2 porque tenemos precisamente 2 categorías. Además, en la diagonal principal tendremos los aciertos (verdaderos positivos y verdaderos negativos) y en las celdas restantes la cantidad de desaciertos (falsos positivos y falsos negativos).
Con la matriz de confusión ya construida podemos ver en detalle el desempeño del modelo para las diferentes categorías y acá resulta evidente que lo hace mucho mejor para los datos normales y que lo hace muy mal con los anormales.
Y si repetimos este proceso para los modelos restantes podremos determinar cuál es el más adecuado: simplemente seleccionaremos aquel que tenga el mayor numero de aciertos para cada una de las dos categorías (es decir el que tenga los valores más altos en la diagonal principal de su correspondiente Matriz de Confusión).
La Matriz de Confusión para la clasificación multiclase
Y podemos extender esta idea de la matriz de confusión de la clasificación binaria para casos en los cuales tengamos más de dos categorías.
Volvamos a nuestro ejemplo y supongamos que en lugar de dos tendremos ahora cinco categorías: una para los sujetos normales y 4 para los “anormales” (“anormal tipo 1”, “anormal tipo 2”, “anormal tipo 3” y “anormal tipo 4”).
En este caso ya no podremos hablar de “positivos” y “negativos” pues hay más de dos categorías. Así que simplemente hablaremos de “aciertos” y “desaciertos”.
Entonces, al construir la matriz obtendremos un arreglo de 5x5 (pues tenemos 5 categorías) y en la diagonal principal tendremos el conteo de aciertos, mientras que por fuera de ella estarán los desaciertos o clasificaciones erróneas:
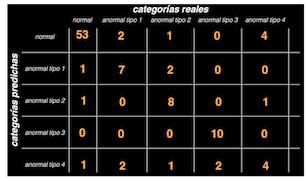
Por ejemplo, la celda de la fila 3 columna 1 nos indica la cantidad de sujetos anormales tipo 2 que fueron clasificados incorrectamente como “normales”, mientras que la fila 4 columna 4 nos indica cuántos sujetos “anormales” tipo 3 fueron clasificados correctamente en esta categoría.
Limitaciones de la Matriz de Confusión
Muy bien, ya sabemos cómo construir una matriz de confusión para un modelo de clasificación binaria o multiclase, con lo cual podremos determinar cuál es el modelo con el mejor desempeño para el problema que estemos resolviendo.
Pero en ocasiones no resulta fácil determinar las ventajas de uno u otro modelo tan sólo con la información proporcionada por esta matriz.
Por ejemplo volvamos al caso de la clasificación binaria y supongamos que obtenemos las matrices de confusión para tres modelos diferentes. Al comparar las matrices es evidente que el modelo 2 tiene el peor desempeño, pero no resulta fácil determinar cuál de los modelos restantes es el mejor, si el 1 o el 3: el modelo 1 tiene una mayor tasa de verdaderos positivos, mientras que el 3 tiene una mayor tasa de verdaderos negativos:
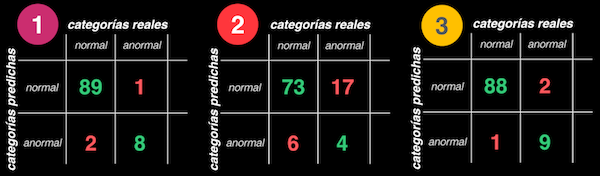
En este caso la decisión de cuál es el mejor modelo dependerá por un lado del uso final que esperemos darle (es decir si lo que nos interesa es la detección de casos normales o anormales) pero además de esto tendremos que recurrir a métricas adicionales que nos permitan escoger el mejor modelo de manera objetiva. De estas métricas, que se pueden calcular precisamente a partir de la matriz de confusión, hablaremos en detalle en un próximo artículo.
Conclusión
Muy bien, acabamos de ver qué es y cómo usar la Matriz de Confusión para comparar el desempeño de diferentes modelos de Machine Learning y determinar cuál es el más adecuado para la aplicación que estemos desarrollando.
Sin embargo vimos que es difícil diferenciar un modelo de otro cuando se tienen tasas de aciertos y desaciertos similares, así que serán necesarias métricas de desempeño como el “precision” o el “recall” de las cuales hablaremos en detalle en el próximo artículo.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: