¿Qué son las Redes Convolucionales?
En este primer post de la serie “Redes Convolucionales” veremos una introducción a esta importante arquitectura del Deep Learning. Hablaremos de su principio de funcionamiento y de cómo éstas permiten extraer patrones de imágenes y videos imitando el funcionamiento del cerebro humano. También analizaremos la estructura de una Red Convolucional, y discutiremos algunas de sus aplicaciones.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Las Redes Convolucionales: intuición
¿Cuál es la idea central de estas Redes Convolucionales?
Pues bien, al igual que con las Redes Neuronales, las Redes Convolucionales también permiten detectar patrones en los datos de entrada, con la única diferencia de que en el caso de las Redes Convolucionales los datos de entrada son imágenes.
En este caso vemos la imagen de una fruta que es procesada por una Red Convolucional. En esta red se entrenan diferentes filtros (o kernels) y esos filtros permiten extraer características de esa imagen y posteriormente realizar la clasificación en una de diferentes categorías:
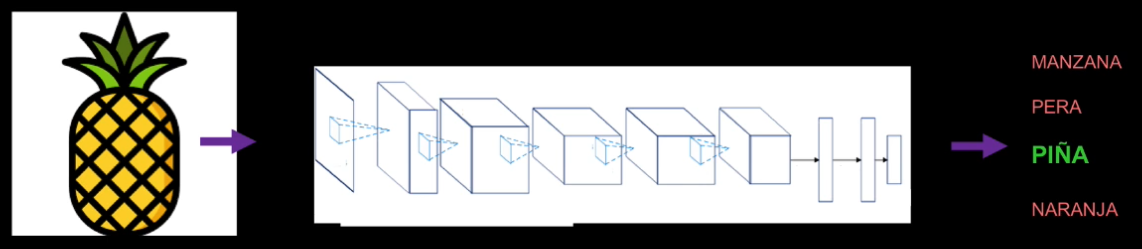
Pero ¿cómo logran hacer esto las Redes Convolucionales? Pués básicamente lo que hacen es imitar el cerebro humano y la forma como este procesa las imágenes a través de la corteza visual.
Aquí vemos por ejemplo que la corteza visual, ubicada en la parte trasera de nuestro cerebro, tiene diferentes regiones y diferentes grupos de neuronas encargados de varias funciones:
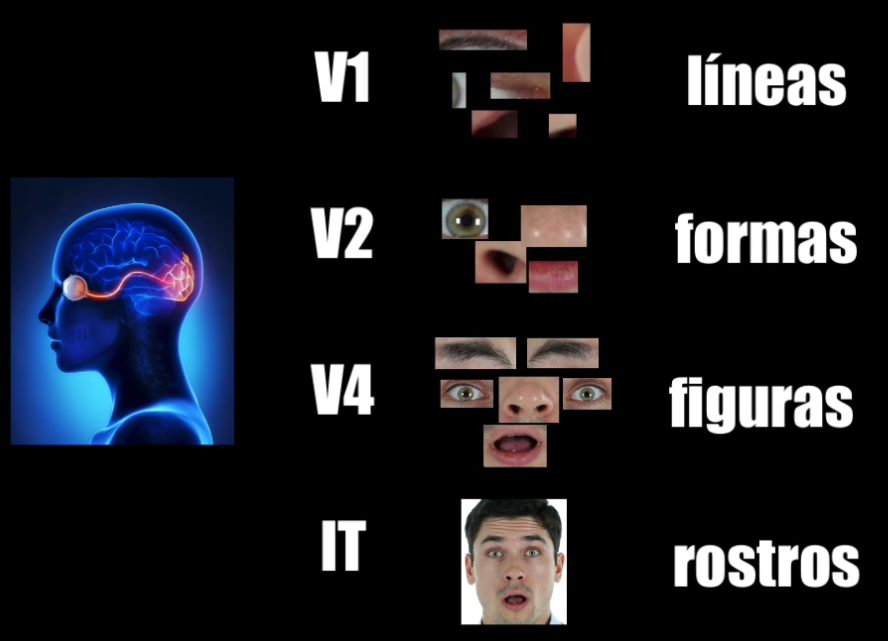
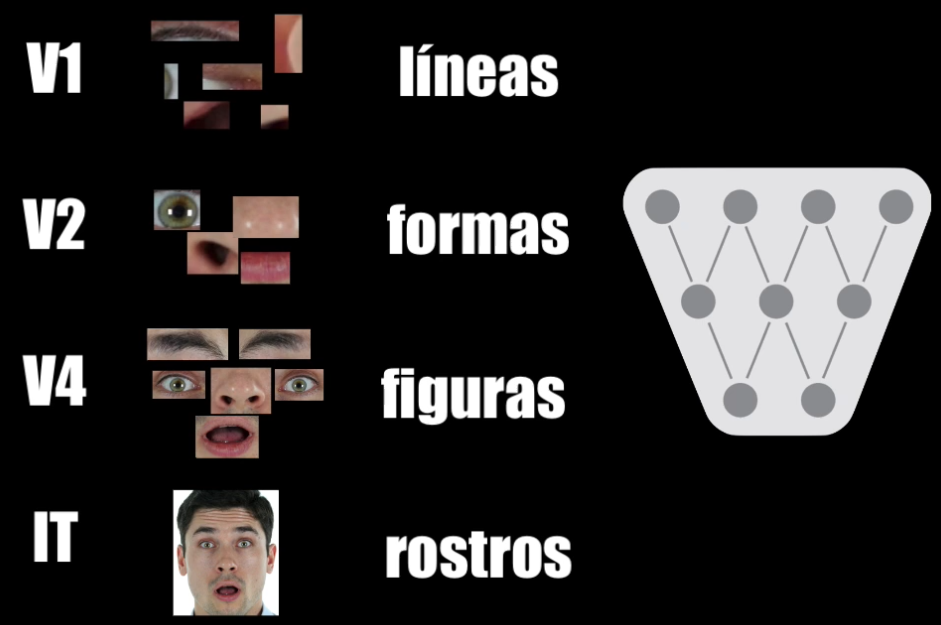
Por ejemplo las neuronas de la capa “V1” están especializadas en detectar patrones muy simples, como líneas o bordes. Posteriormente esa información pasa a la capa “V2”, una capa más compleja y especializada, que es capaz de interconectar esos elementos y de detectar diferentes formas. Y poco a poco las capas se van especializando más y más, tomando la información de las capaz anteriores hasta que se logran detectar características o elementos más complejos dentro de ese objeto que estamos observando.
En la capa “V4” del cerebro las neuronas se especializan en detectar ojos, narices, cejas y boca. Y ya en la región inferior temporal se combina la información proveniente de las capas anteriores y es posible determinar que estos elementos corresponden precisamente a un rostro.
Pues bien, las Redes Convolucionales hacen una tarea similar a la del cerebro humano al momento de procesar una imagen. A la entrada se tiene una imagen en formato digital, obviamente, y las primeras capas de esa Red Convolucional extraen patrones básicos, como líneas y bordes, y poco a poco, a medida que vamos más profundo en esa Red Convolucional, estos elementos básicos se van combinando en formas y en figuras cada vez más complejas hasta que al final la red es capaz de detectar un rostro o capaz de determinar a qué persona corresponde ese rostro que aparece en la imagen.
El principio de funcionamiento de una Red Convolucional
Para entender cómo es que logra hacer esto una Red Convolucional, primero tenemos que entender o recordar cómo es que se representa digitalmente una imagen.
Abajo vemos un ejemplo de una imagen, que para el caso particular contiene el número 8. En el computador esta imagen es representada como una matriz con valores desde 0 hasta 255, correspondientes a cada uno de los pixeles:

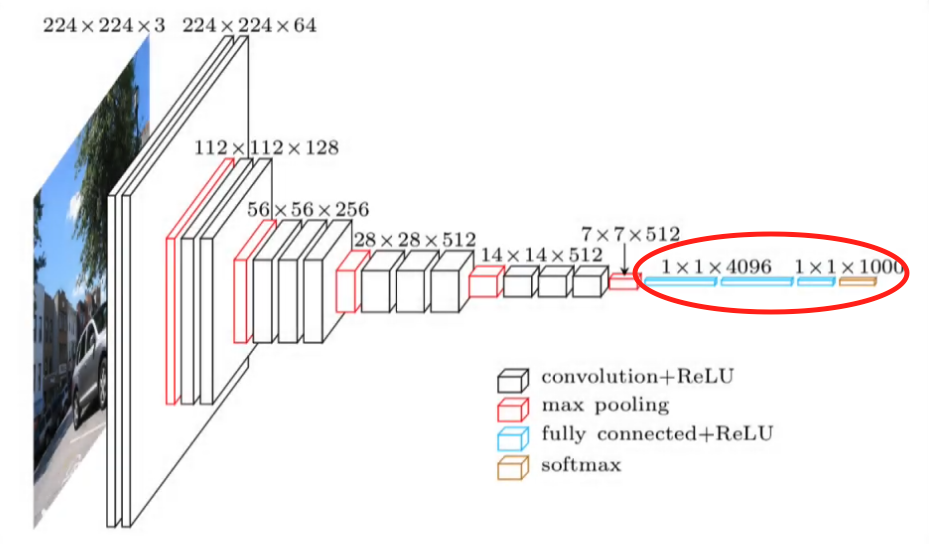
Pues la Red Convolucional toma este dato digital de entrada y, progresivamente, a través del entrenamiento de múltiples capas convolucionales (conformadas por filtros que realizan diferentes operaciones sobre la imagen) se extraen progresivamente características cada vez más complejas de la imagen para lograr su reconocimiento:
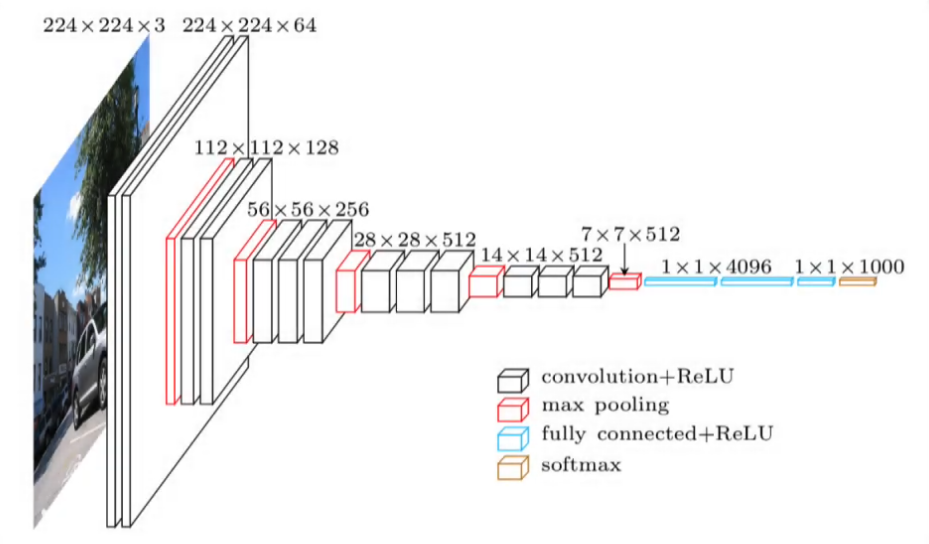
Así, cuando la imagen es procesada por la red cada bloque de filtros se encargará de extraer diferentes características. En las primeras capas algunos de ellos se encargarán por ejemplo de detectar tonalidades azules, otros de tonalidades verdes, otros por ejemplo podrán detectar líneas rectas y otros podrán detectar tonalidades oscuras.
Posteriormente, la salida de esos filtros se lleva a unas capas más profundas, las que aparecen en color rojo en la imagen anterior, que se llaman max-pooling y que permiten reducir la cantidad de datos, la cantidad de información, y extraer así los datos más representativos de los filtros que se utilizaron anteriormente.
Luego, a medida que vamos más profundo en la red, se repiten estos procedimientos (filtrado y max pooling) y cada vez el tamaño de las imágenes resultantes va siendo más pequeño y la cantidad de filtros usados se va incrementando.
Así, inicialmente se usan 64 filtros, luego 128 y luego 256. Es decir que a medida que nos vamos más profundo en la red estamos extrayendo más y más características de esa imagen de entrada, siendo cada vez más complejas hasta que resulta posible combinarlas en formas que permiten determinar el objeto que se está intentando clasificar.
Generalmente en la etapa final de la Red Convolucional lo que tenemos es una Red Neuronal convencional, con pocas capas, que permite tomar las características extraídas por las capas convolucionales, representarlas como un vector de datos y realizar la clasificación final de la imagen, usando para esto una función “softmax” o sigmoidal.
La importancia de los filtros
El éxito de las Redes Convolucionales radica precisamente en los filtros (o kernels) que estamos usando en cada capa y que permiten extraer diferentes características de la imagen.
Veamos un ejemplo para entender un poco mejor esta idea. En la imagen de abajo se ve del lado izquierdo una imagen sencilla en blanco y negro, que contiene líneas verticales, horizontales y diagonales. Al centro tenemos una versión sencilla de lo que es un filtro o “kernel”:
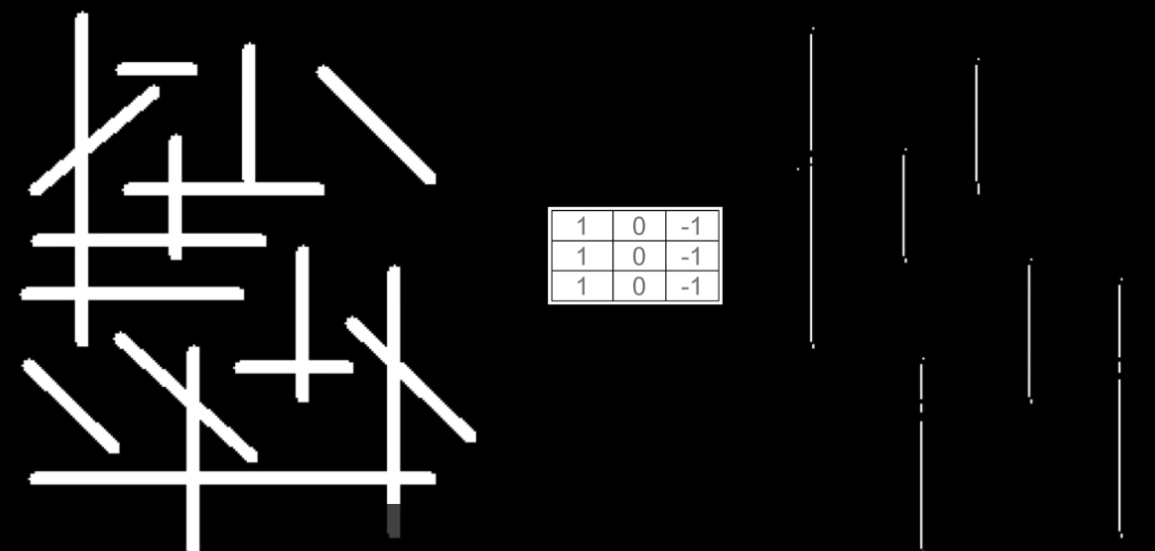
El filtro consiste simplemente en una matriz, con una serie de coeficientes numéricos, y la idea es que ese filtro realiza un barrido a través de la imagen usando una operación matemátiva llamada precisamente convolución. Dependiendo de los coeficientes que tenga el filtro, tras esta convolución será posible detectar algunas características de la imagen de entrada.
Para este ejemplo en particular el filtro tiene una orientación vertical: los coeficientes están organizados por columnas. Cuando aplicamos ese filtro a la imagen original (a la izquierda) obtenemos una imagen como la mostrada en el lado derecho de la figura anterior.
En este caso lo que ha hecho el filtro es detectar un patrón muy básico en la imagen de entrada: la presencia o la ausencia de líneas verticales. Y este resultado se debe precisamente a la forma como están configurados los coeficientes del filtro.
El entrenamiento
Lo interesante de las Redes Convolucionales es que ¡no es necesario diseñar manualmente cada uno de los filtros a utilizar! En su lugar, durante el entrenamiento, la misma red “aprende” de forma automática, y con la ayuda de una gran cantidad de imágenes de entrenamiento, a ajustar iterativamente estos coeficientes para progresivamente ir detectando características cada vez más complejas en el proceso de entrada.
Para entender esto veamos la figura de abajo, en donde podemos observar las características extraídas por los filtros de las diferentes capas de una Red Convolucional:

En la capa de entrada (a la izquierda) observamos patrones muy básicos: líneas diagonales y unas ciertas tonalidades (fucsia, verde, azul y amarillo). Al analizar la segunda capa vemos que las figuras som más complejas: hay círculos, semi-círculos, líneas, esquinas, y curvas, por ejemplo. Es decir que las características que se van detectando cada vez son más complejas.
Si vamos más profundo en de la red pues veremos que en las capas más profundas los patrones que se detectan son mucho más complejos. Y todo esto es el resultado del entrenamiento, es decir es el resultado mostrarle a la Red Convolucional muchísimas pero muchísimas imágenes (¡cientos de miles!) durante el este entrenamiento.
El potencial de las Redes Convolucionales y algunas aplicaciones
Para finalizar, veamos sólo algunos ejemplos del potencial grandísimo que tiene este tipo de arquitectura, las Redes Convolucionales, en el análisis de diferentes tipos de imágenes o videos.
Acá vemos una aplicación conocida como DeepGlint, que permite detectar automáticamente las personas que aparecen en secuencias de video de cámaras de vigilancia, y clasificarlas dependiendo de la actitud o el comportamiento que el sistema observa en esas personas.
Otra aplicación es la detección de objetos en tiempo real, usando el algoritmo YOLO (You Only Look Once), que permite clasificar diferentes objetos en una secuencia de video y prácticamente en tiempo real:
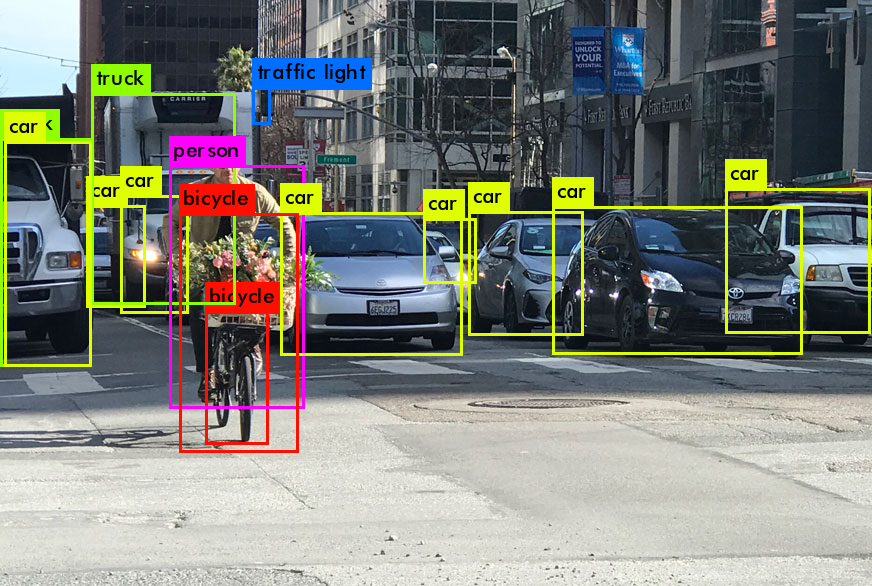
Y finalmente tenemos los vehículos autónomos, que son otro ejemplo de la detección de objetos en tiempo real pero en este caso aplicado a los sistemas que permiten guiar de forma automática un automóvil:
Conclusión
Bien, en este post vimos una introducción general a las Redes Convolucionales. Vimos que esta arquitectura permite emular el funcionamiento del cerebro humano, logrando, a través del entrenamiento de múltiples filtros, detectar patrones o extraer características relevantes en las imágenes. Esto ha permitido que las Redes Convolucionales hayan generado una revolución grandísima en el campo de la visión por computador y el procesamiento de imágenes en los últimos años.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Te invito además a revisar los demás posts de esta serie: