Conceptos básicos del Deep Learning
En este post veremos varias definiciones básicas esenciales del Deep Learning, necesarias para comprender posteriormente cómo funcionan estos modelos.
En particular hablaremos de los tipos de datos (estructurados y no estructurados), las tareas (como la clasificación, la regresión, la transcripción y la detección de anomalías, entre otras), los conceptos de representación, aprendizaje y entrenamiento, así como las dos principales formas de llevar a cabo el aprendizaje en un modelo Deep Learning: el aprendizaje supervisado y el no supervisado.
Con estos elementos se tendrán las bases necesarias para entender la forma como funcionan y las principales características de las diferentes arquitecturas del Deep Learning, como las Redes Neuronales, las Convolucionales, las Recurrentes y las Transformer.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Datos estructurados y no estructurados
El principal insumo de un modelo Deep Learning son los datos, y estos pueden ser de dos tipos: estructurados o no estructurados.
Datos estructurados
Se caracterizan por estar organizados de forma tal que siempre siguen un patrón predeterminado. Por ejemplo, si se está desarrollando un modelo capaz de detectar correo spam entonces los datos de entrada pueden contener campos como e-mail de origen, hora de envío y el encabezado.
Otro ejemplo sería un modelo que busca generar un diagnóstico basado en el historial clínico de una persona. En este caso los datos de entrada podrían ser la edad y el sexo del paciente, antecedentes de enfermedades familiares, las cirugías a las que ha sido sometido, los resultados de exámenes médicos, el peso, la talla, etc.

Datos no estructurados
Estos datos no están organizados de forma alguna, y se caracterizan porque no siguen un patrón predeterminado, o al menos este patrón no es evidente a simple vista. Los ejemplos más representativos de este tipo de datos son el audio, las imágenes y los videos:

Tareas que puede llevar a cabo un modelo de Deep Learning
Otras de las definiciones básicas de un modelo de Deep Learning son las tareas que está en capacidad de llevar a cabo el modelo. Estas son algunas de ellas:
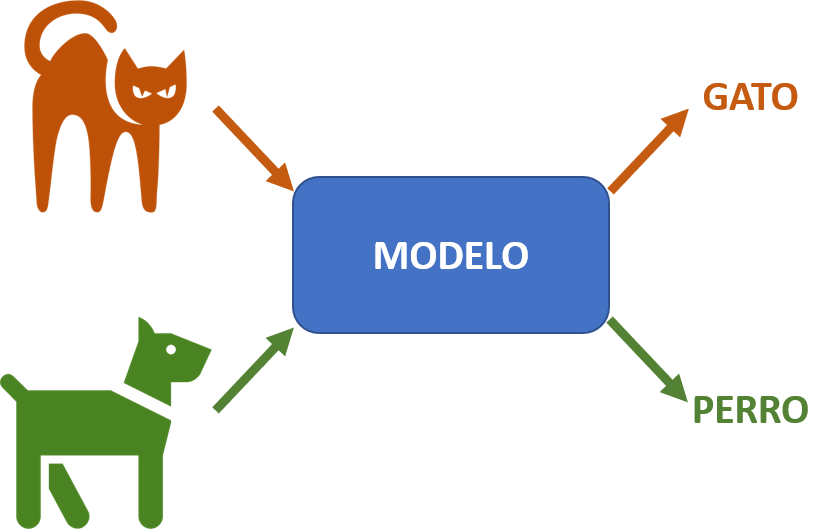
Clasificación
En este tipo de tarea el modelo se encarga de determinar si los datos de entrada corresponden a una de varias categorías (o clases) posibles.
Ejemplos de esto pueden ser: determinar si una persona padece o no una enfermedad, determinar si un correo es o no es spam, detectar obstáculos por parte de un vehículo autónomo.
Los clasificadores se caracterizan porque a la salida del modelo se obtienen valores discretos (0 o 1 para clasificación binaria, o 0, 1, 2, 3, etc… para clasificación multiclase).
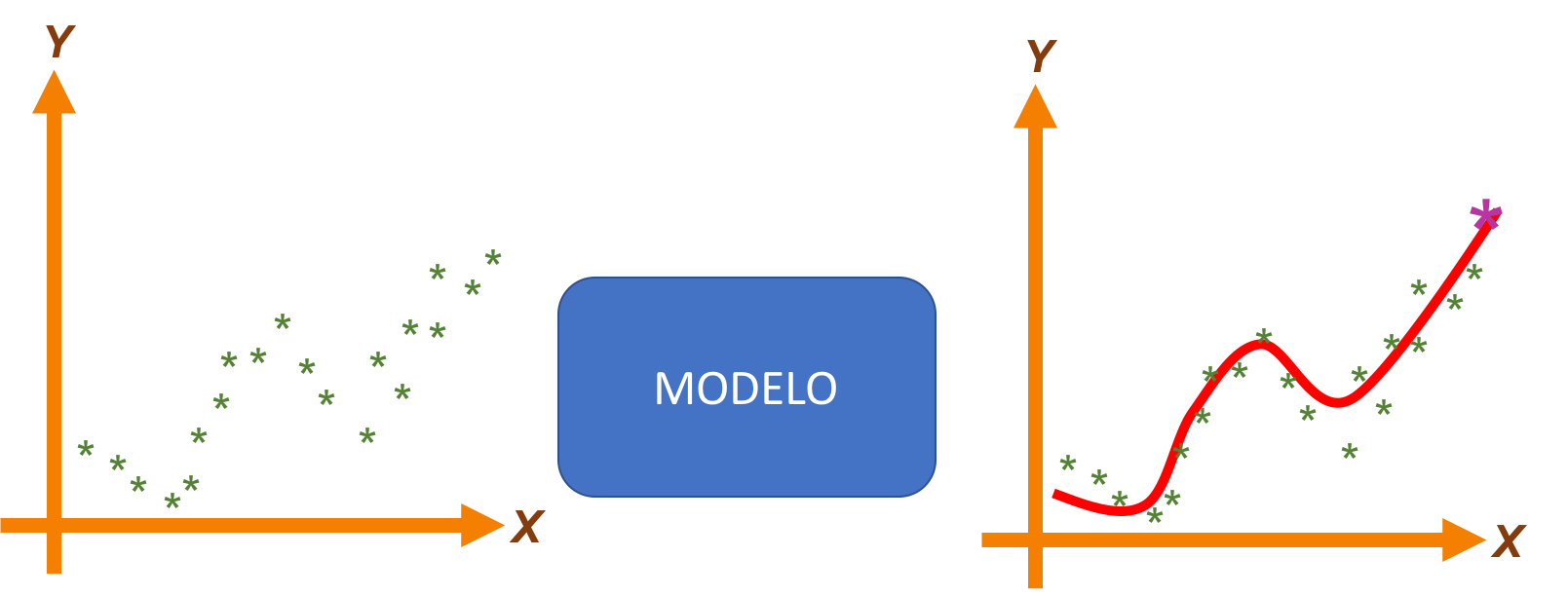
Regresión
En este tipo de tarea el modelo se encarga de establecer la relación existente entre dos variables para posteriormente predecir un valor numérico con base en los datos de entrada.
Ejemplos de esto pueden ser la predicción del valor de una acción en la bolsa con base en el comportamiento histórico de la misma; el precio de venta de una propiedad con base en su ubicación, su tamaño, el número de habitaciones y de baños, su antigüedad, etc.
Los sistemas de regresión se caracterizan porque a la salida generan valores contínuos.
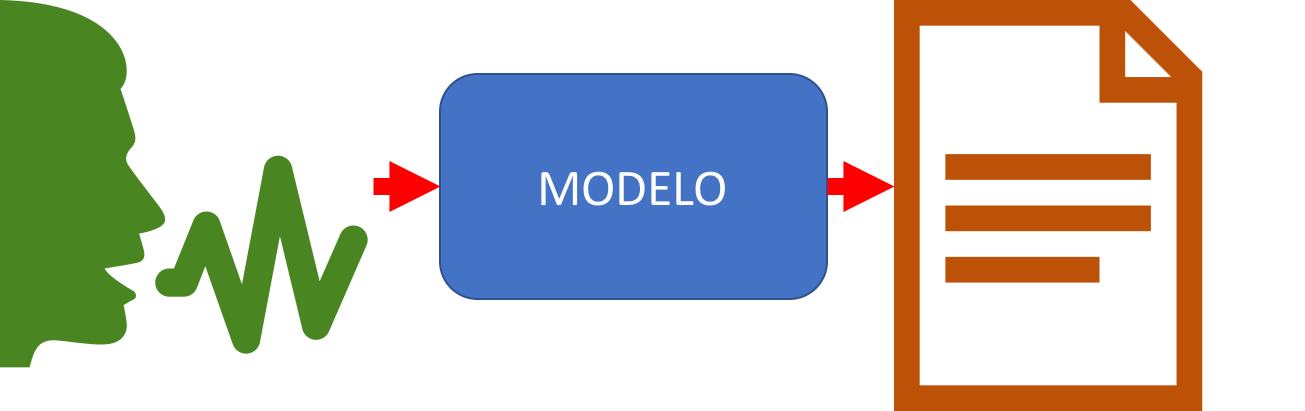
Transcripción
En este caso el modelo acepta como entrada datos no estructurados y genera una salida en forma de texto.
Ejemplos de esto son los sistemas de reconocimiento de voz (en donde ingresa una señal de audio y el modelo genera un texto con el contenido de la conversación) o los sistemas de reconocimiento de caracteres (en donde ingresa una imagen y el modelo genera un texto con el contenido de la imagen):
Traducción automática (Machine Translation)
En esta tarea los datos de entrada son secuencias de texto en un idioma y el modelo se encarga de transformarlos en otra secuencia de texto en otro idioma.
Un ejemplo muy conocido de esta aplicación es el traductor de Google, que usa la tecnología neural machine translation para realizar esta tarea.

Generación de datos estructurados
Corresponde a tareas en donde el modelo toma como entrada datos no estructurados (audio, imágenes, video) y genera a la salida una serie de datos estructurados.
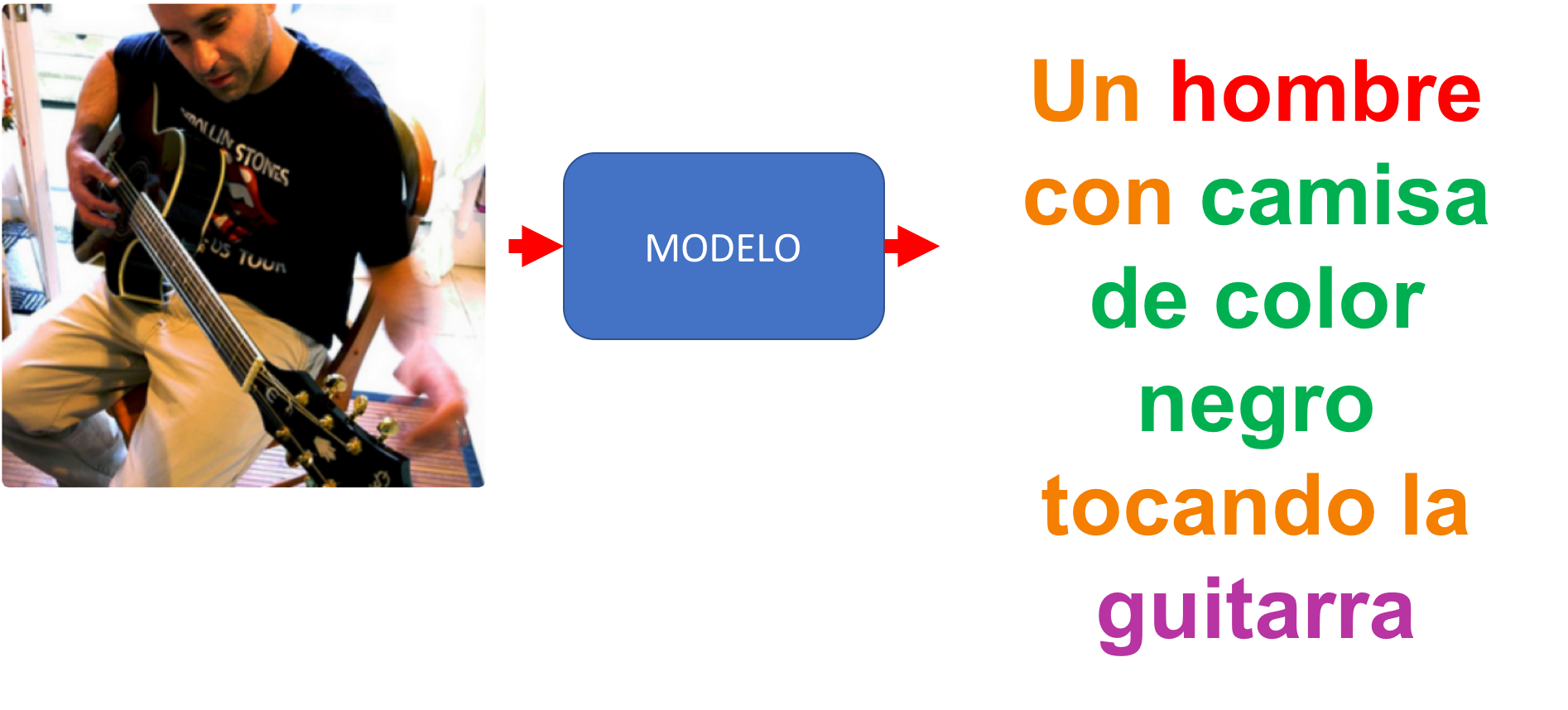
En este caso existen múltiples aplicaciones. Por ejemplo, el modelo puede tener a la entrada una conversación y a la salida generar la estructura gramatical de la misma (palabras, frases, verbos, sujetos, etc.), tecnología que se conoce como natural language processing (o procesamiento del lenguaje natural). Otro ejemplo es la tecnología de image captioning que permite de forma automática describir o etiquetar el contenido de una imagen (tal como lo hace Facebook cuando publicamos una foto):
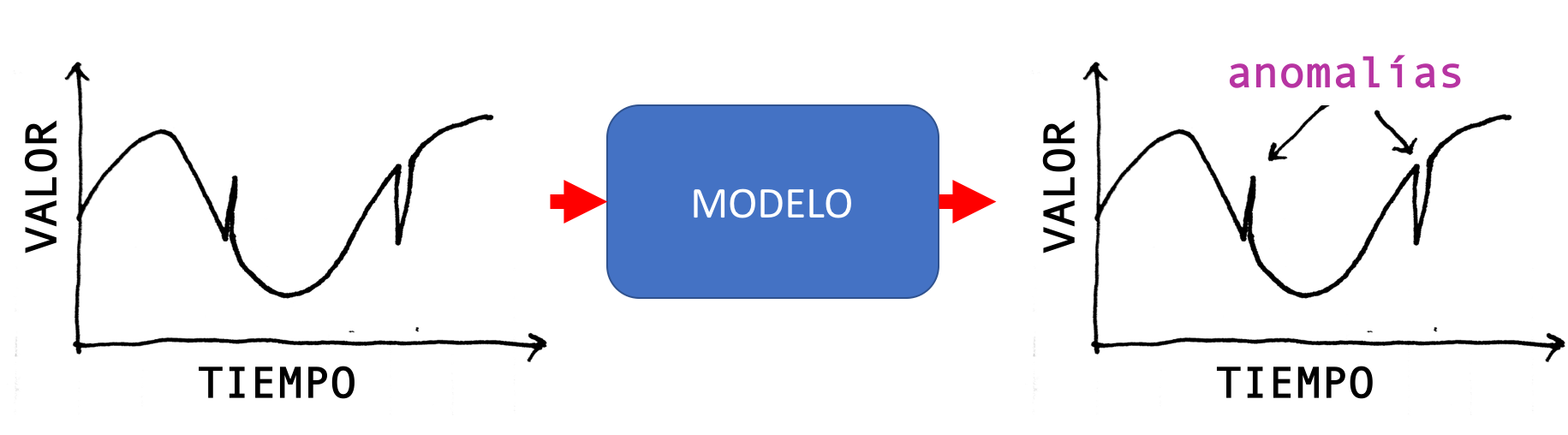
Detección de anomalías
En este caso el modelo se encarga de detectar patrones inusuales o atípicos presentes en los datos de entrada.
Un ejemplo de esto es la detección por parte de los bancos de los fraudes en el uso de las tarjetas de crédito. Otro ejemplo puede ser la detección de intrusos en redes computacionales, o la detección de tumores en imágenes médicas, entre otros:
Síntesis
En la síntesis se generan datos no estructurados (generalmente audio) a partir de datos de entrada que pueden ser estructurados o no estructurados.
El ejemplo más representativo de este tipo de tarea es la síntesis de la voz humana, en donde se introducen datos no estructurados en forma de texto, y el modelo se encarga de sintetizar a la salida el audio correspondiente. Un interesante ejemplo de esto es WaveNet de Google, que está en capacidad de generar señales sintetizadas que son muy similares a la voz humana.

Representación, aprendizaje y entrenamiento
Representación
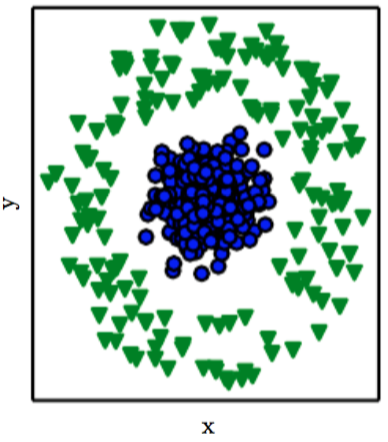
Corresponde a la forma como el modelo permite transformar los datos de entrada en los datos de salida.
Por ejemplo, en la figura de abajo, se tiene un problema de clasificación con dos categorías (objetos de color azul y de color verde). Si por ejemplo buscamos separar las dos categorías de la figura a través de una línea recta, veremos que por la forma como están representados estos datos resulta imposible:
Si ahora los datos originales son representados de una manera equivalente (usando otro sistema de coordenadas) podemos observar en la figura de abajo que resulta muy sencillo separar una categoría de la otra a través de una línea recta:
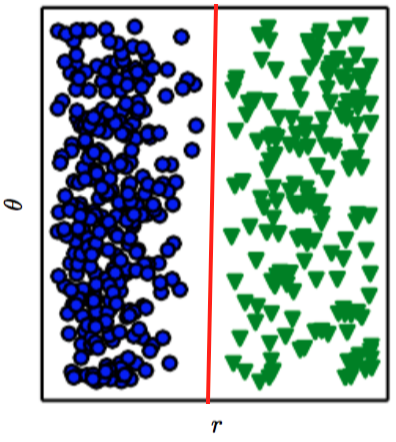
Así, un modelo Deep Learning permite encontrar una representación adecuada de los datos para posteriormente desarrollar la tarea para la cual fue diseñado el sistema (clasificación, regresión, transcripción, etc.).
Aprendizaje
Teniendo en cuenta lo descrito anteriormente, el aprendizaje se puede entender entonces como un procedimiento que permite calcular los parámetros del modelo que permiten encontrar la mejor representación que relacione los datos de salida con los de entrada.
Entrenamiento
Durante el entrenamiento, los parámetros del modelo se calculan y refinan de forma progresiva, para así aprender de forma autónoma la mejor representación que relacione los datos de entrada y de salida.
Para finalizar, veamos las definiciones básicas correspondientes al aprendizaje supervisado y el no supervisado.
Aprendizaje supervisado y no supervisado
Aprendizaje supervisado
En este tipo de aprendizaje, se introducen al sistema los datos de entrenamiento (a la entrada) así como las etiquetas o categorías a las que pertenece cada uno de esos datos de entrenamiento.
Así por ejemplo, si se está entrenando un modelo de Deep Learning para clasificar pacientes como enfermos o sanos, entonces por cada ejemplo de entrenamiento se introducen los datos de entrada al modelo (por ejemplo imágenes de resonancia de alguna parte del cuerpo) así como la categoría a la que pertenecen dichos datos (enfermo o sano).
El aprendizaje supervisado es entonces característico de tareas como la clasificación, regresión y la generación de datos estructurados.
Aprendizaje no supervisado
En este caso se introducen al sistema únicamente los datos de entrenamiento pero sin especificar las etiquetas o categorías a la salida. Así, el objetivo del modelo es determinar de forma autónoma los patrones y características presentes en los datos.
Un ejemplo de este aprendizaje no supervisado se muestra en el video de abajo, desarrollado por DeepMind de Google, consistente en un humanoide que fue entrenado usando datos provenientes de un sistema de captura de movimiento. Se observa que a medida que avanza el proceso de entrenamiento, el humanoide comienza a identificar los patrones del sistema de captura de movimiento, y de esta manera “aprende” a caminar, saltar y a escalar:
Conclusión
Las definiciones básicas presentadas en este post resultarán esenciales para entender más adelante la forma como se implementan diferentes modelos Deep Learning, como las Redes Neuronales, las Redes Convolucionales, las Redes Recurrentes y Redes LSTM y las Redes Transformer. También resultan de utilidad en áreas como el Aprendizaje Reforzado.
Estas fueron las ideas más importantes que acabamos de ver:
- Existen dos tipos de datos: estructurados (que poseen algún tipo de organización) y no estructurados (que carecen de un orden aparente).
- Un modelo Deep Learning puede llevar a cabo tareas como la clasificación, regresión, transcripción, traducción, síntesis, detección de anomalías y generación de datos estructurados.
- Una de las metas en el diseño de un modelo Deep Learning es lograr representar adecuadamente los datos de entrada en términos de la salida esperada, dependiendo de la aplicación.
- Para lograr encontrar la mejor representación se lleva a cabo un proceso de entrenamiento, que permite al modelo aprender de forma iterativa los coeficientes/parámetros para el cálculo de dicha representación.
- Finalmente, existen dos tipos de aprendizaje: supervisado y no supervisado.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: