Inteligencia Artificial vs. Machine Learning vs. Deep Learning
¿Qué diferencia hay entre la Inteligencia Artificial, el Machine Learning y el Deep Learning? En este post hablaremos en detalle de las características y las diferencias existentes entre estos tres campos del conocimiento.
La Inteligencia Artificial es un campo de las ciencias computacionales que ha tenido un gran auge en los últimos años, gracias al desarrollo de aplicaciones que en muchos casos emulan o incluso superan la habilidad humana para el desarrollo de ciertas tareas (como por ejemplo el reconocimiento de imágenes o el procesamiento de señales de voz).
Tradicionalmente ha sido el Machine Learning el área que ha tenido un continuo desarrollo pero sin lograr resultados sorprendentes. Sin embargo, durante la última década, ha sido el Deep Learning el campo que ha tenido un crecimiento vertiginoso y que ha demostrado tener el potencial de lograr un desempeño similar o superior al del ser humano en un gran ámbito de aplicaciones.
En el post hablaremos de cada una de estas definiciones y las semejanzas y diferencias entre estos tres campos.
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Definición del Deep Learning
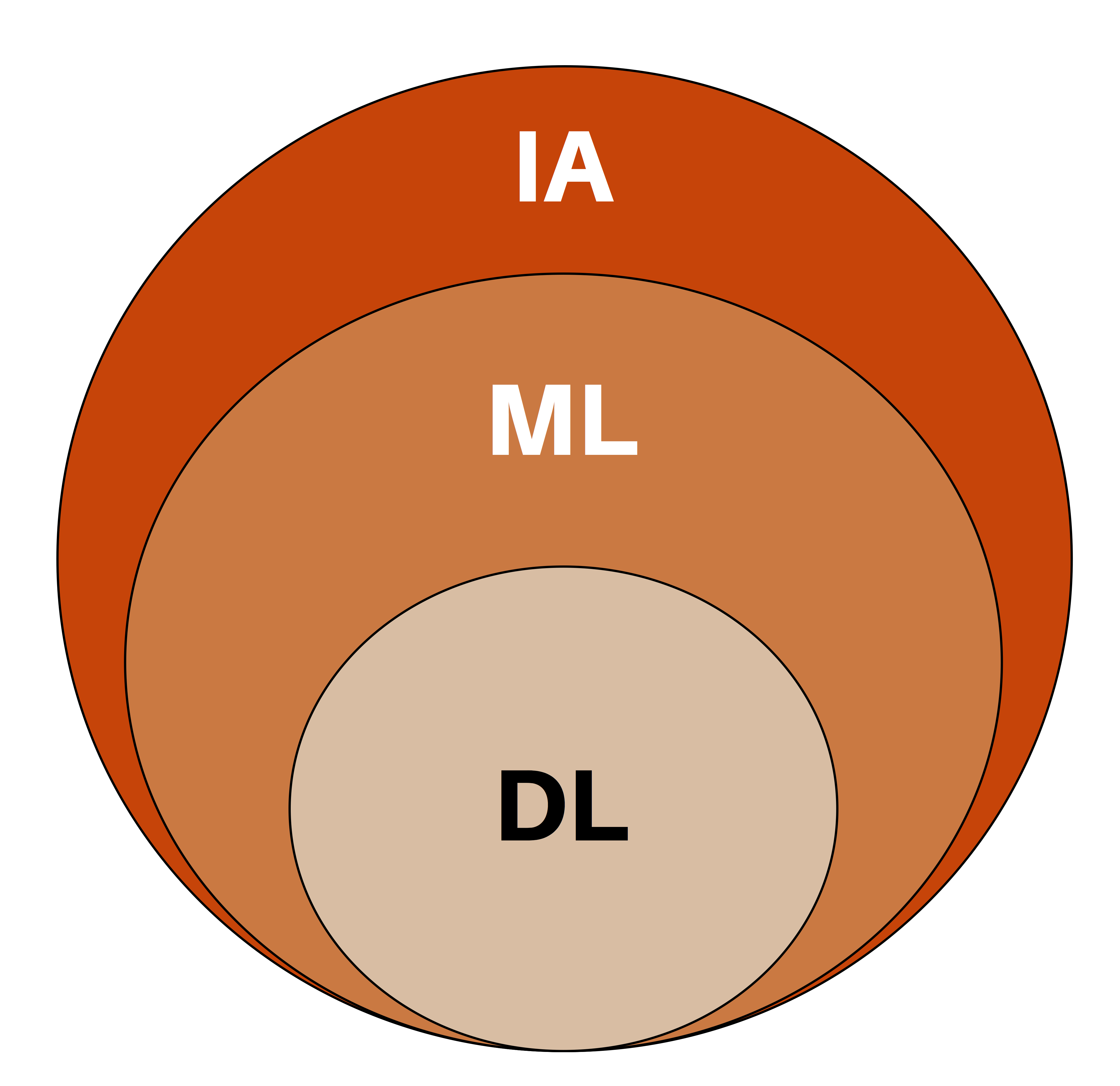
La inteligencia artificial es una disciplina que busca lograr que los computadores repliquen la inteligencia humana. Esto implica no solo la capacidad de realizar operaciones matemáticas o una gran cantidad de cálculos en muy poco tiempo, sino también la capacidad de interpretar el entorno, los sonidos, las imágenes, y en general todo lo que nos rodea, para así aprender y tomar decisiones a partir de estas experiencias.
Por su parte, el Machine Learning (o aprendizaje de máquina) es una sub-área de la inteligencia artificial, en donde se desarrollan algoritmos computacionales los cuales, haciendo uso de herramientas matemáticas, son capaces de interpretar datos, extrayendo de ellos algún tipo de información para luego tomar una decisión. Ejemplos de esto son algunas aplicaciones tecnológicas que usamos en nuestra vida diaria: la detección de correos spam, la detección de rostros o personas en un video o en una imagen, los sistemas de reconocimiento de voz usados por Google y Apple en sus aplicaciones móviles, entre otros.
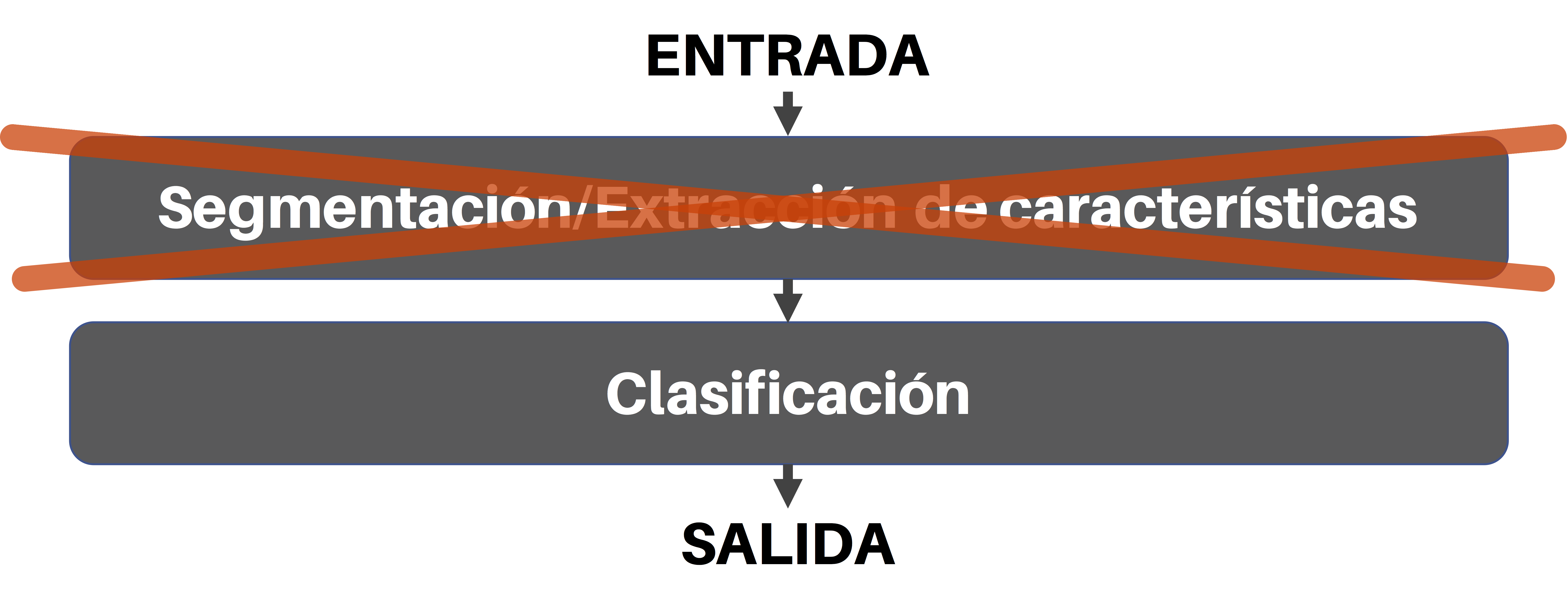
El Deep Learning es una disciplina inmersa en el Machine Learning. Sigue los mismos principios de este último, es decir se trata de algoritmos computacionales que permiten interpretar datos para tomar algún tipo de decisión. Sin embargo, la diferencia entre el uno y el otro radica en un elemento importante: en Deep Learning no se usa una etapa de extracción de características, lo cual quiere decir que los datos ingresan en bruto (sin ningún tipo de procesamiento previo) al algoritmo (en adelante lo llamaremos el modelo) y este, por sí solo, se encarga de extraer las características y los patrones más relevantes de los datos ingresados para, de forma autónoma, tomar una decisión.
Lo anterior se comprende más fácilmente con un ejemplo. Supongamos que queremos desarrollar una aplicación móvil que sea capaz de hacer un pedido a domicilio por nosotros; así, si queremos ordenar una pizza, la aplicación móvil se encargará de llamar al restaurante, hablará e interactuará con la persona que está al otro lado de la línea, hará el pedido con base en nuestras preferencias, y todo sin necesidad de que nosotros los seres humanos interactuemos en la conversación (de hecho está tecnología ya existe y se llama Google Duplex).
Para lograr este objetivo, la aplicación móvil debe estar en capacidad de interpretar el lenguaje (lo que la persona del otro lado de la línea está diciendo), y de mantener una conversación. En este caso, una aplicación convencional de Machine Learning haría lo siguiente:
- Capturar la señal de audio
- Segmentar dicha señal, detectando palabras individuales. Por ejemplo, en la frase “tenemos pizzas vegetarianas y con carne “, la aplicación detectaría primero la palabra “tenemos”, luego “pizzas”, luego “vegetarianas” y así sucesivamente.
- Una vez segmentadas las palabras individuales, el sistema extraerá las características más relevantes de estas palabras para posteriormente clasificarlas. Estas características se conocen como descriptores acústicos y son generalmente diseñadas por nosotros los humanos, buscando así representar cada palabra de la forma más adecuada para facilitar su clasificación. Estas características tienen en cuenta los fonemas (es decir los sonidos) de cada letra, y generalmente tratan de incorporar en su obtención el modelo de cómo los humanos interpretamos estos sonidos.
- Una vez segmentadas las palabras y extraídas sus características individuales, el sistema procede a clasificarlas (es decir, determina si lo que dijo la persona al otro lado de la línea fue “pizza” y no “pisa” o “pesa”) y a analizar la forma como las palabras están interrelacionadas y conforman la frase.
Por otro lado, en el caso de una aplicación Deep Learning no se requieren los pasos 2 y 3 descritos anteriormente (y que usualmente son implementados por humanos, y en ocasiones no generan los resultados esperados). Un modelo Deep Learning toma simplemente los datos en bruto (como la señal de audio proveniente del dispositivo de grabación), y de forma autónoma (es decir sin intervención humana) determina por sí solo las características más relevantes de la señal y aprende a identificar los patrones que permiten entender lo que la persona al otro lado de la línea está diciendo.
El ejemplo anterior quiere decir que en Deep Learning se reduce la intervención humana al mínimo, pues una vez programado, el modelo estará en capacidad de representar adecuadamente los datos de entrada (la voz humana) y de aprender a interpretarlos con un propósito particular (en este caso ordenar una pizza).
Es por ello que, en la actualidad, el Deep Learning es la tecnología de Inteligencia Artificial que ha tenido un crecimiento más vertiginoso y que genera la mayor cantidad de expectativa, pues, además de reducir la intervención humana, puede ser aplicada en una gran cantidad de ámbitos (reconocimiento de voz humana, visión por computador, medicina, finanzas, etc.).
Veamos ahora porqué esta tecnología ha recibido la denominación de Deep Learning.
¿Por qué Deep?
Las Redes Neuronales y las Neuronas Artificiales son los elementos fundamentales del Deep Learning. Fueron conceptos creados en 1943, es decir !hace más de 70 años!
En particular, la neurona es el elemento fundamental de cualquier modelo Deep Learning (así como los átomos son el elemento constituyente de la materia, o las células dan origen a tejidos, órganos y seres vivientes). Dicha neurona es una unidad capaz de realizar operaciones matemáticas sobre unos datos de entrada para obtener unos datos de salida.
Veamos un ejemplo sencillo. Supongamos que queremos desarrollar un modelo computacional capaz de determinar si un número es par. Llamemos x al número que ingresa al sistema, y y a la categoría correspondiente (y=1 si el número es par o y=0 si no lo es). Entonces, un simple algoritmo matemático que permitiría resolver este problema sería el siguiente:
- Multiplicar x por 1/2
- Si (1/2)x es un número entero, entonces y=1 (lo que significa que x es un número par)
- Si (1/2)x es un número no entero (es decir que tiene decimales), entonces y=0 (lo que significa que x es impar)
Veamos si funciona el algoritmo. Si x=100, entonces:
- (1/2)x = (1/2)100 = 50
- ¿Es 50 un número entero? La respuesta es sí, y por tanto y=1 y x=100 es un número par.
¿Y si x=133? Aplicando la misma lógica del ejemplo anterior, encontramos que (1/2)x = (1/2)133 = 66.5 que es un número no entero y por tanto y=0, lo cual quiere decir que x=133 es un número impar.
¡Y voilà, tenemos nuestro primer clasificador!!!
Claro, el ejemplo anterior es más de tipo conceptual, pero no es muy útil en el mundo real, pues determinar si un número es par o no no resulta muy complejo ni interesante. Sin embargo este ejemplo nos permite entender el concepto de neurona; en este caso la neurona usada realiza esencialmente dos operaciones matemáticas: multiplicación del dato de entrada por un coeficiente (en este caso 1/2) y comparación para determinar si el número resultante es entero o no entero. La salida de este comparador es una de dos posibles categorías: 1 si x es múltiplo entero de 2, o 0 si no lo es.
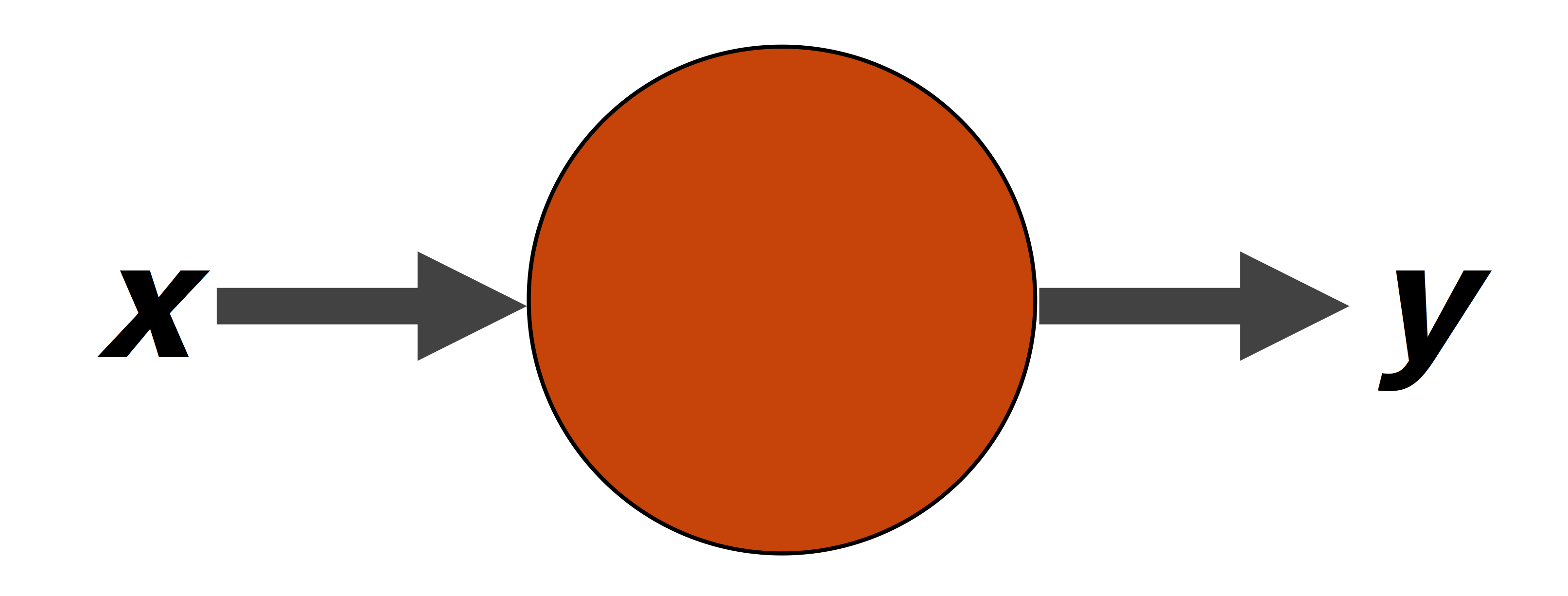
Así que podemos ahora definir de forma más precisa una neurona como una unidad que a través de funciones matemáticas (multiplicación por coeficientes y comparación) obtiene una representación de los datos de entrada x en términos de los datos de salida y. Dicha neurona se puede representar gráficamente como se muestra a continuación:
¿Y qué pasa si en lugar de determinar si un número es par o no, queremos que el modelo sea capaz de entender la voz humana o de conducir un automóvil de forma autónoma o de detectar una enfermedad sin la intervención humana? Pues es evidente que una simple neurona no podrá lograrlo.
Sin embargo, cuando se combinan múltiples neuronas se obtiene lo que se conoce como una red neuronal, capaz de realizar tareas mucho más complejas que el simple ejemplo visto anteriormente. Cuando se interconectan varias capas conformadas cada una de ellas por múltiples neuronas se pueden desarrollar modelos capaces de lograr niveles de desempeño similares e incluso superiores a los de los seres humanos. Esta interconexión de múltiples capas se llama red neuronal profunda y de allí el término Deep. Un ejemplo de una de estas Redes Neuronales se muestra abajo:
Veamos ahora a qué hace referencia el término Learning.
¿Por qué Learning?
Volvamos al ejemplo presentado anteriormente. Uno de los elementos centrales de ese modelo fue la multiplicación por un coeficiente, pero es importante observar que dicho coeficiente no fue escogido de forma arbitraria, pues precisamente su valor de 1/2 nos permite determinar si x es o no un número par.
¿Y cómo lograr que un computador encuentre de forma autónoma, sin nuestra ayuda, este coeficiente? Es allí donde aparece el concepto de aprendizaje (learning): en el caso de una red neuronal, el aprendizaje consiste en un algoritmo computacional que determina los valores más adecuados de los coeficientes para cada una de las neuronas que hace parte de la red. Esto se conoce como el entrenamiento del modelo, y permite que de forma iterativa (es decir, progresivamente) el sistema calcule los coeficientes que permiten representar correctamente los datos de entrada x en términos de los datos de salida y esperados.
Así por ejemplo, en un vehículo autónomo se usa un modelo Deep Learning que usa como entrada miles (e incluso millones) de imágenes provenientes de la cámara del vehículo en movimiento, y que de forma autónoma aprende (es decir calcula) múltiples coeficientes que permiten determinar el contenido de la escena (otros vehículos, señales de tránsito, semáforos, peatones, etc.) y así lograr que el automóvil se desplace sin intervención humana.
Por tanto, combinando los conceptos Deep y Learning podemos decir que un modelo Deep Learning es un sistema computacional que durante su proceso de entrenamiento aprende de forma autónoma una gran cantidad de coeficientes, lo que permite encontrar una representación de los datos de entrada x (que pueden ser imágenes, audio, conversaciones, secuencias de video, o simplemente cantidades numéricas) en términos de los datos de salida y (que puede ser la ruta a seguir por el vehículo, o las palabras pronunciada por una persona, o el resultado de un diagnóstico, etc.).
Sin embargo es importante recordar que para lograr desarrollar este tipo de sistemas, se requieren muchos datos de entrenamiento (del orden de miles o millones) y una elevada capacidad de cómputo. Es por ello que sólo hasta hace algunos años esta tecnología ha alcanzado el crecimiento esperado.
Veamos brevemente la evolución del Deep Learning para entender este crecimiento acelerado.
Deep learning: su evolución
La Inteligencia Artificial no es una idea nueva, pues es un término que se viene usando desde finales de la segunda guerra mundial.
A pesar de no ser un tema nuevo, sólo durante los últimos años (desde aproximadamente el 2012), es cuando realmente se han empezado a cristalizar muchas de las ideas y aplicaciones de la inteligencia artificial planteadas décadas atrás. Este crecimiento del Deep Learning se debe principalmente a dos razones: el incremento en la cantidad de datos disponibles y el incremento de la capacidad computacional.
Es evidente que día a día los dispositivos móviles tienen un uso más extendido, y empresas como Google, Microsoft y Facebook (entre otras) han sacado provecho de este fenómeno. La cantidad de datos, imágenes y sonidos que se almacena en sus servidores es inmensa (como lo muestra la figura de abajo) y esta gran cantidad de información disponible ha sido aprovechada por estas empresas para desarrollar modelos Deep Learning capaces de interpretar estos datos.
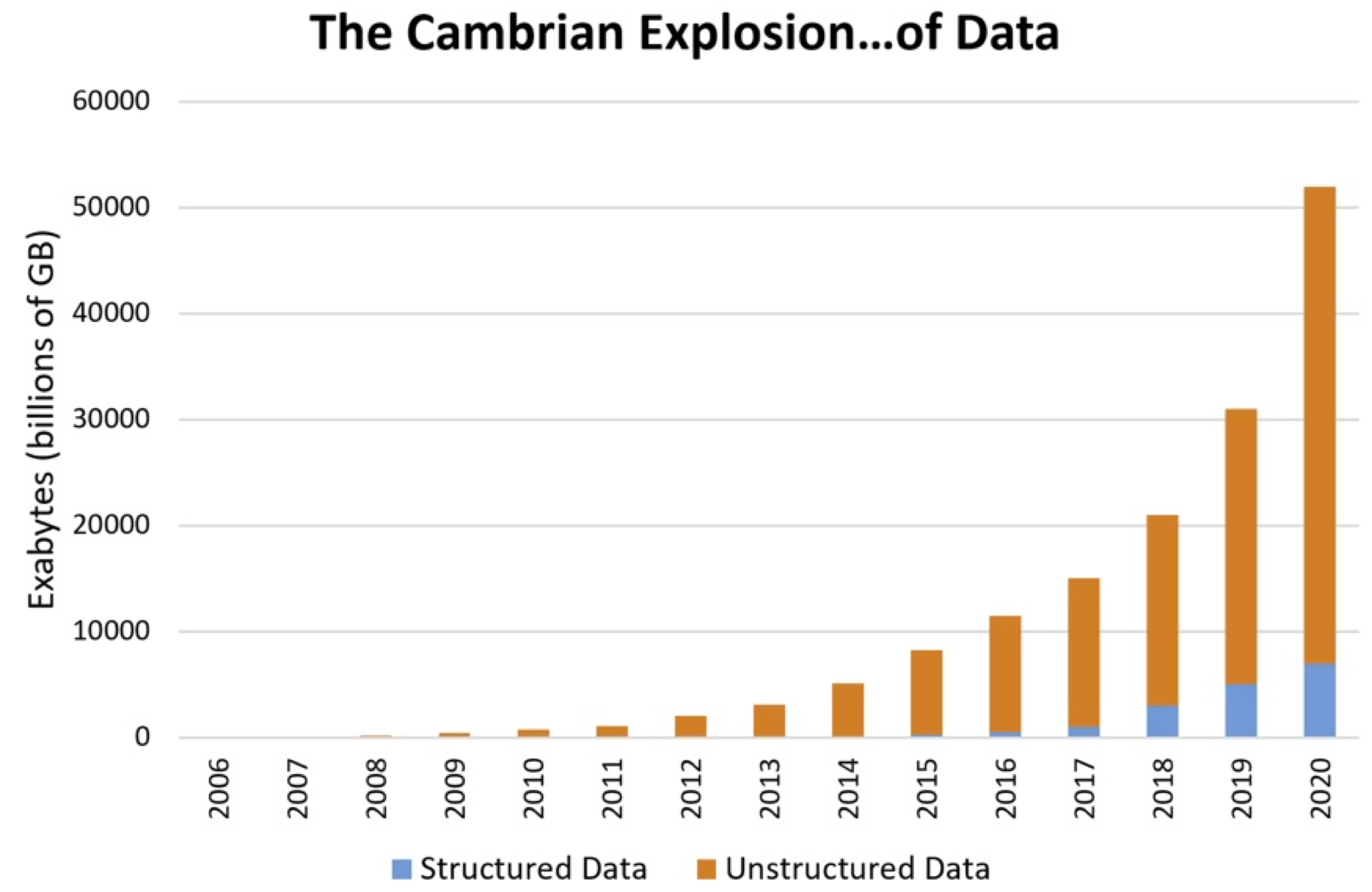
El segundo factor importante en el crecimiento del Deep Learning ha sido el incremento en la capacidad de cómputo y de almacenamiento, que fue uno de los principales cuellos de botella que impidió el crecimiento de la inteligencia artificial en años anteriores. Si bien la tecnología actual aún no ha llegado a tener la capacidad de procesamiento del cerebro humano, es evidente que en los últimos años los computadores han alcanzado niveles insospechados, pasando de aquellos con las tradicionales CPU (unidades central de procesamiento), a aquellos con GPU (unidades de procesamiento gráfico) mucho más potentes, y recientemente a las TPU (unidades de procesamiento de tensores), aún más potentes que las GPU, desarrolladas por Google especificamente para aplicaciones Deep Learning.

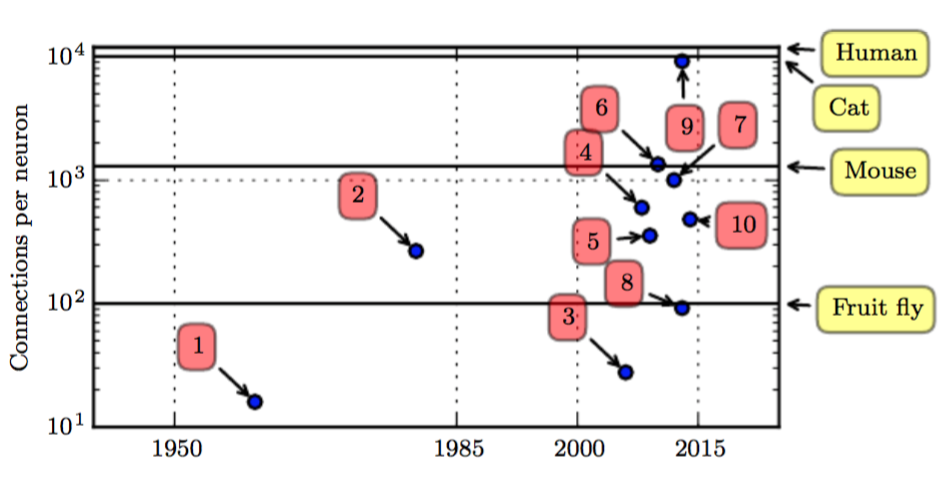
De hecho, como lo muestra la figura de abajo, en la actualidad (2018) los modelos Deep Learning usados tienen un número de conexiones entre sus neuronas superior a la cantidad de conexiones neuronales de un gato y ligeramente inferior a aquellas que, se supone, poseemos los seres humanos. Lo anterior quiere decir que pasarán pocos años para que los computadores logren tener capacidades similares a las del cerebro humano:
Antes de culminar, veamos algunos ejemplos de aplicaciones reales que demuestran el potencial del Machine y el Deep Learning.
Algunos ejemplos del Deep Learning
Restauración de pixeles
En muchas películas de Hollywood hemos visto como por ejemplo después de un robo las imágenes de las cámaras de seguridad son reconstruidas, permitiendo de esta forma identificar a los asaltantes.
En la actualidad se han desarrollado modelos Deep Learning capaces de realizar esta tarea, y en la imagen de abajo vemos un ejemplo: la primera columna corresponde a las imágenes de baja resolución introducidas al modelo, en la tercera columna se encuentran las imágenes de referencia, mientras que en la columna de la mitad se encuentran las imágenes generadas por el modelo. Se puede observar la gran similitud existente entre las imágenes reconstruidas por el modelo (columna 2) y las imágenes reales (columna 3).
En este ejemplo los autores de este modelo para restauración de pixeles usan una arquitectura especial de *Deep Learning *conocida como Redes Convolucionales.
Google Duplex
En mayo de 2018 Google desarrolló un modelo Deep Learning capaz de sostener una conversación inteligente con una persona al otro lado de la línea telefónica. Lo más impresionante es que el ser humano, del otro lado de la línea, en ningún momento se dio cuenta de que estaba conversando con un computador. Este sistema usa una arquitectura conocida como Redes Neuronales Recurrentes
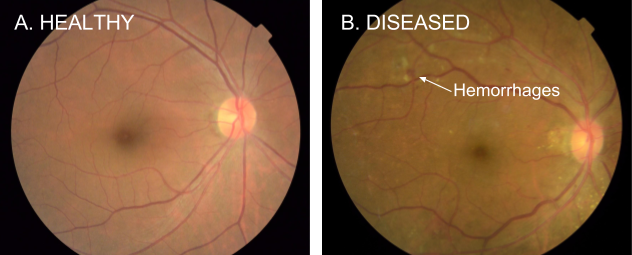
Detección de enfermedades
Se han desarrollado también sistemas Deep Learning para el diagnóstico de enfermedades como la retinopatía diabética, una de las principales causas de ceguera en personas con diabetes. El sistema desarrollado hace uso de redes convolucionales y tiene un desempeño (en términos de precisión del diagnóstico) ligeramente mejor al logrado por oftalmólogos expertos:
Análisis de secuencias de video
En redes sociales, como por ejemplo Facebook, hemos visto cómo al publicar una foto el sistema reconoce automáticamente los rostros e incluso sugiere los nombres de nuestros amigos para agregar las etiquetas. Los desarrolladores de Facebook han ido más allá, y han creado DensePose, un sistema capaz de determinar de forma automática la posición del cuerpo y la actividad que están desarrollando los sujetos en un video.
De igual forma, la empresa DeepGlint ha desarrollado sistemas de vigilancia que permiten detectar actitudes sospechosas de sujetos a partir de capturas de secuencias de video en cámaras de seguridad.
Ambos sistemas hacen uso de Redes Convolucionales.
Traductores
Todos hemos usado el traductor de Google. Este es precisamente un ejemplo de un modelo Deep Learning llamado Neural machine translation system que usa una arquitectura conocida como Red LSTM. Este sistema ha incrementado la precisión en el proceso de traducción en más de un 60% con respecto a lo que se había desarrollado hasta el momento de su creación (2016).
Recientemente se ha desarrollado una nueva arquitectura, conocida como Red Transformer, que ha mejorado sustanciablemente la calidad de estas traducciones y que es la que actualmente implemente Google en su traductor.
Vehículos autónomos
Esta es tal vez una de las aplicaciones más llamativas del Deep Learning. Hace uso de redes convolucionales y en particular de un algoritmo conocido como YOLO (You Only Look Once).
AlphaGo
Una de las pruebas de fuego de la inteligencia artificial es superar el desempeño de los seres humanos en diferentes actividades. AlphaGo es un ejemplo de esto, pues consiste en un modelo Deep Learning que fue capaz de vencer al campeón mundial de Go (un juego inventando en China hace más de 2500 años, y mucho más complejo que el Ajedrez). En este caso la tecnología usa un enfoque conocido como Aprendizaje Reforzado que permite al computador aprender de la experiencia.
Conclusión
En este post discutimos varias diferencias y conceptos fundamentales de la Inteligencia Artificial, el Machine Learning y el Deep Learning. En particular es importante recordar estas ideas:
- El Deep Learning es un área específica de la inteligencia artificial y del aprendizaje de máquina, que ha tenido un gran auge durante los últimos años.
- Una neurona es uno de los elementos esenciales de los modelos Deep Learning, y se encarga de realizar operaciones matemáticas que permiten transformar una serie de datos de entrada en unos datos de salida.
- La neurona está conformada por coeficientes (o parámetros) y operaciones matemáticas. Dichos coeficientes se calculan de forma autónoma a través de un proceso conocido como entrenamiento, que depende tanto de los datos de entrada como de los de salida.
- La capacidad de una sola neurona es muy limitada, pero al interconectar varias de ellas en una red neuronal de forma adecuada se pueden lograr sistemas inteligentes capaces de interpretar la voz, imágenes, e incluso de tomar “decisiones” de manera autónoma.
- El Deep learning es el resultado de interconectar de forma adecuada miles de neuronas. Para lograr que el modelo ejecute una tarea específica, se requiere un proceso de entrenamiento en donde de manera progresiva los coeficientes individuales de cada neurona se aprenden (se calculan) hasta lograr el resultado deseado.
- Para desarrollar modelos Deep Learning que alcancen o superen el desempeño del ser humano en tareas específicas, se requiere una gran cantidad de datos de entrenamiento y una poderosa capacidad de cómputo para el proceso de aprendizaje.
- Además de las redes neuronales, existen arquitecturas como las redes convolucionales o las redes neuronales recurrentes, que permiten el análisis de imágenes, videos y audio.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: