Tutorial: predicción de acciones en la bolsa con Python y Keras (Redes LSTM)
En este quinto post de la serie “Redes Neuronales Recurrentes” veremos cómo implementar, paso a paso, una Red LSTM que permita predecir el valor que tendrá en el futuro una acción en la bolsa de valores.
En particular lo que haremos será visualizar el comportamiento histórico de la acción de Apple en los últimos años, y vamos a diseñar y entrenar una en Python y Keras, la cual tomará estos datos históricos y permitirá generar una predicción.
Al final del artículo se encuentra el enlace para descargar el set de datos y el código fuente.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Introducción
Recordemos que una Red LSTM es un tipo de Red Neuronal Recurrente que permite analizar secuencias (como texto, conversaciones, o precisamente el comportamiento histórico de una acción en la bolsa) y que además tiene una memoria de largo plazo. Te invito a ver el anterior post de esta serie si quieres conocer en detalle cómo funciona una Red LSTM.
En este tutorial veremos en detalle cómo implementar una Red LSTM en Python, usando específicamente la librería Keras. El tutorial está divido en cinco partes: el set de datos, el pre-procesamiento de estos datos, la implementación del modelo, el entrenamiento y la predicción del valor de la acción.
Comencemos entonces viendo los detalles del set de datos.
El set de datos
Este set de dato contiene el registro histórico del comportamiento de la acción de Apple entre enero de 2006 y diciembre de 2017.
Este set lo podemos leer fácilmente usando la librería Pandas de Python:
import numpy as np
np.random.seed(4)
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('AAPL_2006-01-01_to_2018-01-01.csv', index_col='Date', parse_dates=['Date'])
dataset.head()
Al visualizar el contenido de este dataset podemos observar que cada registro contiene la información de los valores más altos y más bajos alcanzados por la acción, así como los valores de apertura y cierre y el volumen de las transacciones:
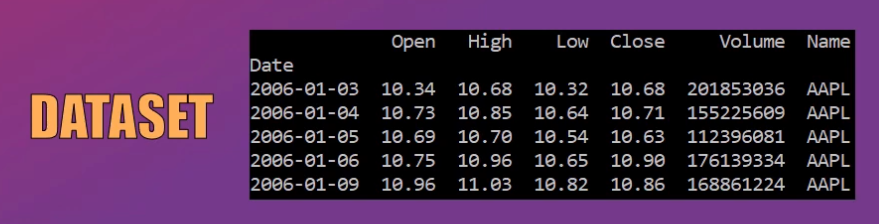
En este tutorial entrenaremos la Red LSTM usando únicamente el valor más alto de la acción (columna High en el set de datos).
Pre-procesamiento de los datos
Creación de los sets de entrenamiento y validación
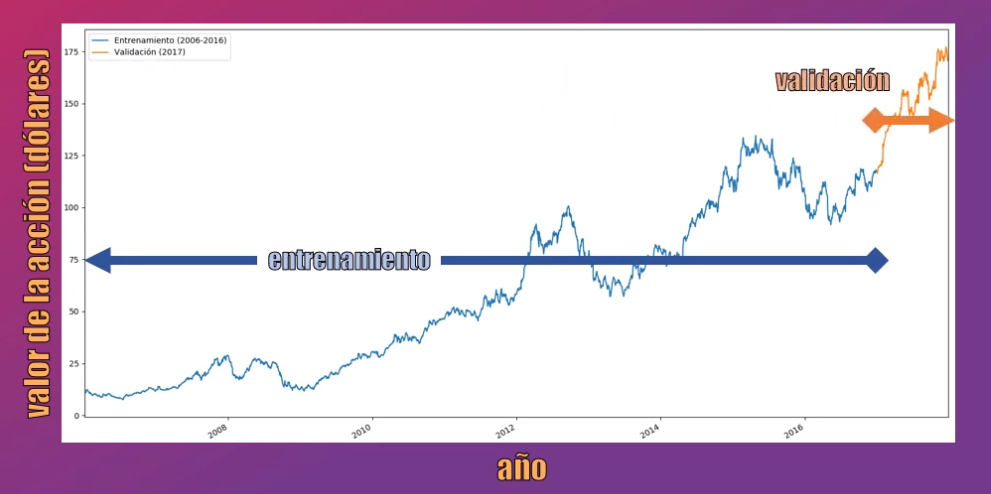
Para el entrenamiento de la Red LSTM usaremos los datos entre Enero de 2006 y Diciembre de 2016, mientras que para la validación y la predicción usaremos todos los registros del año 2017.
La idea es que la Red LSTM aprenda a predecir los valores máximos de la acción para el año 2017, usando el comportamiento en años anteriores:
Teniendo esto en cuenta, podemos crear los sets de entrenamiento y validación usando la función iloc de Pandas:
set_entrenamiento = dataset[:'2016'].iloc[:,1:2]
set_validacion = dataset['2017':].iloc[:,1:2]
en donde .iloc[:,1:2] nos permite seleccionar únicamente la columna High del dataset.
Normalización de los datos
Si analizamos el comportamiento de la acción de Apple en los últimos años veremos que tiene una tendencia creciente:
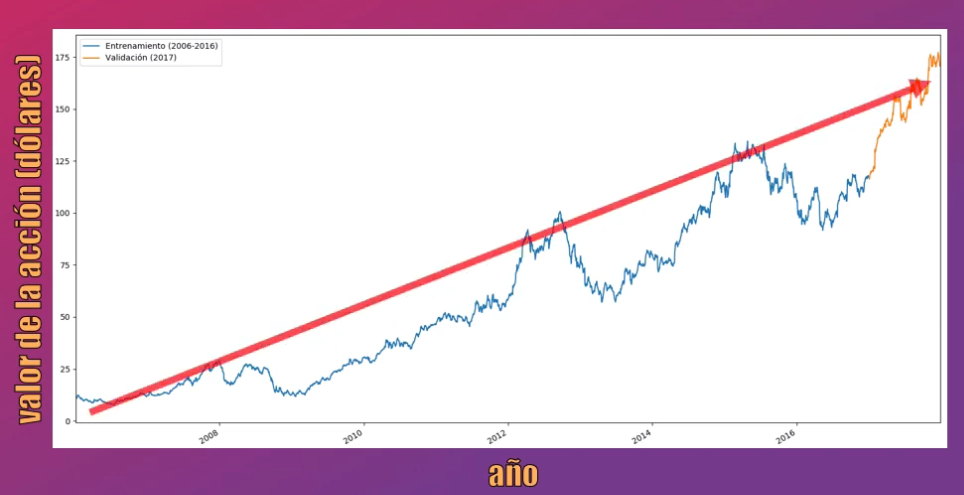
Para que la Red LSTM pueda ser entrenada que los valores de la acción se encuentran en un rango definido. Así que vamos a usar la librería Scikit-learn para normalizar estos valores en el rango de 0 a 1, usando la función MinMaxScaler:
sc = MinMaxScaler(feature_range=(0,1))
set_entrenamiento_escalado = sc.fit_transform(set_entrenamiento)
Y una vez hecho el entrenamiento, al momento de la predicción, realizaremos la transformación inversa para obtener los valores en la escala real.
Ajuste de los sets de entrenamiento y validación
Para entrenar la Red LSTM tomaremos bloques de 60 datos consecutivos, y la idea es que cada uno de estos permita predecir el siguiente valor:
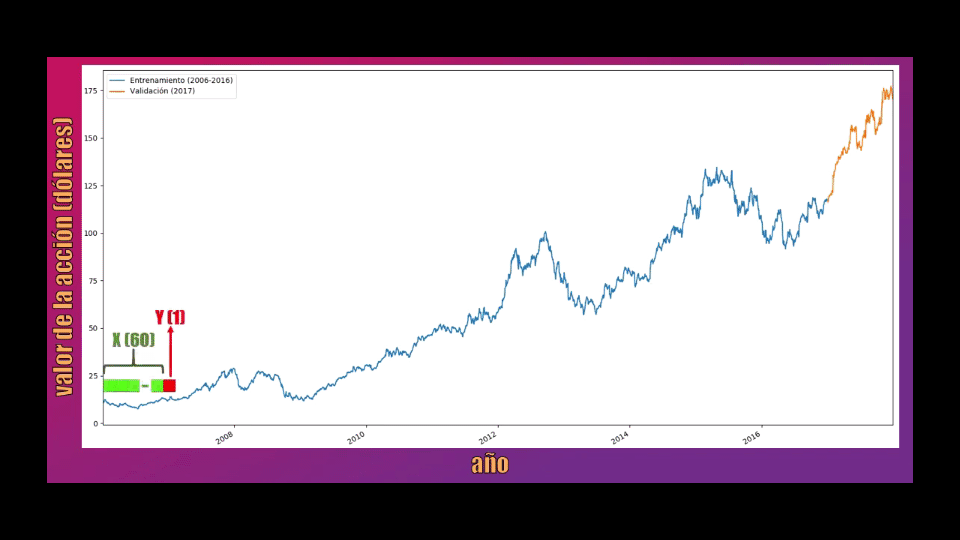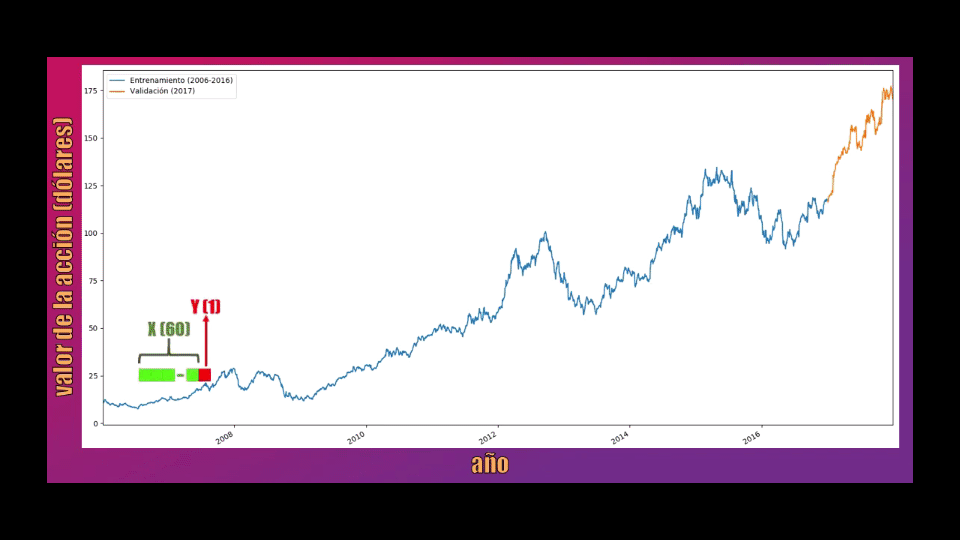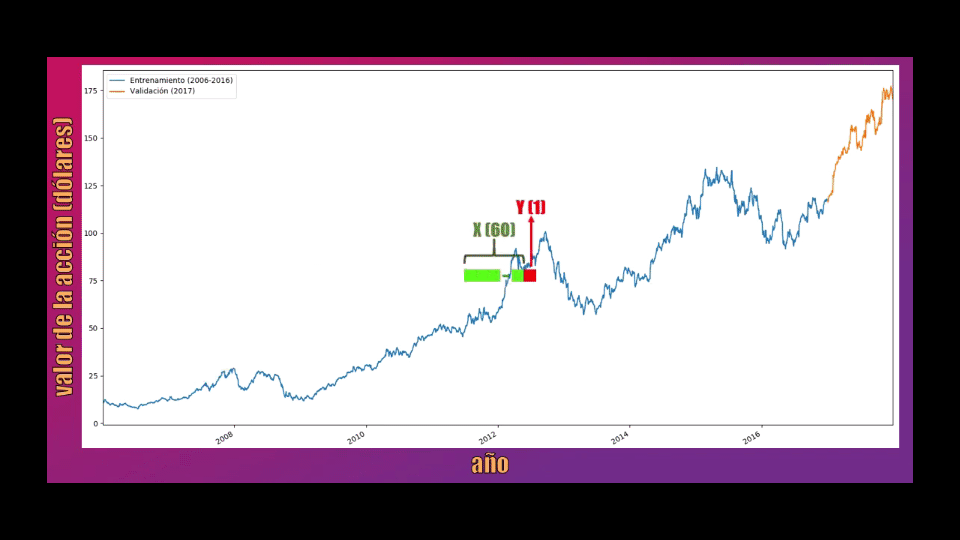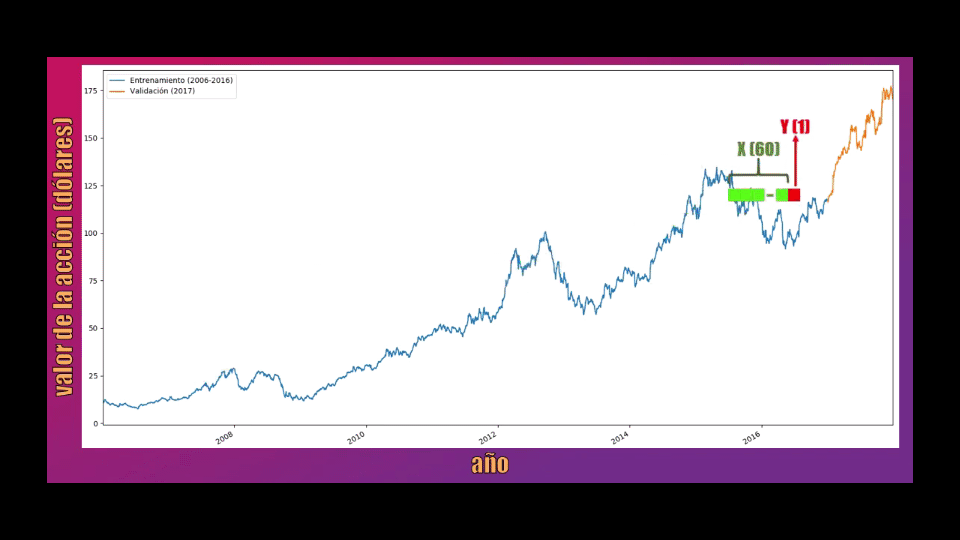
Los bloques de 60 datos serán almacenados en la variable X, mientras que el dato que se debe predecir (el dato 61 dentro de cada secuencia) se almacenará en la variable Y y será usado como la salida de la Red LSTM:
time_step = 60
X_train = []
Y_train = []
m = len(set_entrenamiento_escalado)
for i in range(time_step,m):
# X: bloques de "time_step" datos: 0-time_step, 1-time_step+1, 2-time_step+2, etc
X_train.append(set_entrenamiento_escalado[i-time_step:i,0])
# Y: el siguiente dato
Y_train.append(set_entrenamiento_escalado[i,0])
X_train, Y_train = np.array(X_train), np.array(Y_train)
En el código anterior usamos el bloque for para iterativamente dividir el set de entrenamiento en bloques de 60 datos y almacenar los bloques correspondientes en diferentes posiciones de las variables X_train y Y_train.
Antes de crear la Red LSTM debemos reajustar los sets que acabamos de obtener, para indicar que cada ejemplo de entrenamiento a la entrada del modelo será un vector de 60x1. Para esto usamos la función reshape de Numpy:
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
Para el caso de cada una de las salidas (almacenadas en Y_train) debemos simplemente especificar que su tamaño será igual a 1, que corresponde al único valor predicho por la red.
Creación y entrenamiento de la Red LSTM
Ahora sí procedemos a crear y entrenar nuestro modelo.
Implementación del modelo en Keras
Para implementar el modelo debemos primero importar las librerías de Keras correspondientes a las Redes LSTM. Usaremos el módulo Sequential para crear el contenedor, al cual iremos añadiendo la Red LSTM (usando el módulo LSTM) y la capa de salida (usando el módulo Dense):
from keras.models import Sequential
from keras.layers import LSTM, Dense
Para crear la red debemos primero definir el tamaño de los datos de entrada y del dato de salida, así como el número total de neuronas (50):
dim_entrada = (X_train.shape[1],1)
dim_salida = 1
na = 50
Como lo mencionamos anteriormente, para crear la Red LSTM debemos primero crear un contenedor usando el módulo Sequential:
modelo = Sequential()
Ahora añadimos la Red LSTM usando la función add, especificando el número de neuronas a usar (parámetro units) y el tamaño de cada dato de entrada (parámetro input_shape):
modelo.add(LSTM(units=na, input_shape=dim_entrada))
Para la capa de salida usamos la función Dense y especificamos que el dato de salida tendrá un tamaño igual a 1 (parámetro units):
modelo.add(Dense(units=dim_salida))
Ahora debemos compilar el modelo, definiendo así la función de error (parámetro loss) así como el método que se usará para minimizarla (parámetro optimizer):
modelo.compile(optimizer='rmsprop', loss='mse')
El optimizador seleccionado (rmsprop) funciona de manera similar al algoritmo del Gradiente Descendente, mientras que la función de error es el error cuadrático medio, el cual explico en detalle en el artículo acerca de la Regresión Lineal.
El entrenamiento se implementa de forma sencilla usando la función fit. En este caso usaremos un total de 20 iteraciones (parámetro epochs) y presentaremos a la Red LSTM lotes de 32 datos (parámetro batch_size):
modelo.fit(X_train,Y_train,epochs=20,batch_size=32)
Predicción del valor de la acción
Con el modelo entrenado, veamos qué tan bien predice esta Red LSTM los valores de la acción de Apple.
Inicialmente debemos preparar el set de validación, normalizando inicialmente los datos, en el rango de 0 a 1, para lo cual usamos la transformación implementada anteriormente sobre el set de entrenamiento:
x_test = set_validacion.values
x_test = sc.transform(x_test)
Recordemos que el modelo fue entrenado para tomar 60 y generar un dato como predicción. Así que debemos reorganizar el set de validación (x_test) para que tenga bloques de 60 datos:
X_test = []
for i in range(time_step,len(x_test)):
X_test.append(x_test[i-time_step:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
Y finalmente realizamos la predicción usando la función predict y aplicamos la normalización inversa de dicha predicción para que esté en la escala real de las acciones:
prediccion = modelo.predict(X_test)
prediccion = sc.inverse_transform(prediccion)
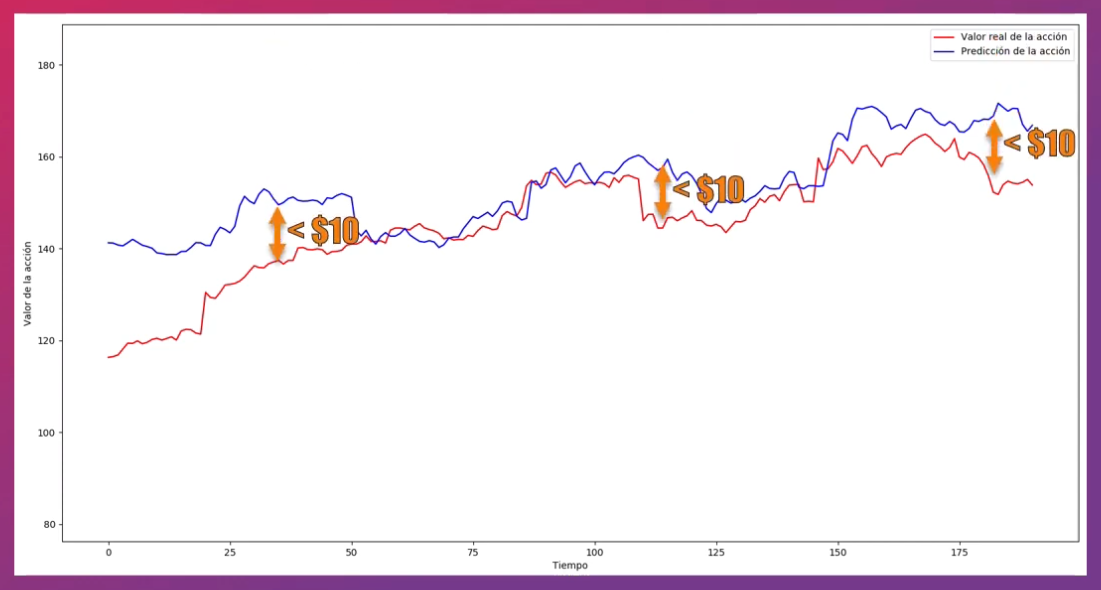
Al ejecutar este código vemos que la red logra predecir bastante bien los valores máximos de la acción de Apple, pues para la mayor parte de los datos predichos la diferencia es igual o menor a los 10 dólares con respecto al valor real:
Conclusión
Bien, en este post vimos cómo implementar de manera sencilla una Red LSTM capaz de predecir de forma bastante aproximada el comportamiento de una acción en la bolsa de valores.
Realmente es un modelo preliminar que puede ser mejorado, por ejemplo agregando más capas LSTM y/o modificando el número de neuronas en cada una de las capas.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario:
Set de datos y código fuente
En este enlace de Github podrás descargar el set de datos y el código fuente de este tutorial.