Tutorial TensorFlow 2.0 y Keras
En este segundo post de la serie “Tensorflow 2.0” veremos un completo tutorial sobre cómo instalar TensorFlow 2.0 y cómo usar esta librería en conjunto con Keras para implementar las tres principales arquitecturas del Deep Learning: las Redes Neuronales, las Redes Convolucionales y las Redes Recurrentes.
Al final del artículo se encuentra el enlace para descargar el set de datos y el código fuente.
¡Así que listo, comencemos!
Tabla de contenido
Video
Como siempre, en el canal de YouTube se encuentra el video de este post:
Instalación de TensorFlow 2.0 y de las librerías requeridas
Comencemos viendo cómo instalar la librería Tensorflow 2.0 y cómo poner a punto nuestro entorno Python para poder desarrollar modelos de Deep Learning.
A pesar de que el procedimiento que mostraré es para el sistema operativo Mac OS X, también funciona para Windows.
En primer lugar sugiero descargar la última distribución de Anaconda Python, que además de Python contiene otras librerías que desde luego resultarán útiles más adelante para desarrollar diferentes modelos de Deep Learning.
Aunque Anaconda Python cuenta con una interfaz gráfica que facilita la instalación de librerías, considero que es más sencillo el uso de la línea de comandos.
Así que, una vez instalado Anaconda Python, abriremos el Terminal de Mac (o la ventana de comandos en Windows) y crearemos un entorno virtual:
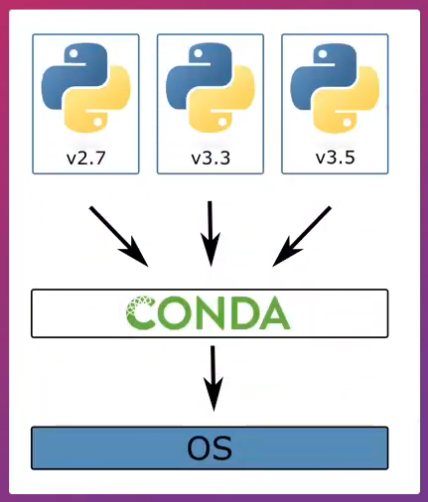
Un entorno virtual es simplemente un directorio que contiene una instalación de Python en particular y unas librerías asociadas. Esto permite tener, en un mismo computador, múltiples versiones de Python sin que haya conflicto entre unas y otras.
En el caso del Deep Learning esto resulta de utilidad, pues instalaremos Tensorflow y esta librería sólo está disponible para ciertas versiones de Python. Así evitaremos problemas durante la instalación o que la librería entre en conflicto con diferentes instalaciones de Python.
La creación del entorno virtual es sencilla, simplemente escribimos el comando conda create y el nombre que daremos al entorno virtual (en este caso tf2) y especificamos la versión de Python que queremos instalar. En este caso esta versión es la 3.7, para la cual viene compilada TensorFlow 2.0:
conda create --name tf2 python==3.7
Para hacer uso de este entorno virtual debemos activarlo. Para ello escribimos el comando conda activate seguido del nombre del entorno virtual:
conda activate tf2
A continuación instalamos la librería pip de Python, que permite de forma sencilla descargar e instalar las librerías requeridas.
Para ello simplemente escribimos conda install pip y seguimos las instrucciones en pantalla:
conda install pip
Ahora sí podemos instalar Tensorflow 2.0. Simplemente escribimos pip install –-upgrade tensorflow:
pip install --upgrade tensorflow
Para verificar la correcta instalación de la librería simplemente ejecutamos Python desde el terminal:
python
Al abrir esta sesión interactiva podemos verificar que en pantalla se imprime la versión instalada, que es precisamente la 3.7:
Python 3.7.0 (default, Jun 28 2018, 07:39:16)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
Ahora importamos tensorflow y verificamos que la versión instalada es precisamente la 2.0. Podemos verificar igualmente que la librería Keras ya viene por defecto incluida en esta versión de Tensorflow:
>>> import tensorflow as tf
>>> tf.__version__
'2.1.0'
>>> from tensorflow import keras
>>> keras.__version__
'2.2.4-tf'
Y listo, ya tenemos el entorno virtual instalado correctamente y con todas las librerías requeridas.
Ahora sí veamos como usar TensorFlow 2.0 y Keras, su librería de alto nivel por defecto, para implementar los tres principales modelos de Deep Learning: las Redes Neuronales, las Redes Convolucionales y las Redes Recurrentes.
Implementación de diferentes arquitecturas de Deep Learning con Tensorflow 2.0 y Keras
En esta parte del tutorial me enfocaré en el código requerido para implementar los tres tipos de arquitecturas mencionados anteriormente, pero no explicaré en detalle cómo es que funciona cada una de ellas ni tampoco detalles como la lectura y pre-procesamiento de los datos que se usarán en cada ejemplo. La explicación detallada de estos tres modelos la encontrarás en posts anteriores.
En general se deben llevar a cabo cuatro pasos para el desarrollo de cualquier modelo de Deep Learning en Tensorflow 2.0 y Keras:
- La creación del modelo, usando como punto de partida la función
Sequentialde Keras. - La compilación del modelo, en donde se definen la función de error y el optimizador que minimizará dicha función
- El entrenamiento mismo del modelo, y
- La predicción, que permite usar el modelo ya entrenado para procesar datos que no ha procesado previamente.
Veamos entonces cómo implementar estos cuatro pasos para cada una de las arquitecturas mencionadas anteriormente.
Redes Neuronales con Tensorflow 2.0 y Keras
En primer lugar veremos cómo implementar una Red Neuronal, capaz de clasificar imágenes correspondientes al set “Fashion MNIST”. Este set contiene 60,000 imágenes de entrenamiento y 10,000 de validación, todas en escala de gris, con un tamaño de 28x28 pixeles y correspondientes a una de 10 posibles categorías.
Crearemos una Red Neuronal con una capa de entrada, una capa oculta con 128 neuronas y función de activación ReLU y la capa de salida con 10 unidades (correspondientes a las 10 categorías) y función de activación softmax:
En primer lugar importamos la librería Keras, ya incluida en Tensorflow 2.0, y específicamente importamos los módulos Sequential, Flatten y Dense, con los que implementaremos la Red Neuronal:
import tensorflow as tf
tf.random.set_seed(4)
from tensorflow.keras import datasets, Sequential
from tensorflow.keras.layers import Flatten, Dense
en donde hemos fijado la semilla del generador aleatorio en un valor fijo (tf.random.set_seed(4)) para garantizar la reproducibilidad del entrenamiento.
Para crear el modelo usamos inicialmente la función Sequential de Keras. Esta función crea un contenedor, como una caja vacía, a la cual comenzaremos a agregar secuencialmente las diferentes capas del modelo:
modelo = Sequential()
Para la capa de entrada usaremos Flatten (para aplanar cada imagen y convertirla en un vector), especificando que el tamaño de cada dato es de 28x28. Después, agregamos la capa oculta (con 128 neuronas) y la capa de salida (con 10 neuronas), especificando las funciones de activación (ReLU y softmax, respectivamente). Observemos que cada componente se agrega al modelo de forma sencilla usando la función add:
modelo.add( Flatten(input_shape=(28,28)) )
modelo.add( Dense(128, activation = 'relu') )
modelo.add( Dense(10, activation = 'softmax') )
A continuación compilamos el modelo, lo que equivale a definir la función de error (loss='categorical_crossentropy'), el algoritmo que usaremos para minimizar dicha función (optimizer='adam') y la forma como mediremos el desempeño del modelo (metrics=['accuracy']). Recordemos que esta es la base del entrenamiento, pues al minimizar la función de error lo que hacemos es ajustar los coeficientes de cada neurona de la red para así lograr la mayor precisión al momento de clasificar los datos:
modelo.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ahora entrenamos el modelo, y para ello debemos presentar precisamente los datos de entrenamiento (correspondientes a 60,000 imágenes con sus correspondientes categorías).
Para ello usamos la función fit, en donde además de usar el set de entrenamiento, especificamos un total de 10 iteraciones:
modelo.fit(x_train, y_train, epochs=10, verbose=1)
Al finalizar podremos ver que se alcanza una precisión de aproximadamente el 91% con el set de entrenamiento.
Podemos además evaluar la precisión con el set de validación, usando la función evaluate. En este caso se alcanza una precisión cercana al 88%:
error, precision = modelo.evaluate(x_test, y_test, verbose=2)
print('\nPrecisión con el set de validación:', precision)
Finalmente podemos usar el modelo entrenado para realizar una predicción, que equivale a clasificar una (o más) imágenes que no hayan sido usadas durante el entrenamiento. En este caso usaremos algunas imágenes del set de validación:
predicciones = modelo.predict(x_test)
imagenes = [0, 11, 12]
plt.figure(figsize=(7,7))
for i,j in enumerate(imagenes):
plt.subplot(3,1,i+1)
graficar_imagen(j,predicciones,y_test,x_test)
plt.tight_layout()
plt.show()
Al realizar la predicción usando la función predict podemos observar que el modelo no tiene un comportamiento ideal, pues algunas de las imágenes fueron clasificadas incorrectamente:

Redes Convolucionales con Tensorflow 2.0 y Keras
Veamos ahora cómo implementar una Red Convolucional.
En este ejemplo crearemos un modelo capaz de clasificar imágenes provenientes del set cifar10. Este set contiene 50,000 imágenes de entrenamiento y 10,000 de validación, todas ellas de 32x32 pixeles y a color, y correspondientes a una de 10 posibles categorías.
El modelo tendrá una primera capa convolucional con 32 filtros de 3x3 cada uno, seguida de una capa max-pooling. Luego tendremos una segunda capa convolucional, pero esta vez con 64 filtros (también de 3x3 cada uno) seguidos por otra capa max-pooling. La tercera capa convolucional será idéntica a la anterior, y a la salida agregaremos una capa Flatten que permitirá “aplanar” el volumen resultante para así obtener un vector, que será llevado a una Red Neuronal con 64 neuronas. Todas las capas mencionadas anteriormente tendrán una activación tipo ReLU.
Para finalizar, tendremos la capa de clasificación, que contendrá 10 unidades (correspondientes a las 10 categorías existentes en el set de datos) y con función de activación softmax.
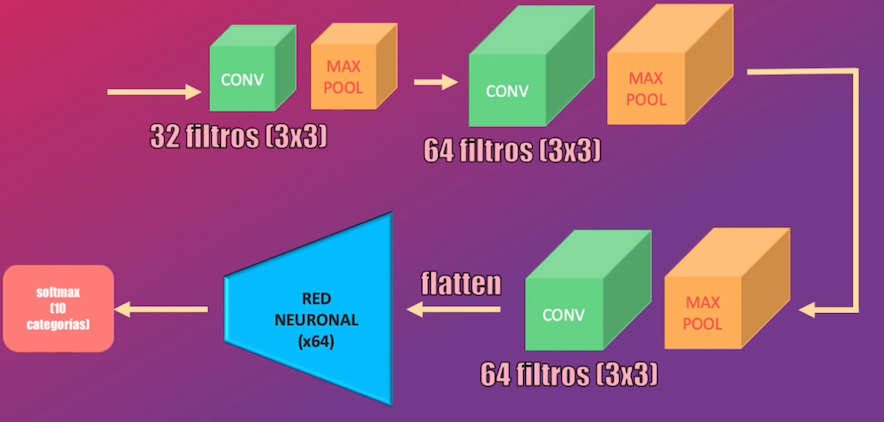
En este caso importaremos nuevamente los módulos Sequential, Flatten y Dense, y adicionalmente los módulos Conv2D y MaxPooling2D:
import tensorflow as tf
tf.random.set_seed(200)
from tensorflow.keras import datasets, Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D
Al igual que en el ejemplo anterior, para crear el modelo usaremos la función Sequential y para añadir las diferentes capas de la red convolucional usaremos la función Add. Las capas convolucionales y maxpooling se añaden usando las funciones Conv2D y MaxPooling2D de Keras, mientras que las capas Flatten y las neuronas de la capa intermedia y de salida se crean con la función Dense. Observa que la lógica de implementación del modelo es similar al caso de la Red Neuronal: de manera secuencial debemos ir añadiendo las diferentes capas de la Red Convolucional:
modelo = Sequential()
modelo.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
modelo.add(MaxPooling2D((2, 2)))
modelo.add(Conv2D(64, (3, 3), activation='relu'))
modelo.add(MaxPooling2D((2, 2)))
modelo.add(Conv2D(64, (3, 3), activation='relu'))
modelo.add(Flatten())
modelo.add(Dense(64, activation='relu'))
modelo.add(Dense(10, activation='softmax'))
La compilación del modelo es idéntica a la usada en el caso de la Red Neuronal. Usamos la función compile y en ella especificamos el optimizador, la función de error y la precisión como métrica de desempeño:
modelo.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Para el entrenamiento usamos nuevamente fit, y en este caso también usaremos 10 iteraciones:
modelo.fit(x_train, y_train, epochs=10, verbose=1)
Al final de este entrenamiento podremos ver que se alcanza una precisión del 79%, mientras que al evaluar el modelo con el set de validación se alcanza una precisión del 70%:
error, precision = modelo.evaluate(x_test, y_test, verbose=2)
print('\nPrecisión con el set de validación:', precision)
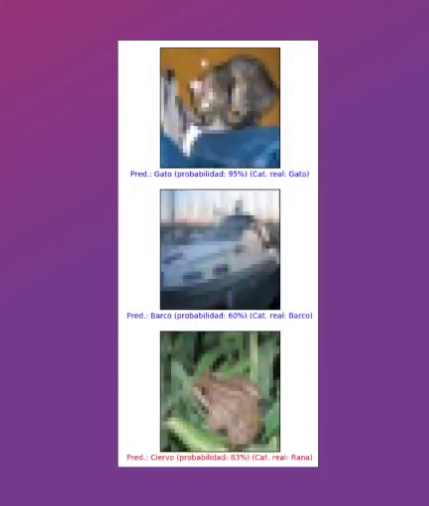
Finalmente, podemos realizar la predicción con algunas imágenes del set de validación:
predicciones = modelo.predict(x_test)
imagenes = [0, 2, 4]
plt.figure(figsize=(7,7))
for i,j in enumerate(imagenes):
plt.subplot(3,1,i+1)
graficar_imagen(j,predicciones,y_test,x_test)
plt.tight_layout()
plt.show()
Observamos nuevamente que este comportamiento no es ideal y que algunas de las imágenes son clasificadas incorrectamente:
Redes Recurrentes LSTM con Tensorflow 2.0 y Keras
En este último ejemplo veremos cómo implementar una Red Recurrente, en particular una Red LSTM, capaz de escribir como Miguel de Cervantes Saavedra.
La idea es la siguiente: para entrenar el modelo usaremos el texto completo del libro Don Quijote (almacenado en formato .txt).
El objetivo es que la red tome un caracter de entrada y aprenda a predecir el siguiente caracter en la secuencia, generando así un texto que se asemeje al estilo de Miguel de Cervantes Saavedra:

Así, cada ejemplo de entrenamiento (x_train, y_train) será simplemente un par de caracteres consecutivos dentro del texto de don Quijote.
Adicional a los módulos Sequential y Dense usados en los dos ejemplos anteriores, en este caso usaremos LSTM, TimeDistributed y Activation:
import tensorflow as tf
tf.random.set_seed(9)
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, TimeDistributed, Activation
Así como en los ejemplos anteriores, la implementación del modelo inicia creando el contenedor con la función Sequential. Posteriormente agregaremos la capa LSTM, que contendrá en total 1024 neuronas y en donde especificamos además que cada dato de entrada tendrá un tamaño de 92 (que corresponde precisamente al tamaño del diccionario: en total en el libro de Don Quijote hay 92 diferentes caracteres):
modelo = Sequential()
modelo.add(LSTM(1024, input_shape=(None, 92), return_sequences=True))
Después usamos la función “TimeDistributed” para que cada carácter generado por la capa LSTM sea representado como un vector de 92 elementos, y finalmente llevamos este resultado a una capa “softmax”. Esta salida es un vector de 92 elementos e indica una distribución de probabilidad: la posición con la probabilidad más alta corresponde al carácter generado por la red:
modelo.add(TimeDistributed(Dense(92)))
modelo.add(Activation('softmax'))
La compilación del modelo es muy similar a la de los dos ejemplos anteriores: usaremos Adam como método de optimización y la entropía cruzada como función de error. Sin embargo en este caso no definiremos ninguna métrica de desempeño, pues no estamos desarrollando un clasificador:
modelo.compile(loss="categorical_crossentropy", optimizer="adam")
Para el entrenamiento usaremos los sets creados anteriormente pero los presentaremos en bloques de 64 caracteres y realizaremos un total de 20 iteraciones de entrenamiento:
modelo.fit(x_train,y_train, batch_size=64, epochs=20, verbose=1)
Finalmente, para la predicción usaremos de nuevo el método predict. El primer carácter a predecir será escogido aleatoriamente, mientras que para las demás predicciones usaremos como entrada al modelo la predicción anterior:
print(generar_texto(modelo, 500, 92, ix_to_char))
No entraremos en detalles acerca de la función generar_texto pero esta se puede encontrar en el repositorio GitHub que contiene el enlace al código fuente y a los sets de datos (el enlace se encuentra al final de este post).
La secuencia generada contiene 500 caracteres y podemos observar que el modelo lo hace bastante bien y logra generar un escrito con un estilo similar al usado por Miguel de Cervantes:
ver lo que de mi padre le había de ser con la muerte de la
muerte.
-Así es la verdad -respondió Sancho-, pero no me acuerdo delante de la
muerte de mi alma en la mano, y el más desatino que te ha de ser con la muerte de
la muerte, y que la primera se me ha de comer y de mi padre y de la mano
de mi alma de su casa, y el mismo del mundo es manera que el cura le había
de ser con la muerte de la mano, y la primera parte del castillo, y el
cura de la mano estaba en la cabeza y dijo:
-Por cierto, señ
Sets de datos y código fuente
En este enlace de Github podrás descargar los sets de datos y el código fuente de este tutorial.
Conclusión
Bien, en este post además de haber visto paso a paso cómo instalar TensorFlow, vimos ejemplos detallados de cómo implementar las Redes Neuronales, Convolucionales y Recurrentes LSTM usando esta librería en conjunto con Keras.
En particular vimos que resulta muy sencillo implementar un modelo de Deep Learning usando las funciones de la librería Keras, que viene incluida por defecto en Tensorflow 2. En todos los casos el procedimiento se puede resumir a 4 pasos: crear el modelo usando como base el método Sequential, posteriormente compilarlo (es decir definir la función de error y el optimizador), luego entrenarlo (con el méto fit) y finalmente realizar predicciones con el modelo ya entrenado (usando el método predict).
El hecho de usar Keras facilita este desarrollo, pues la lógica de implementación es la misma independientemente del tipo de arquitectura que queramos desarrollar (bien sea una Red Neuronal, una Convolucional o una Recurrente).
En el próximo post de esta serie veremos una herramienta muy útil ofrecida por Google, que se llama Google Colab, y que permite, haciendo uso precisamente de Tensorflow 2 y Keras, implementar y entrenar modelos en la nube haciendo uso de GPUs, lo que resulta conveniente cuando no contamos con computadores de escritorio con altas capacidades de procesamiento.
Te invito a ver también la introducción a Tensorflow 2.0, que es el primer post de esta serie.
Si tienes alguna duda de este artículo o tienes alguna sugerencia no dudes en contactarme diligenciando el siguiente formulario: